 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effects of Population and Employment Characteristics on Truck Flows: An Analysis of NextGen NHTS Origin-Destination Data
Feb 02, 2024Truck transportation remains the dominant mode of US freight transportation because of its advantages, such as the flexibility of accessing pickup and drop-off points and faster delivery. Because of the massive freight volume transported by trucks, understanding the effects of population and employment characteristics on truck flows is critical for better transportation planning and investment decisions. The US Federal Highway Administration published a truck travel origin-destination data set as part of the Next Generation National Household Travel Survey program. This data set contains the total number of truck trips in 2020 within and between 583 predefined zones encompassing metropolitan and nonmetropolitan statistical areas within each state and Washington, DC. In this study, origin-destination-level truck trip flow data was augmented to include zone-level population and employment characteristics from the US Census Bureau. Census population and County Business Patterns data were included. The final data set was used to train a machine learning algorithm-based model, Extreme Gradient Boosting (XGBoost), where the target variable is the number of total truck trips. Shapley Additive ExPlanation (SHAP) was adopted to explain the model results. Results showed that the distance between the zones was the most important variable and had a nonlinear relationship with truck flows.
Evaluation of Google's Voice Recognition and Sentence Classification for Health Care Applications
Feb 02, 2024This study examined the use of voice recognition technology in perioperative services (Periop) to enable Periop staff to record workflow milestones using mobile technology. The use of mobile technology to improve patient flow and quality of care could be facilitated if such voice recognition technology could be made robust. The goal of this experiment was to allow the Periop staff to provide care without being interrupted with data entry and querying tasks. However, the results are generalizable to other situations where an engineering manager attempts to improve communication performance using mobile technology. This study enhanced Google's voice recognition capability by using post-processing classifiers (i.e., bag-of-sentences, support vector machine, and maximum entropy). The experiments investigated three factors (original phrasing, reduced phrasing, and personalized phrasing) at three levels (zero training repetition, 5 training repetitions, and 10 training repetitions). Results indicated that personal phrasing yielded the highest correctness and that training the device to recognize an individual's voice improved correctness as well. Although simplistic, the bag-of-sentences classifier significantly improved voice recognition correctness. The classification efficiency of the maximum entropy and support vector machine algorithms was found to be nearly identical. These results suggest that engineering managers could significantly enhance Google's voice recognition technology by using post-processing techniques, which would facilitate its use in health care and other applications.
Improving the accuracy of freight mode choice models: A case study using the 2017 CFS PUF data set and ensemble learning techniques
Feb 01, 2024
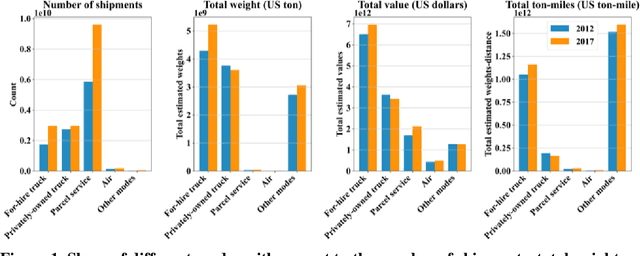
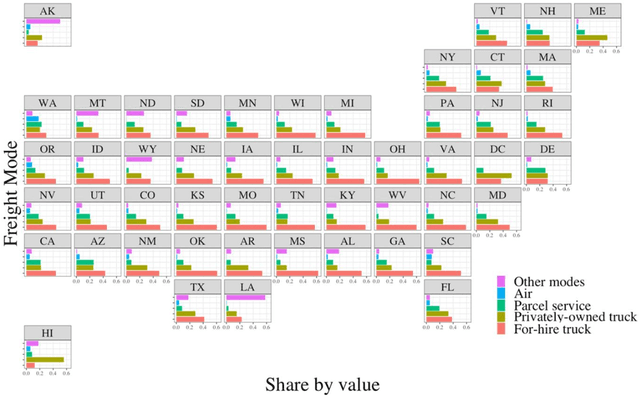
The US Census Bureau has collected two rounds of experimental data from the Commodity Flow Survey, providing shipment-level characteristics of nationwide commodity movements, published in 2012 (i.e., Public Use Microdata) and in 2017 (i.e., Public Use File). With this information, data-driven methods have become increasingly valuable for understanding detailed patterns in freight logistics. In this study, we used the 2017 Commodity Flow Survey Public Use File data set to explore building a high-performance freight mode choice model, considering three main improvements: (1) constructing local models for each separate commodity/industry category; (2) extracting useful geographical features, particularly the derived distance of each freight mode between origin/destination zones; and (3) applying additional ensemble learning methods such as stacking or voting to combine results from local and unified models for improved performance. The proposed method achieved over 92% accuracy without incorporating external information, an over 19% increase compared to directly fitting Random Forests models over 10,000 samples. Furthermore, SHAP (Shapely Additive Explanations) values were computed to explain the outputs and major patterns obtained from the proposed model. The model framework could enhance the performance and interpretability of existing freight mode choice models.
Modeling Freight Mode Choice Using Machine Learning Classifiers: A Comparative Study Using the Commodity Flow Survey (CFS) Data
Feb 01, 2024This study explores the usefulness of machine learning classifiers for modeling freight mode choice. We investigate eight commonly used machine learning classifiers, namely Naive Bayes, Support Vector Machine, Artificial Neural Network, K-Nearest Neighbors, Classification and Regression Tree, Random Forest, Boosting and Bagging, along with the classical Multinomial Logit model. US 2012 Commodity Flow Survey data are used as the primary data source; we augment it with spatial attributes from secondary data sources. The performance of the classifiers is compared based on prediction accuracy results. The current research also examines the role of sample size and training-testing data split ratios on the predictive ability of the various approaches. In addition, the importance of variables is estimated to determine how the variables influence freight mode choice. The results show that the tree-based ensemble classifiers perform the best. Specifically, Random Forest produces the most accurate predictions, closely followed by Boosting and Bagging. With regard to variable importance, shipment characteristics, such as shipment distance, industry classification of the shipper and shipment size, are the most significant factors for freight mode choice decisions.
An Interpretable Machine Learning Framework to Understand Bikeshare Demand before and during the COVID-19 Pandemic in New York City
Nov 10, 2023In recent years, bikesharing systems have become increasingly popular as affordable and sustainable micromobility solutions. Advanced mathematical models such as machine learning are required to generate good forecasts for bikeshare demand. To this end, this study proposes a machine learning modeling framework to estimate hourly demand in a large-scale bikesharing system. Two Extreme Gradient Boosting models were developed: one using data from before the COVID-19 pandemic (March 2019 to February 2020) and the other using data from during the pandemic (March 2020 to February 2021). Furthermore, a model interpretation framework based on SHapley Additive exPlanations was implemented. Based on the relative importance of the explanatory variables considered in this study, share of female users and hour of day were the two most important explanatory variables in both models. However, the month variable had higher importance in the pandemic model than in the pre-pandemic model.