 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Enforcement and Feasibility of Hate Speech Moderation on Twitter
Apr 14, 2026Online hate speech is associated with substantial social harms, yet it remains unclear how consistently platforms enforce hate speech policies or whether enforcement is feasible at scale. We address these questions through a global audit of hate speech moderation on Twitter (now X). Using a complete 24-hour snapshot of public tweets, we construct representative samples comprising 540,000 tweets annotated for hate speech by trained annotators across eight major languages. Five months after posting, 80% of hateful tweets remain online, including explicitly violent hate speech. Such tweets are no more likely to be removed than non-hateful tweets, with neither severity nor visibility increasing the likelihood of removal. We then examine whether these enforcement gaps reflect technical limits of large-scale moderation systems. While fully automated detection systems cannot reliably identify hate speech without generating large numbers of false positives, they effectively prioritize likely violations for human review. Simulations of a human-AI moderation pipeline indicate that substantially reducing user exposure to hate speech is economically feasible at a cost below existing regulatory penalties. These results suggest that the persistence of online hate cannot be explained by technical constraints alone but also reflects institutional choices in the allocation of moderation resources.
HateDay: Insights from a Global Hate Speech Dataset Representative of a Day on Twitter
Nov 23, 2024
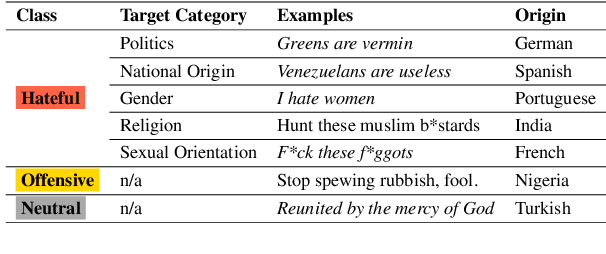
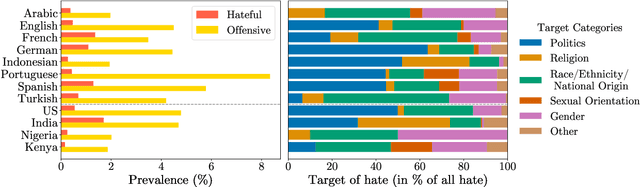

To tackle the global challenge of online hate speech, a large body of research has developed detection models to flag hate speech in the sea of online content. Yet, due to systematic biases in evaluation datasets, detection performance in real-world settings remains unclear, let alone across geographies. To address this issue, we introduce HateDay, the first global hate speech dataset representative of social media settings, randomly sampled from all tweets posted on September 21, 2022 for eight languages and four English-speaking countries. Using HateDay, we show how the prevalence and composition of hate speech varies across languages and countries. We also find that evaluation on academic hate speech datasets overestimates real-world detection performance, which we find is very low, especially for non-European languages. We identify several factors explaining poor performance, including models' inability to distinguish between hate and offensive speech, and the misalignment between academic target focus and real-world target prevalence. We finally argue that such low performance renders hate speech moderation with public detection models unfeasible, even in a human-in-the-loop setting which we find is prohibitively costly. Overall, we emphasize the need to evaluate future detection models from academia and platforms in real-world settings to address this global challenge.
Fine-grained prediction of food insecurity using news streams
Nov 17, 2021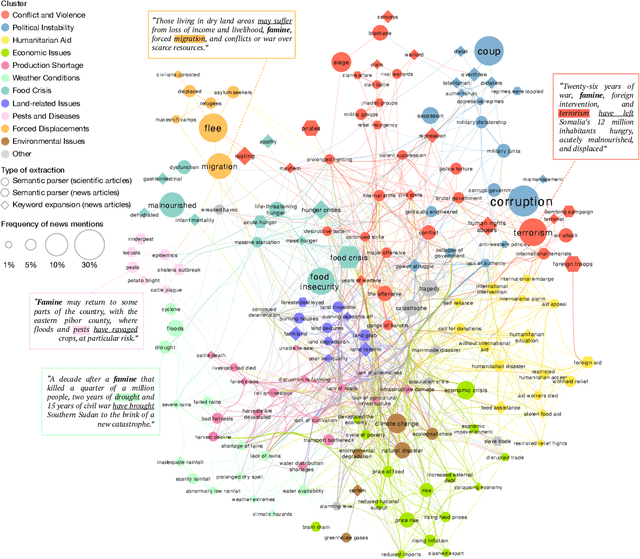
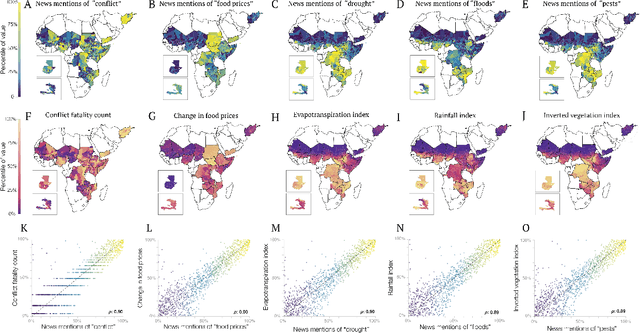

Anticipating the outbreak of a food crisis is crucial to efficiently allocate emergency relief and reduce human suffering. However, existing food insecurity early warning systems rely on risk measures that are often delayed, outdated, or incomplete. Here, we leverage recent advances in deep learning to extract high-frequency precursors to food crises from the text of a large corpus of news articles about fragile states published between 1980 and 2020. Our text features are causally grounded, interpretable, validated by existing data, and allow us to predict 32% more food crises than existing models up to three months ahead of time at the district level across 15 fragile states. These results could have profound implications on how humanitarian aid gets allocated and open new avenues for machine learning to improve decision making in data-scarce environments.
Enhancing Transparency and Control when Drawing Data-Driven Inferences about Individuals
Jun 26, 2016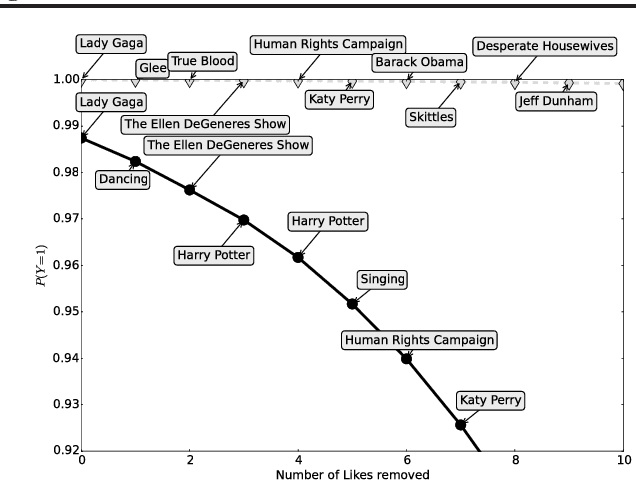
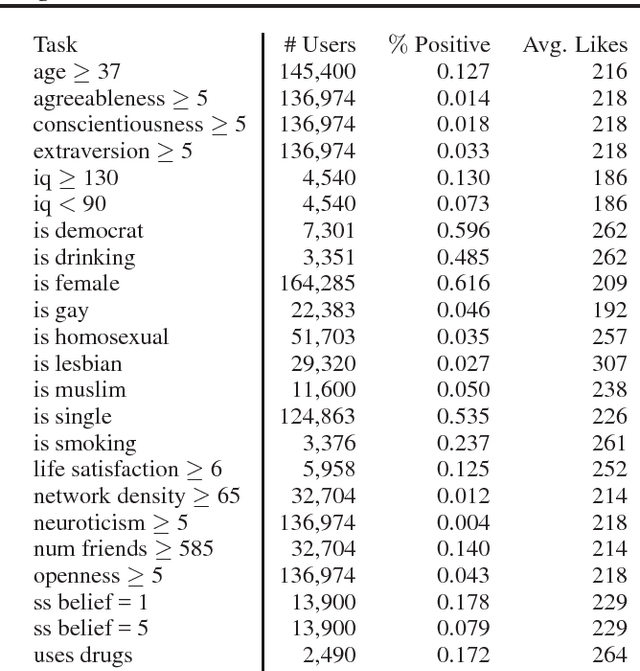
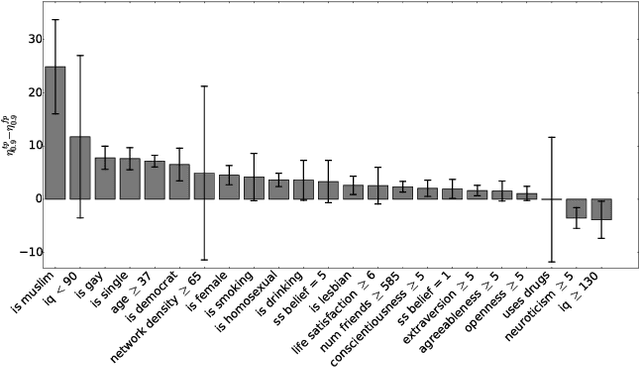

Recent studies have shown that information disclosed on social network sites (such as Facebook) can be used to predict personal characteristics with surprisingly high accuracy. In this paper we examine a method to give online users transparency into why certain inferences are made about them by statistical models, and control to inhibit those inferences by hiding ("cloaking") certain personal information from inference. We use this method to examine whether such transparency and control would be a reasonable goal by assessing how difficult it would be for users to actually inhibit inferences. Applying the method to data from a large collection of real users on Facebook, we show that a user must cloak only a small portion of her Facebook Likes in order to inhibit inferences about their personal characteristics. However, we also show that in response a firm could change its modeling of users to make cloaking more difficult.