 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Enforcement and Feasibility of Hate Speech Moderation on Twitter
Apr 14, 2026Online hate speech is associated with substantial social harms, yet it remains unclear how consistently platforms enforce hate speech policies or whether enforcement is feasible at scale. We address these questions through a global audit of hate speech moderation on Twitter (now X). Using a complete 24-hour snapshot of public tweets, we construct representative samples comprising 540,000 tweets annotated for hate speech by trained annotators across eight major languages. Five months after posting, 80% of hateful tweets remain online, including explicitly violent hate speech. Such tweets are no more likely to be removed than non-hateful tweets, with neither severity nor visibility increasing the likelihood of removal. We then examine whether these enforcement gaps reflect technical limits of large-scale moderation systems. While fully automated detection systems cannot reliably identify hate speech without generating large numbers of false positives, they effectively prioritize likely violations for human review. Simulations of a human-AI moderation pipeline indicate that substantially reducing user exposure to hate speech is economically feasible at a cost below existing regulatory penalties. These results suggest that the persistence of online hate cannot be explained by technical constraints alone but also reflects institutional choices in the allocation of moderation resources.
Artificial intelligence, rationalization, and the limits of control in the public sector: the case of tax policy optimization
Jul 07, 2024The use of artificial intelligence (AI) in the public sector is best understood as a continuation and intensification of long standing rationalization and bureaucratization processes. Drawing on Weber, we take the core of these processes to be the replacement of traditions with instrumental rationality, i.e., the most calculable and efficient way of achieving any given policy objective. In this article, we demonstrate how much of the criticisms, both among the public and in scholarship, directed towards AI systems spring from well known tensions at the heart of Weberian rationalization. To illustrate this point, we introduce a thought experiment whereby AI systems are used to optimize tax policy to advance a specific normative end, reducing economic inequality. Our analysis shows that building a machine-like tax system that promotes social and economic equality is possible. However, it also highlights that AI driven policy optimization (i) comes at the exclusion of other competing political values, (ii) overrides citizens sense of their noninstrumental obligations to each other, and (iii) undermines the notion of humans as self-determining beings. Contemporary scholarship and advocacy directed towards ensuring that AI systems are legal, ethical, and safe build on and reinforce central assumptions that underpin the process of rationalization, including the modern idea that science can sweep away oppressive systems and replace them with a rule of reason that would rescue humans from moral injustices. That is overly optimistic. Science can only provide the means, they cannot dictate the ends. Nonetheless, the use of AI in the public sector can also benefit the institutions and processes of liberal democracies. Most importantly, AI driven policy optimization demands that normative ends are made explicit and formalized, thereby subjecting them to public scrutiny and debate.
AI and Social Theory
Jul 07, 2024In this paper, we sketch a programme for AI driven social theory. We begin by defining what we mean by artificial intelligence (AI) in this context. We then lay out our model for how AI based models can draw on the growing availability of digital data to help test the validity of different social theories based on their predictive power. In doing so, we use the work of Randall Collins and his state breakdown model to exemplify that, already today, AI based models can help synthesize knowledge from a variety of sources, reason about the world, and apply what is known across a wide range of problems in a systematic way. However, we also find that AI driven social theory remains subject to a range of practical, technical, and epistemological limitations. Most critically, existing AI systems lack three essential capabilities needed to advance social theory in ways that are cumulative, holistic, open-ended, and purposeful. These are (1) semanticization, i.e., the ability to develop and operationalize verbal concepts to represent machine-manipulable knowledge, (2) transferability, i.e., the ability to transfer what has been learned in one context to another, and (3) generativity, i.e., the ability to independently create and improve on concepts and models. We argue that if the gaps identified here are addressed by further research, there is no reason why, in the future, the most advanced programme in social theory should not be led by AI-driven cumulative advances.
From Languages to Geographies: Towards Evaluating Cultural Bias in Hate Speech Datasets
Apr 27, 2024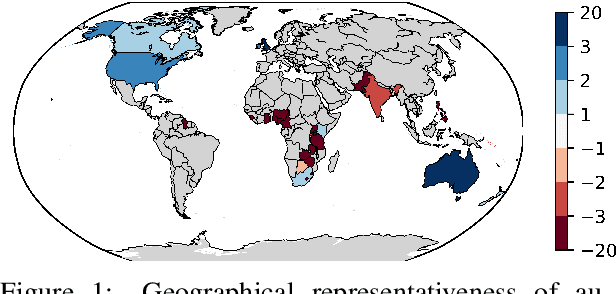
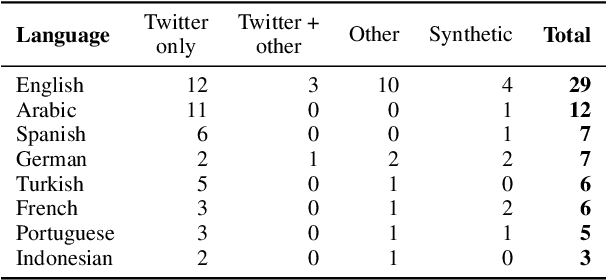
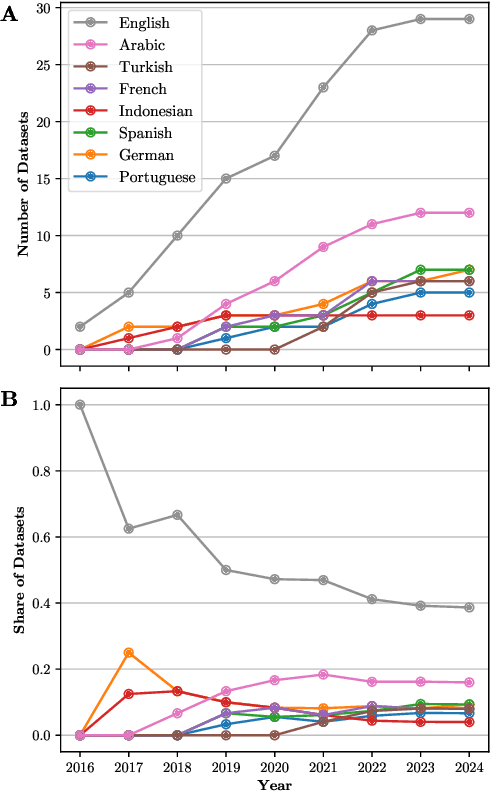
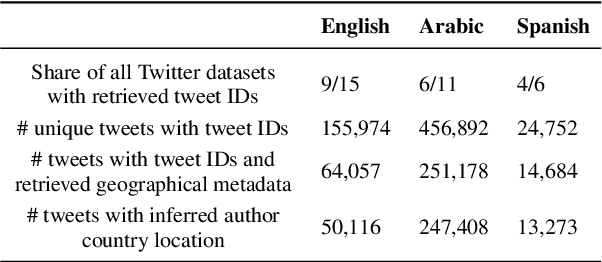
Perceptions of hate can vary greatly across cultural contexts. Hate speech (HS) datasets, however, have traditionally been developed by language. This hides potential cultural biases, as one language may be spoken in different countries home to different cultures. In this work, we evaluate cultural bias in HS datasets by leveraging two interrelated cultural proxies: language and geography. We conduct a systematic survey of HS datasets in eight languages and confirm past findings on their English-language bias, but also show that this bias has been steadily decreasing in the past few years. For three geographically-widespread languages -- English, Arabic and Spanish -- we then leverage geographical metadata from tweets to approximate geo-cultural contexts by pairing language and country information. We find that HS datasets for these languages exhibit a strong geo-cultural bias, largely overrepresenting a handful of countries (e.g., US and UK for English) relative to their prominence in both the broader social media population and the general population speaking these languages. Based on these findings, we formulate recommendations for the creation of future HS datasets.