 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAD: A Large-Scale Benchmark for Traffic Accidents Detection from Video Surveillance
Sep 26, 2022


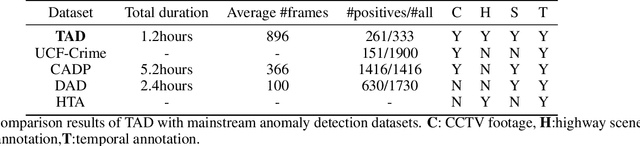
Automatic traffic accidents detection has appealed to the machine vision community due to its implications on the development of autonomous intelligent transportation systems (ITS) and importance to traffic safety. Most previous studies on efficient analysis and prediction of traffic accidents, however, have used small-scale datasets with limited coverage, which limits their effect and applicability. Existing datasets in traffic accidents are either small-scale, not from surveillance cameras, not open-sourced, or not built for freeway scenes. Since accidents happened in freeways tend to cause serious damage and are too fast to catch the spot. An open-sourced datasets targeting on freeway traffic accidents collected from surveillance cameras is in great need and of practical importance. In order to help the vision community address these shortcomings, we endeavor to collect video data of real traffic accidents that covered abundant scenes. After integration and annotation by various dimensions, a large-scale traffic accidents dataset named TAD is proposed in this work. Various experiments on image classification, object detection, and video classification tasks, using public mainstream vision algorithms or frameworks are conducted in this work to demonstrate performance of different methods. The proposed dataset together with the experimental results are presented as a new benchmark to improve computer vision research, especially in ITS.
FPCC-Net: Fast Point Cloud Clustering for Instance Segmentation
Jan 19, 2021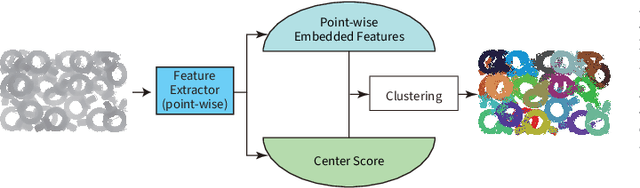

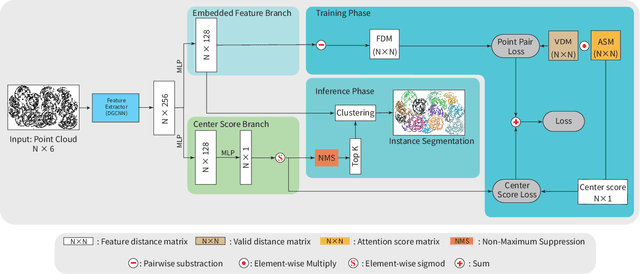
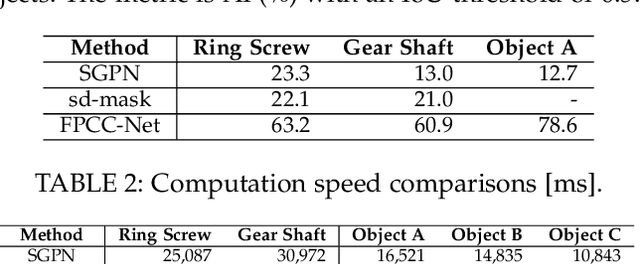
Instance segmentation is an important pre-processing task in numerous real-world applications, such as robotics, autonomous vehicles, and human-computer interaction. However, there has been little research on 3D point cloud instance segmentation of bin-picking scenes in which multiple objects of the same class are stacked together. Compared with the rapid development of deep learning for two-dimensional (2D) image tasks, deep learning-based 3D point cloud segmentation still has a lot of room for development. In such a situation, distinguishing a large number of occluded objects of the same class is a highly challenging problem. In a usual bin-picking scene, an object model is known and the number of object type is one. Thus, the semantic information can be ignored; instead, the focus is put on the segmentation of instances. Based on this task requirement, we propose a network (FPCC-Net) that infers feature centers of each instance and then clusters the remaining points to the closest feature center in feature embedding space. FPCC-Net includes two subnets, one for inferring the feature centers for clustering and the other for describing features of each point. The proposed method is compared with existing 3D point cloud and 2D segmentation methods in some bin-picking scenes. It is shown that FPCC-Net improves average precision (AP) by about 40\% than SGPN and can process about 60,000 points in about 0.8 [s].