 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Enforcement and Feasibility of Hate Speech Moderation on Twitter
Apr 14, 2026Online hate speech is associated with substantial social harms, yet it remains unclear how consistently platforms enforce hate speech policies or whether enforcement is feasible at scale. We address these questions through a global audit of hate speech moderation on Twitter (now X). Using a complete 24-hour snapshot of public tweets, we construct representative samples comprising 540,000 tweets annotated for hate speech by trained annotators across eight major languages. Five months after posting, 80% of hateful tweets remain online, including explicitly violent hate speech. Such tweets are no more likely to be removed than non-hateful tweets, with neither severity nor visibility increasing the likelihood of removal. We then examine whether these enforcement gaps reflect technical limits of large-scale moderation systems. While fully automated detection systems cannot reliably identify hate speech without generating large numbers of false positives, they effectively prioritize likely violations for human review. Simulations of a human-AI moderation pipeline indicate that substantially reducing user exposure to hate speech is economically feasible at a cost below existing regulatory penalties. These results suggest that the persistence of online hate cannot be explained by technical constraints alone but also reflects institutional choices in the allocation of moderation resources.
Self-Discovered Intention-aware Transformer for Multi-modal Vehicle Trajectory Prediction
Apr 08, 2026Predicting vehicle trajectories plays an important role in autonomous driving and ITS applications. Although multiple deep learning algorithms are devised to predict vehicle trajectories, their reliant on specific graph structure (e.g., Graph Neural Network) or explicit intention labeling limit their flexibilities. In this study, we propose a pure Transformer-based network with multiple modals considering their neighboring vehicles. Two separate tracks are employed. One track focuses on predicting the trajectories while the other focuses on predicting the likelihood of each intention considering neighboring vehicles. Study finds that the two track design can increase the performance by separating spatial module from the trajectory generating module. Also, we find the the model can learn an ordered group of trajectories by predicting residual offsets among K trajectories.
HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter
Nov 23, 2024
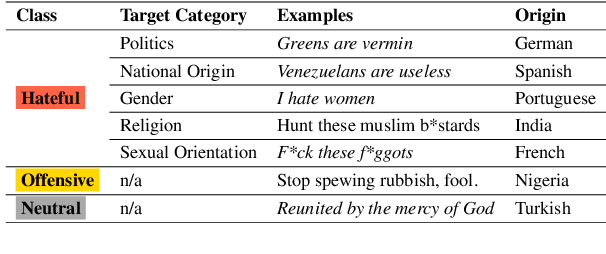
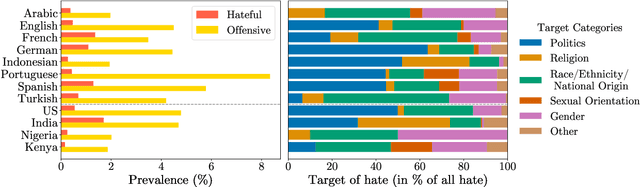

To tackle the global challenge of online hate speech, a large body of research has developed detection models to flag hate speech in the sea of online content. Yet, due to systematic biases in evaluation datasets, detection performance in real-world settings remains unclear, let alone across geographies. To address this issue, we introduce HateDay, the first global hate speech dataset representative of social media settings, randomly sampled from all tweets posted on September 21, 2022 for eight languages and four English-speaking countries. Using HateDay, we show how the prevalence and composition of hate speech varies across languages and countries. We also find that evaluation on academic hate speech datasets overestimates real-world detection performance, which we find is very low, especially for non-European languages. We identify several factors explaining poor performance, including models' inability to distinguish between hate and offensive speech, and the misalignment between academic target focus and real-world target prevalence. We finally argue that such low performance renders hate speech moderation with public detection models unfeasible, even in a human-in-the-loop setting which we find is prohibitively costly. Overall, we emphasize the need to evaluate future detection models from academia and platforms in real-world settings to address this global challenge.
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Apr 27, 2024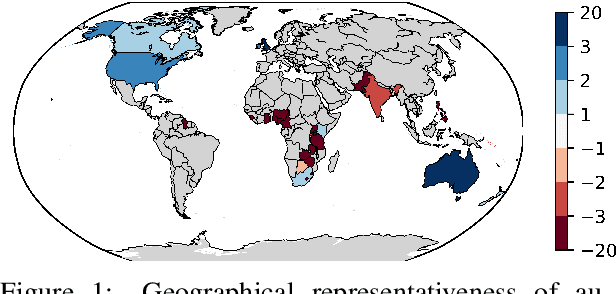
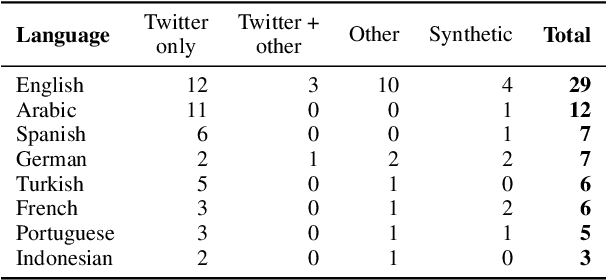
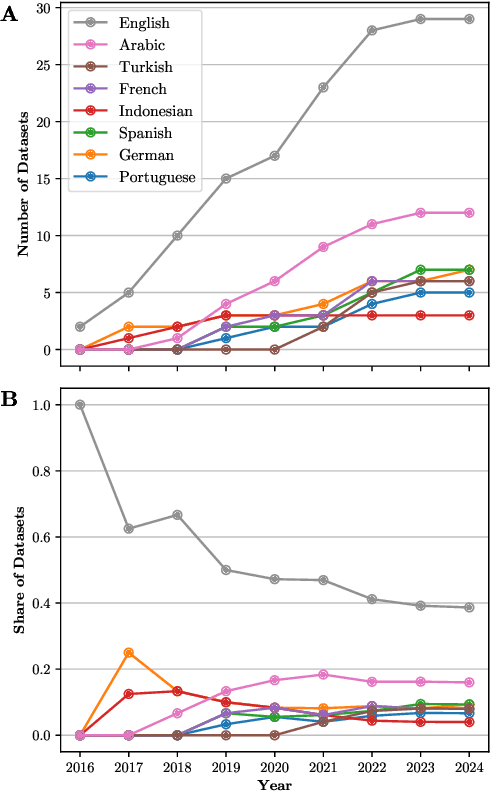
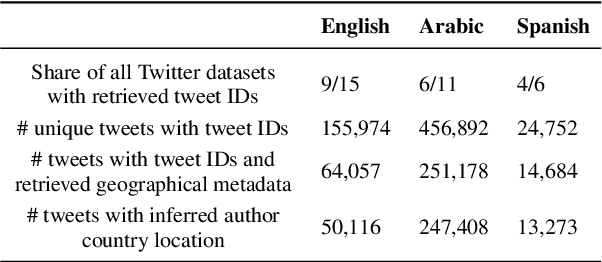
Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by language. This hides potential cultural biases, as one language may be spoken in different countries home to different cultures. In this work, we evaluate cultural bias in HS datasets by leveraging two interrelated cultural proxies: language and geography. We conduct a systematic survey of HS datasets in eight languages and confirm past findings on their English-language bias, but also show that this bias has been steadily decreasing in the past few years. For three geographically-widespread languages -- English, Arabic and Spanish -- we then leverage geographical metadata from tweets to approximate geo-cultural contexts by pairing language and country information. We find that HS datasets for these languages exhibit a strong geo-cultural bias, largely overrepresenting a handful of countries (e.g., US and UK for English) relative to their prominence in both the broader social media population and the general population speaking these languages. Based on these findings, we formulate recommendations for the creation of future HS datasets.
Improving the accuracy of freight mode choice models: A case study using the 2017 CFS PUF data set and ensemble learning techniques
Feb 01, 2024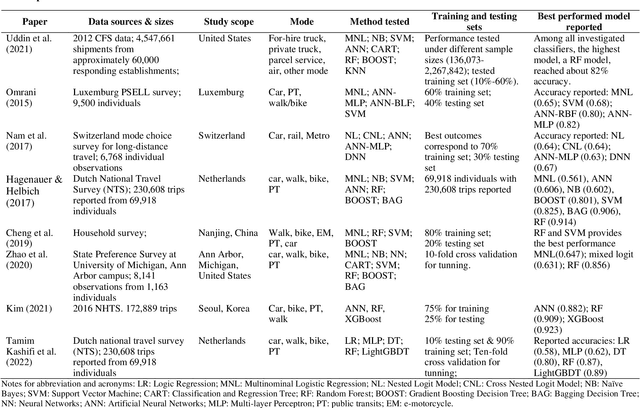
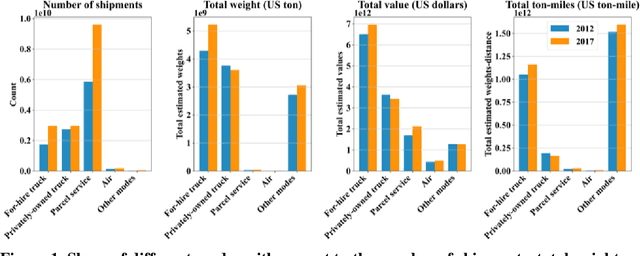
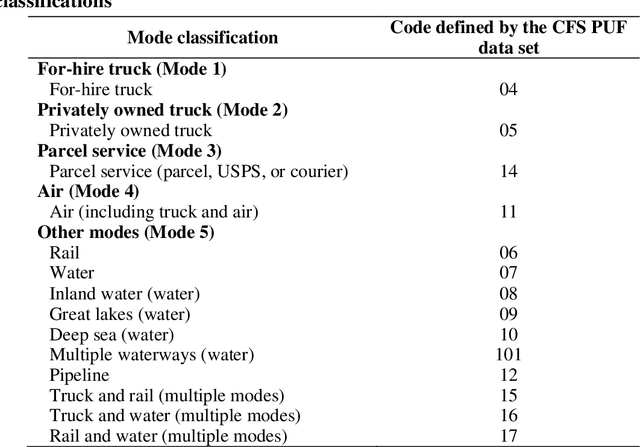
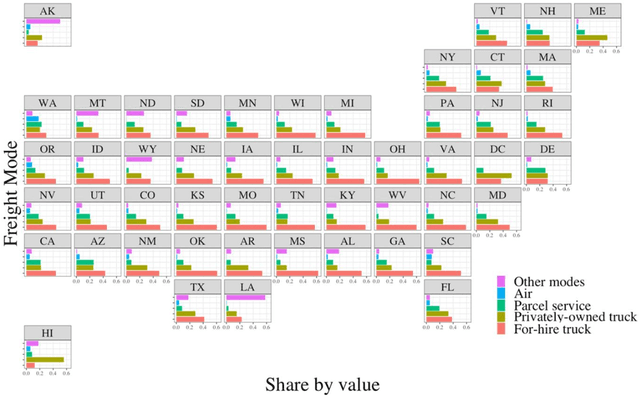
The US Census Bureau has collected two rounds of experimental data from the Commodity Flow Survey, providing shipment-level characteristics of nationwide commodity movements, published in 2012 (i.e., Public Use Microdata) and in 2017 (i.e., Public Use File). With this information, data-driven methods have become increasingly valuable for understanding detailed patterns in freight logistics. In this study, we used the 2017 Commodity Flow Survey Public Use File data set to explore building a high-performance freight mode choice model, considering three main improvements: (1) constructing local models for each separate commodity/industry category; (2) extracting useful geographical features, particularly the derived distance of each freight mode between origin/destination zones; and (3) applying additional ensemble learning methods such as stacking or voting to combine results from local and unified models for improved performance. The proposed method achieved over 92% accuracy without incorporating external information, an over 19% increase compared to directly fitting Random Forests models over 10,000 samples. Furthermore, SHAP (Shapely Additive Explanations) values were computed to explain the outputs and major patterns obtained from the proposed model. The model framework could enhance the performance and interpretability of existing freight mode choice models.
Analyzing Robustness of the Deep Reinforcement Learning Algorithm in Ramp Metering Applications Considering False Data Injection Attack and Defense
Jan 28, 2023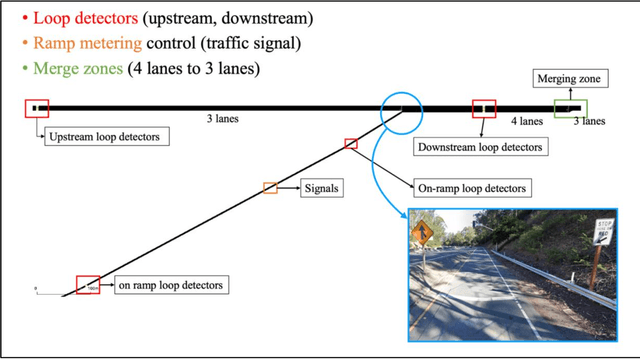
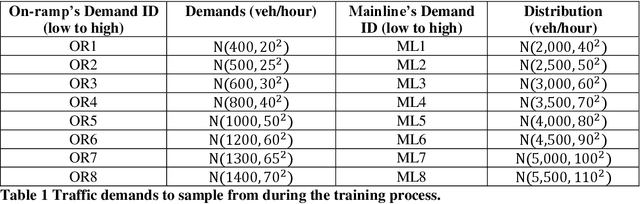
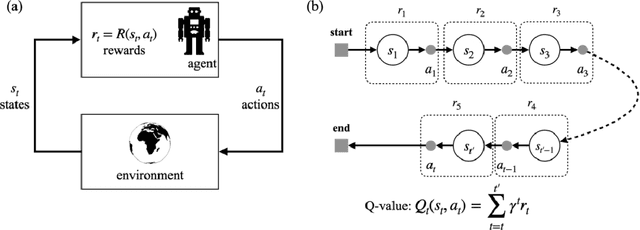
Decades of practices of ramp metering, by controlling downstream volume and smoothing the interweaving traffic, have proved that ramp metering can decrease total travel time, mitigate shockwaves, decrease rear-end collisions, reduce pollution, etc. Besides traditional methods like ALIENA algorithms, Deep Reinforcement Learning algorithms have been established recently to build finer control on ramp metering. However, those Deep Learning models may be venerable to adversarial attacks. Thus, it is important to investigate the robustness of those models under False Data Injection adversarial attack. Furthermore, algorithms capable of detecting anomaly data from clean data are the key to safeguard Deep Learning algorithm. In this study, an online algorithm that can distinguish adversarial data from clean data are tested. Results found that in most cases anomaly data can be distinguished from clean data, although their difference is too small to be manually distinguished by humans. In practice, whenever adversarial/hazardous data is detected, the system can fall back to a fixed control program, and experts should investigate the detectors status or security protocols afterwards before real damages happen.
FPCC-Net: Fast Point Cloud Clustering for Instance Segmentation
Jan 19, 2021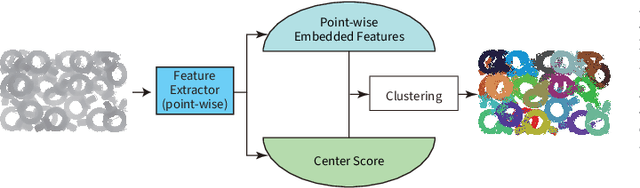

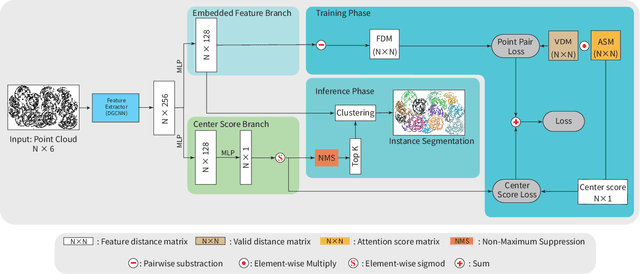
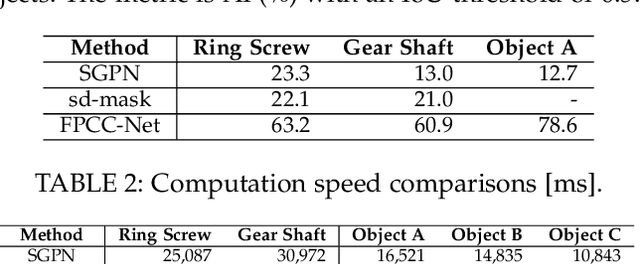
Instance segmentation is an important pre-processing task in numerous real-world applications, such as robotics, autonomous vehicles, and human-computer interaction. However, there has been little research on 3D point cloud instance segmentation of bin-picking scenes in which multiple objects of the same class are stacked together. Compared with the rapid development of deep learning for two-dimensional (2D) image tasks, deep learning-based 3D point cloud segmentation still has a lot of room for development. In such a situation, distinguishing a large number of occluded objects of the same class is a highly challenging problem. In a usual bin-picking scene, an object model is known and the number of object type is one. Thus, the semantic information can be ignored; instead, the focus is put on the segmentation of instances. Based on this task requirement, we propose a network (FPCC-Net) that infers feature centers of each instance and then clusters the remaining points to the closest feature center in feature embedding space. FPCC-Net includes two subnets, one for inferring the feature centers for clustering and the other for describing features of each point. The proposed method is compared with existing 3D point cloud and 2D segmentation methods in some bin-picking scenes. It is shown that FPCC-Net improves average precision (AP) by about 40\% than SGPN and can process about 60,000 points in about 0.8 [s].
Region Based Adversarial Synthesis of Facial Action Units
Oct 23, 2019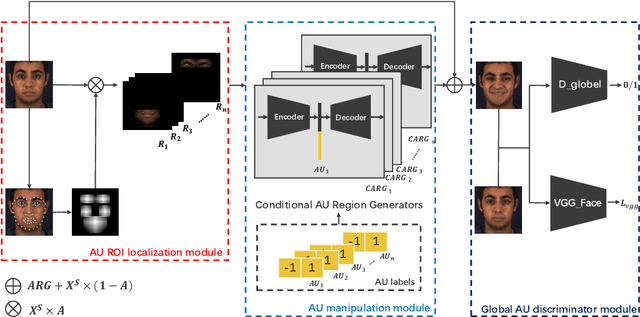
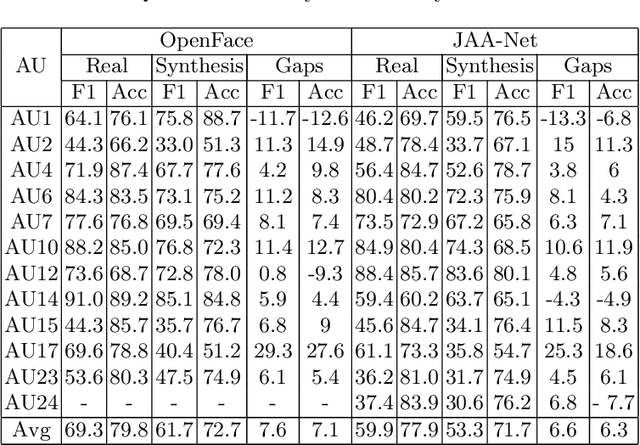
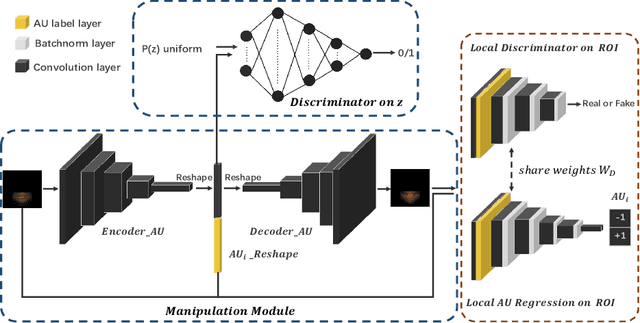
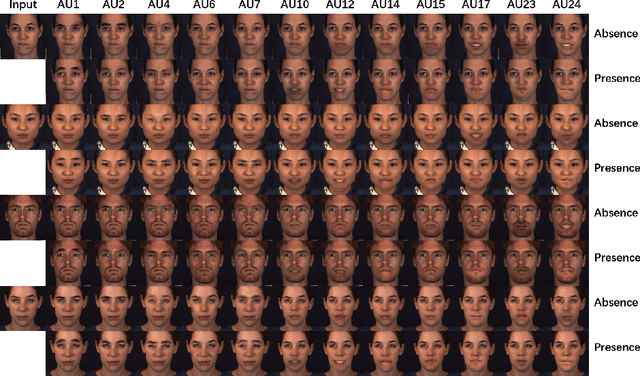
Facial expression synthesis or editing has recently received increasing attention in the field of affective computing and facial expression modeling. However, most existing facial expression synthesis works are limited in paired training data, low resolution, identity information damaging, and so on. To address those limitations, this paper introduces a novel Action Unit (AU) level facial expression synthesis method called Local Attentive Conditional Generative Adversarial Network (LAC-GAN) based on face action units annotations. Given desired AU labels, LAC-GAN utilizes local AU regional rules to control the status of each AU and attentive mechanism to combine several of them into the whole photo-realistic facial expressions or arbitrary facial expressions. In addition, unpaired training data is utilized in our proposed method to train the manipulation module with the corresponding AU labels, which learns a mapping between a facial expression manifold. Extensive qualitative and quantitative evaluations are conducted on the commonly used BP4D dataset to verify the effectiveness of our proposed AU synthesis method.