 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE-ACT: Scaling Multi-Task Bimanual Manipulation with Sparse Language-Conditioned Mixture-of-Experts Transformers
Mar 16, 2026The ability of robots to handle multiple tasks under a unified policy is critical for deploying embodied intelligence in real-world household and industrial applications. However, out-of-distribution variation across tasks often causes severe task interference and negative transfer when training general robotic policies. To address this challenge, we propose a lightweight multi-task imitation learning framework for bimanual manipulation, termed Mixture-of-Experts-Enhanced Action Chunking Transformer (MoE-ACT), which integrates sparse Mixture-of-Experts (MoE) modules into the Transformer encoder of ACT. The MoE layer decomposes a unified task policy into independently invoked expert components. Through adaptive activation, it naturally decouples multi-task action distributions in latent space. During decoding, Feature-wise Linear Modulation (FiLM) dynamically modulates action tokens to improve consistency between action generation and task instructions. In parallel, multi-scale cross-attention enables the policy to simultaneously focus on both low-level and high-level semantic features, providing rich visual information for robotic manipulation. We further incorporate textual information, transitioning the framework from a purely vision-based model to a vision-centric, language-conditioned action generation system. Experimental validation in both simulation and a real-world dual-arm setup shows that MoE-ACT substantially improves multi-task performance. Specifically, MoE-ACT outperforms vanilla ACT by an average of 33% in success rate. These results indicate that MoE-ACT provides stronger robustness and generalization in complex multi-task bimanual manipulation environments. Our open-source project page can be found at https://j3k7.github.io/MoE-ACT/.
Omni-Manip: Beyond-FOV Large-Workspace Humanoid Manipulation with Omnidirectional 3D Perception
Mar 05, 2026The deployment of humanoid robots for dexterous manipulation in unstructured environments remains challenging due to perceptual limitations that constrain the effective workspace. In scenarios where physical constraints prevent the robot from repositioning itself, maintaining omnidirectional awareness becomes far more critical than color or semantic information. While recent advances in visuomotor policy learning have improved manipulation capabilities, conventional RGB-D solutions suffer from narrow fields of view (FOV) and self-occlusion, requiring frequent base movements that introduce motion uncertainty and safety risks. Existing approaches to expanding perception, including active vision systems and third-view cameras, introduce mechanical complexity, calibration dependencies, and latency that hinder reliable real-time performance. In this work, We propose Omni-Manip, an end-to-end LiDAR-driven 3D visuomotor policy that enables robust manipulation in large workspaces. Our method processes panoramic point clouds through a Time-Aware Attention Pooling mechanism, efficiently encoding sparse 3D data while capturing temporal dependencies. This 360° perception allows the robot to interact with objects across wide areas without frequent repositioning. To support policy learning, we develop a whole-body teleoperation system for efficient data collection on full-body coordination. Extensive experiments in simulation and real-world environments show that Omni-Manip achieves robust performance in large-workspace and cluttered scenarios, outperforming baselines that rely on egocentric depth cameras.
SpecFuse: A Spectral-Temporal Fusion Predictive Control Framework for UAV Landing on Oscillating Marine Platforms
Feb 17, 2026Autonomous landing of Uncrewed Aerial Vehicles (UAVs) on oscillating marine platforms is severely constrained by wave-induced multi-frequency oscillations, wind disturbances, and prediction phase lags in motion prediction. Existing methods either treat platform motion as a general random process or lack explicit modeling of wave spectral characteristics, leading to suboptimal performance under dynamic sea conditions. To address these limitations, we propose SpecFuse: a novel spectral-temporal fusion predictive control framework that integrates frequency-domain wave decomposition with time-domain recursive state estimation for high-precision 6-DoF motion forecasting of Uncrewed Surface Vehicles (USVs). The framework explicitly models dominant wave harmonics to mitigate phase lags, refining predictions in real time via IMU data without relying on complex calibration. Additionally, we design a hierarchical control architecture featuring a sampling-based HPO-RRT* algorithm for dynamic trajectory planning under non-convex constraints and a learning-augmented predictive controller that fuses data-driven disturbance compensation with optimization-based execution. Extensive validations (2,000 simulations + 8 lake experiments) show our approach achieves a 3.2 cm prediction error, 4.46 cm landing deviation, 98.7% / 87.5% success rates (simulation / real-world), and 82 ms latency on embedded hardware, outperforming state-of-the-art methods by 44%-48% in accuracy. Its robustness to wave-wind coupling disturbances supports critical maritime missions such as search and rescue and environmental monitoring. All code, experimental configurations, and datasets will be released as open-source to facilitate reproducibility.
ExoGait-MS: Learning Periodic Dynamics with Multi-Scale Graph Network for Exoskeleton Gait Recognition
May 23, 2025
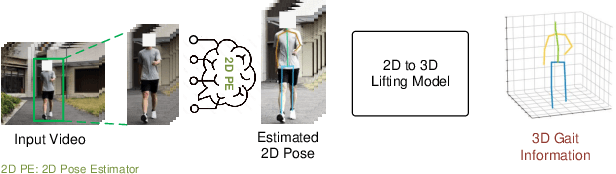


Current exoskeleton control methods often face challenges in delivering personalized treatment. Standardized walking gaits can lead to patient discomfort or even injury. Therefore, personalized gait is essential for the effectiveness of exoskeleton robots, as it directly impacts their adaptability, comfort, and rehabilitation outcomes for individual users. To enable personalized treatment in exoskeleton-assisted therapy and related applications, accurate recognition of personal gait is crucial for implementing tailored gait control. The key challenge in gait recognition lies in effectively capturing individual differences in subtle gait features caused by joint synergy, such as step frequency and step length. To tackle this issue, we propose a novel approach, which uses Multi-Scale Global Dense Graph Convolutional Networks (GCN) in the spatial domain to identify latent joint synergy patterns. Moreover, we propose a Gait Non-linear Periodic Dynamics Learning module to effectively capture the periodic characteristics of gait in the temporal domain. To support our individual gait recognition task, we have constructed a comprehensive gait dataset that ensures both completeness and reliability. Our experimental results demonstrate that our method achieves an impressive accuracy of 94.34% on this dataset, surpassing the current state-of-the-art (SOTA) by 3.77%. This advancement underscores the potential of our approach to enhance personalized gait control in exoskeleton-assisted therapy.
ApexNav: An Adaptive Exploration Strategy for Zero-Shot Object Navigation with Target-centric Semantic Fusion
Apr 22, 2025



Navigating unknown environments to find a target object is a significant challenge. While semantic information is crucial for navigation, relying solely on it for decision-making may not always be efficient, especially in environments with weak semantic cues. Additionally, many methods are susceptible to misdetections, especially in environments with visually similar objects. To address these limitations, we propose ApexNav, a zero-shot object navigation framework that is both more efficient and reliable. For efficiency, ApexNav adaptively utilizes semantic information by analyzing its distribution in the environment, guiding exploration through semantic reasoning when cues are strong, and switching to geometry-based exploration when they are weak. For reliability, we propose a target-centric semantic fusion method that preserves long-term memory of the target object and similar objects, reducing false detections and minimizing task failures. We evaluate ApexNav on the HM3Dv1, HM3Dv2, and MP3D datasets, where it outperforms state-of-the-art methods in both SR and SPL metrics. Comprehensive ablation studies further demonstrate the effectiveness of each module. Furthermore, real-world experiments validate the practicality of ApexNav in physical environments. Project page is available at https://robotics-star.com/ApexNav.
FERMI: Flexible Radio Mapping with a Hybrid Propagation Model and Scalable Autonomous Data Collection
Apr 21, 2025Communication is fundamental for multi-robot collaboration, with accurate radio mapping playing a crucial role in predicting signal strength between robots. However, modeling radio signal propagation in large and occluded environments is challenging due to complex interactions between signals and obstacles. Existing methods face two key limitations: they struggle to predict signal strength for transmitter-receiver pairs not present in the training set, while also requiring extensive manual data collection for modeling, making them impractical for large, obstacle-rich scenarios. To overcome these limitations, we propose FERMI, a flexible radio mapping framework. FERMI combines physics-based modeling of direct signal paths with a neural network to capture environmental interactions with radio signals. This hybrid model learns radio signal propagation more efficiently, requiring only sparse training data. Additionally, FERMI introduces a scalable planning method for autonomous data collection using a multi-robot team. By increasing parallelism in data collection and minimizing robot travel costs between regions, overall data collection efficiency is significantly improved. Experiments in both simulation and real-world scenarios demonstrate that FERMI enables accurate signal prediction and generalizes well to unseen positions in complex environments. It also supports fully autonomous data collection and scales to different team sizes, offering a flexible solution for creating radio maps. Our code is open-sourced at https://github.com/ymLuo1214/Flexible-Radio-Mapping.
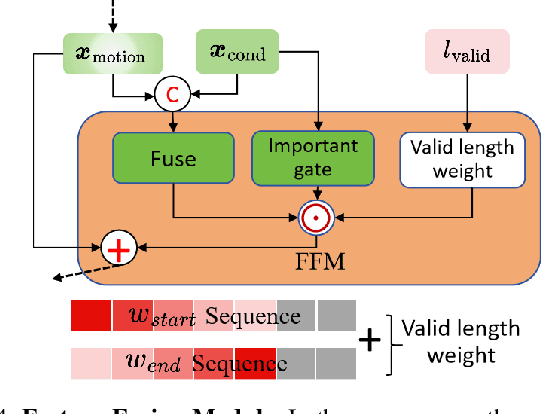
GenM$^3$: Generative Pretrained Multi-path Motion Model for Text Conditional Human Motion Generation
Mar 19, 2025Scaling up motion datasets is crucial to enhance motion generation capabilities. However, training on large-scale multi-source datasets introduces data heterogeneity challenges due to variations in motion content. To address this, we propose Generative Pretrained Multi-path Motion Model (GenM$^3$), a comprehensive framework designed to learn unified motion representations. GenM$^3$ comprises two components: 1) a Multi-Expert VQ-VAE (MEVQ-VAE) that adapts to different dataset distributions to learn a unified discrete motion representation, and 2) a Multi-path Motion Transformer (MMT) that improves intra-modal representations by using separate modality-specific pathways, each with densely activated experts to accommodate variations within that modality, and improves inter-modal alignment by the text-motion shared pathway. To enable large-scale training, we integrate and unify 11 high-quality motion datasets (approximately 220 hours of motion data) and augment it with textual annotations (nearly 10,000 motion sequences labeled by a large language model and 300+ by human experts). After training on our integrated dataset, GenM$^3$ achieves a state-of-the-art FID of 0.035 on the HumanML3D benchmark, surpassing state-of-the-art methods by a large margin. It also demonstrates strong zero-shot generalization on IDEA400 dataset, highlighting its effectiveness and adaptability across diverse motion scenarios.
RMG: Real-Time Expressive Motion Generation with Self-collision Avoidance for 6-DOF Companion Robotic Arms
Mar 13, 2025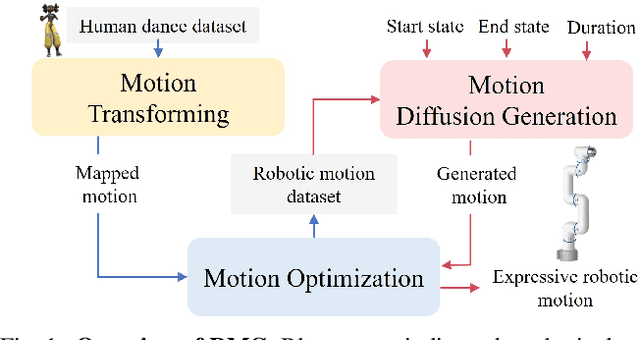
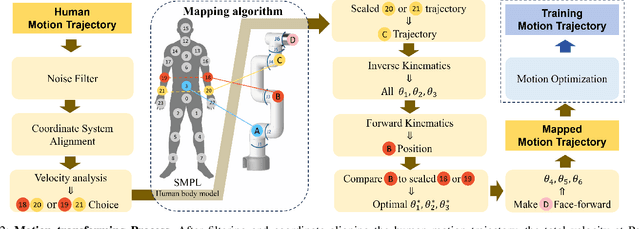
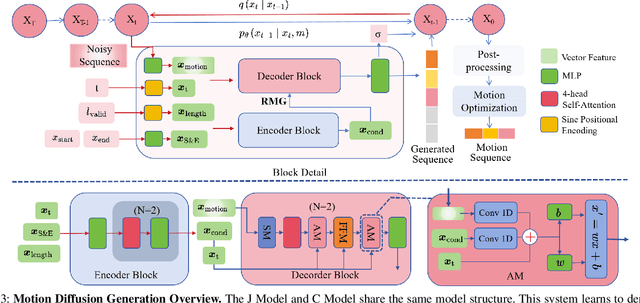
The six-degree-of-freedom (6-DOF) robotic arm has gained widespread application in human-coexisting environments. While previous research has predominantly focused on functional motion generation, the critical aspect of expressive motion in human-robot interaction remains largely unexplored. This paper presents a novel real-time motion generation planner that enhances interactivity by creating expressive robotic motions between arbitrary start and end states within predefined time constraints. Our approach involves three key contributions: first, we develop a mapping algorithm to construct an expressive motion dataset derived from human dance movements; second, we train motion generation models in both Cartesian and joint spaces using this dataset; third, we introduce an optimization algorithm that guarantees smooth, collision-free motion while maintaining the intended expressive style. Experimental results demonstrate the effectiveness of our method, which can generate expressive and generalized motions in under 0.5 seconds while satisfying all specified constraints.
Local Reactive Control for Mobile Manipulators with Whole-Body Safety in Complex Environments
Jan 06, 2025



Mobile manipulators typically encounter significant challenges in navigating narrow, cluttered environments due to their high-dimensional state spaces and complex kinematics. While reactive methods excel in dynamic settings, they struggle to efficiently incorporate complex, coupled constraints across the entire state space. In this work, we present a novel local reactive controller that reformulates the time-domain single-step problem into a multi-step optimization problem in the spatial domain, leveraging the propagation of a serial kinematic chain. This transformation facilitates the formulation of customized, decoupled link-specific constraints, which is further solved efficiently with augmented Lagrangian differential dynamic programming (AL-DDP). Our approach naturally absorbs spatial kinematic propagation in the forward pass and processes all link-specific constraints simultaneously during the backward pass, enhancing both constraint management and computational efficiency. Notably, in this framework, we formulate collision avoidance constraints for each link using accurate geometric models with extracted free regions, and this improves the maneuverability of the mobile manipulator in narrow, cluttered spaces. Experimental results showcase significant improvements in safety, efficiency, and task completion rates. These findings underscore the robustness of the proposed method, particularly in narrow, cluttered environments where conventional approaches could falter. The open-source project can be found at https://github.com/Chunx1nZHENG/MM-with-Whole-Body-Safety-Release.git.
SOAR: Simultaneous Exploration and Photographing with Heterogeneous UAVs for Fast Autonomous Reconstruction
Sep 04, 2024Unmanned Aerial Vehicles (UAVs) have gained significant popularity in scene reconstruction. This paper presents SOAR, a LiDAR-Visual heterogeneous multi-UAV system specifically designed for fast autonomous reconstruction of complex environments. Our system comprises a LiDAR-equipped explorer with a large field-of-view (FoV), alongside photographers equipped with cameras. To ensure rapid acquisition of the scene's surface geometry, we employ a surface frontier-based exploration strategy for the explorer. As the surface is progressively explored, we identify the uncovered areas and generate viewpoints incrementally. These viewpoints are then assigned to photographers through solving a Consistent Multiple Depot Multiple Traveling Salesman Problem (Consistent-MDMTSP), which optimizes scanning efficiency while ensuring task consistency. Finally, photographers utilize the assigned viewpoints to determine optimal coverage paths for acquiring images. We present extensive benchmarks in the realistic simulator, which validates the performance of SOAR compared with classical and state-of-the-art methods. For more details, please see our project page at https://sysu-star.github.io/SOAR}{sysu-star.github.io/SOAR.