 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalls Prediction Based on Body Keypoints and Seq2Seq Architecture
Paper and Code
Aug 30, 2019
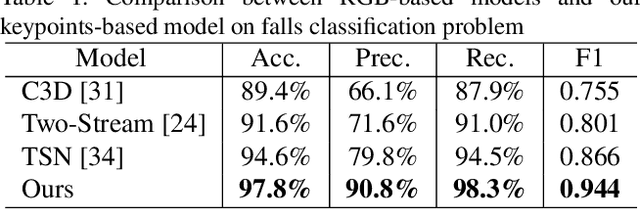
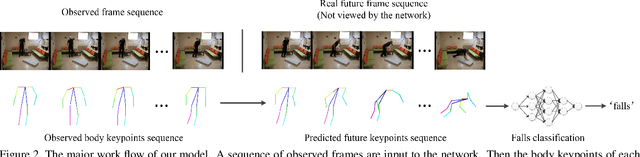
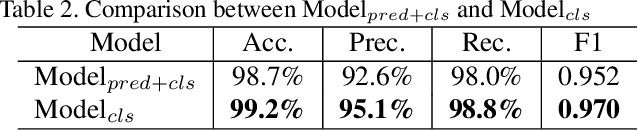
This paper presents a novel approach for predicting the falls of people in advance from monocular video. First, all persons in the observed frames are detected and tracked with the coordinates of their body keypoints being extracted meanwhile. A keypoints vectorization method is exploited to eliminate irrelevant information in the initial coordinate representation. Then, the observed keypoint sequence of each person is input to the pose prediction module adapted from sequence-to-sequence(seq2seq) architecture to predict the future keypoint sequence. Finally, the predicted pose is analyzed by the falls classifier to judge whether the person will fall down in the future. The pose prediction module and falls classifier are trained separately and tuned jointly using Le2i dataset, which contains 191 videos of various normal daily activities as well as falls performed by several actors. The contrast experiments with mainstream raw RGB-based models show the accuracy improvement of utilizing body keypoints in falls classification. Moreover, the precognition of falls is proved effective by comparisons between models that with and without the pose prediction module.