 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication-Driven AI Paradigm for Person Counting in Various Scenarios
Mar 24, 2023



Person counting is considered as a fundamental task in video surveillance. However, the scenario diversity in practical applications makes it difficult to exploit a single person counting model for general use. Consequently, engineers must preview the video stream and manually specify an appropriate person counting model based on the scenario of camera shot, which is time-consuming, especially for large-scale deployments. In this paper, we propose a person counting paradigm that utilizes a scenario classifier to automatically select a suitable person counting model for each captured frame. First, the input image is passed through the scenario classifier to obtain a scenario label, which is then used to allocate the frame to one of five fine-tuned models for person counting. Additionally, we present five augmentation datasets collected from different scenarios, including side-view, long-shot, top-view, customized and crowd, which are also integrated to form a scenario classification dataset containing 26323 samples. In our comparative experiments, the proposed paradigm achieves better balance than any single model on the integrated dataset, thus its generalization in various scenarios has been proved.
TAD: A Large-Scale Benchmark for Traffic Accidents Detection from Video Surveillance
Sep 26, 2022


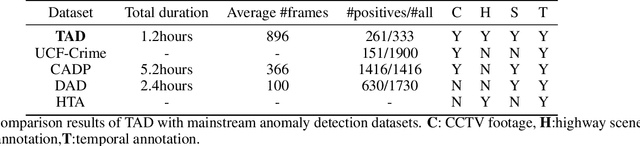
Automatic traffic accidents detection has appealed to the machine vision community due to its implications on the development of autonomous intelligent transportation systems (ITS) and importance to traffic safety. Most previous studies on efficient analysis and prediction of traffic accidents, however, have used small-scale datasets with limited coverage, which limits their effect and applicability. Existing datasets in traffic accidents are either small-scale, not from surveillance cameras, not open-sourced, or not built for freeway scenes. Since accidents happened in freeways tend to cause serious damage and are too fast to catch the spot. An open-sourced datasets targeting on freeway traffic accidents collected from surveillance cameras is in great need and of practical importance. In order to help the vision community address these shortcomings, we endeavor to collect video data of real traffic accidents that covered abundant scenes. After integration and annotation by various dimensions, a large-scale traffic accidents dataset named TAD is proposed in this work. Various experiments on image classification, object detection, and video classification tasks, using public mainstream vision algorithms or frameworks are conducted in this work to demonstrate performance of different methods. The proposed dataset together with the experimental results are presented as a new benchmark to improve computer vision research, especially in ITS.
Small Obstacle Avoidance Based on RGB-D Semantic Segmentation
Aug 30, 2019
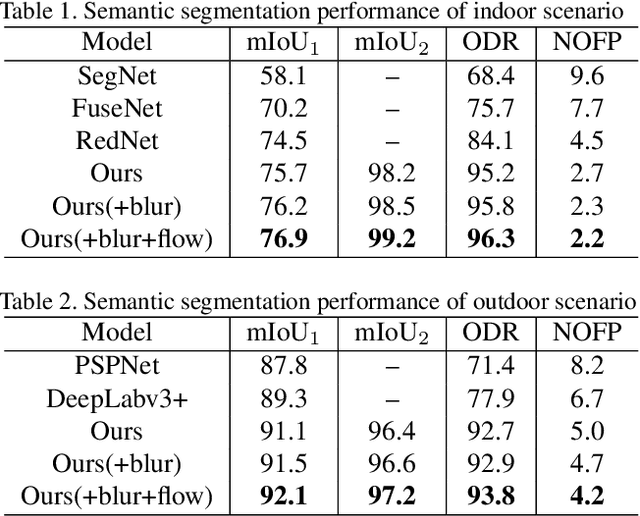
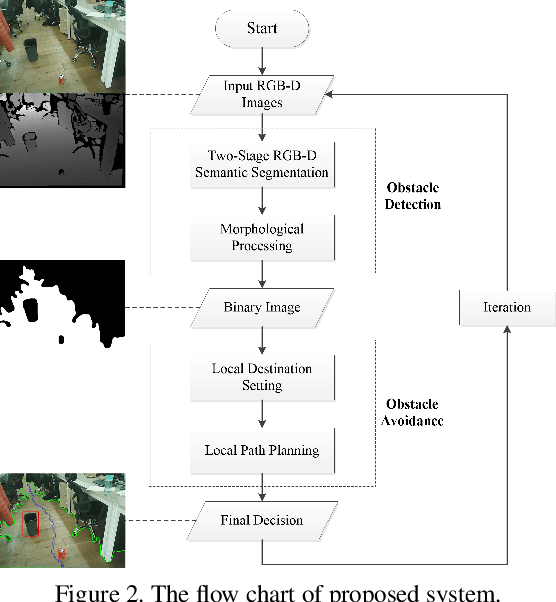
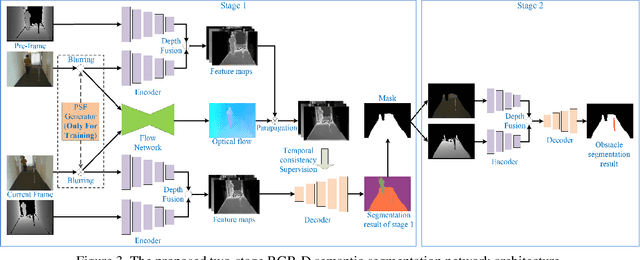
This paper presents a novel obstacle avoidance system for road robots equipped with RGB-D sensor that captures scenes of its way forward. The purpose of the system is to have road robots move around autonomously and constantly without any collision even with small obstacles, which are often missed by existing solutions. For each input RGB-D image, the system uses a new two-stage semantic segmentation network followed by the morphological processing to generate the accurate semantic map containing road and obstacles. Based on the map, the local path planning is applied to avoid possible collision. Additionally, optical flow supervision and motion blurring augmented training scheme is applied to improve temporal consistency between adjacent frames and overcome the disturbance caused by camera shake. Various experiments are conducted to show that the proposed architecture obtains high performance both in indoor and outdoor scenarios.
Falls Prediction Based on Body Keypoints and Seq2Seq Architecture
Aug 30, 2019
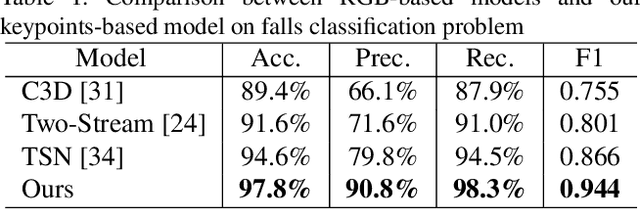
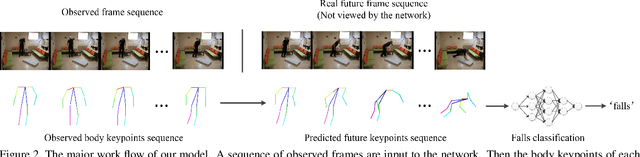
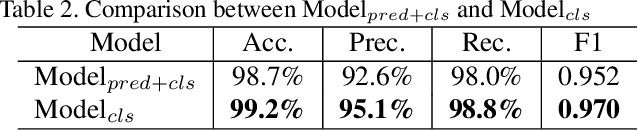
This paper presents a novel approach for predicting the falls of people in advance from monocular video. First, all persons in the observed frames are detected and tracked with the coordinates of their body keypoints being extracted meanwhile. A keypoints vectorization method is exploited to eliminate irrelevant information in the initial coordinate representation. Then, the observed keypoint sequence of each person is input to the pose prediction module adapted from sequence-to-sequence(seq2seq) architecture to predict the future keypoint sequence. Finally, the predicted pose is analyzed by the falls classifier to judge whether the person will fall down in the future. The pose prediction module and falls classifier are trained separately and tuned jointly using Le2i dataset, which contains 191 videos of various normal daily activities as well as falls performed by several actors. The contrast experiments with mainstream raw RGB-based models show the accuracy improvement of utilizing body keypoints in falls classification. Moreover, the precognition of falls is proved effective by comparisons between models that with and without the pose prediction module.
Towards More Realistic Human-Robot Conversation: A Seq2Seq-based Body Gesture Interaction System
May 05, 2019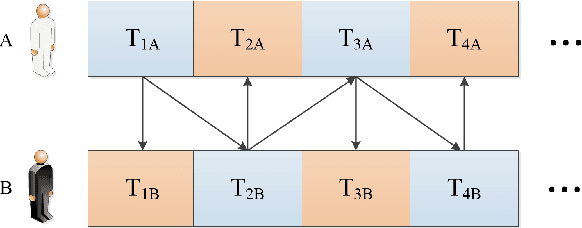

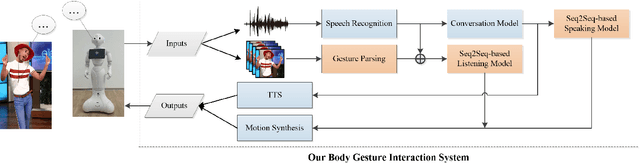
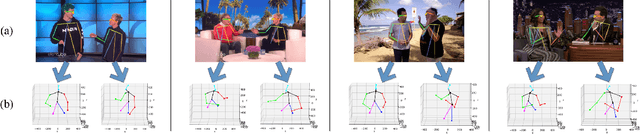
This paper presents a novel method to improve the conversational interaction abilities of intelligent robots to enable more realistic body gestures. The sequence-to-sequence (seq2seq) model is adapted for synthesizing the robots' body gestures represented by the movements of twelve upper-body keypoints in not only the speaking phase, but also the listening phase for which previous methods can hardly achieve. We collected and preprocessed substantial videos of human conversation from Youtube to train our seq2seq-based models and evaluated them by the mean squared error (MSE) and cosine similarity on the test set. The tuned models were implemented to drive a virtual avatar as well as a physical humanoid robot, to demonstrate the improvement on interaction abilities of our method in practice. With body gestures synthesized by our models, the avatar and Pepper exhibited more intelligently while communicating with humans.
Synthetic Data Generation and Adaption for Object Detection in Smart Vending Machines
Apr 28, 2019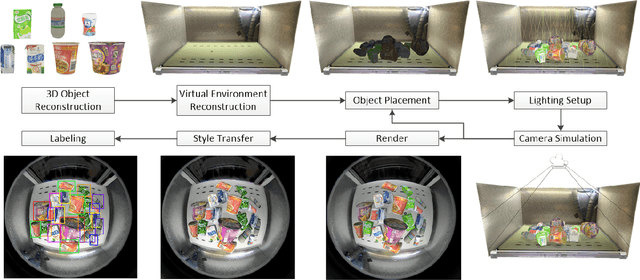
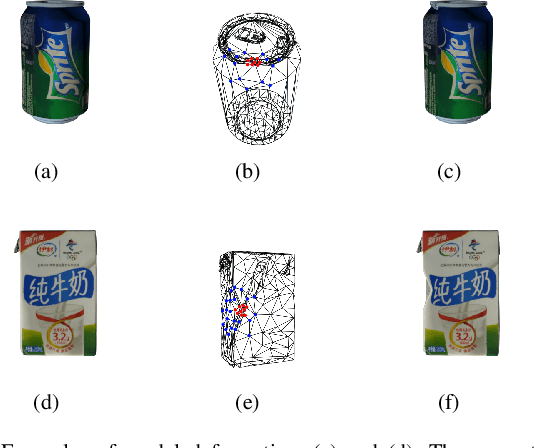
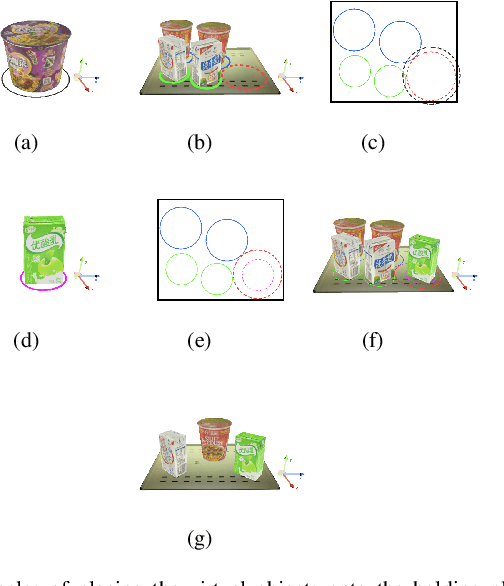
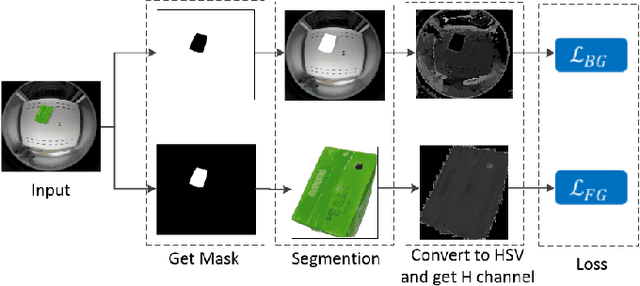
This paper presents an improved scheme for the generation and adaption of synthetic images for the training of deep Convolutional Neural Networks(CNNs) to perform the object detection task in smart vending machines. While generating synthetic data has proved to be effective for complementing the training data in supervised learning methods, challenges still exist for generating virtual images which are similar to those of the complex real scenes and minimizing redundant training data. To solve these problems, we consider the simulation of cluttered objects placed in a virtual scene and the wide-angle camera with distortions used to capture the whole scene in the data generation process, and post-processed the generated images with a elaborately-designed generative network to make them more similar to the real images. Various experiments have been conducted to prove the efficiency of using the generated virtual images to enhance the detection precision on existing datasets with limited real training data and the generalization ability of applying the trained network to datasets collected in new environment.