 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Think While Listening in Large Audio-Language Models
May 26, 2026Recent advances in Large Audio-Language Models (LALMs) have made real-time, streaming spoken interaction increasingly practical. In this setting, reasoning quality and responsiveness are tightly coupled: delaying reasoning until the speech endpoint can improve answer quality but moves deliberation into user-visible response delay, while answering too early risks committing before decisive evidence arrives. We introduce a learnable wait-think-answer control formulation for LALMs. Motivated by the incremental nature of human conversation, the controller decides under partial audio evidence when to wait, when to externalize a compact reasoning update, and when to answer. Using Qwen2.5-Omni-7B as the base model, we construct aligned wait-think-answer traces from spoken reasoning data, train the controller with supervised fine-tuning (SFT), and then apply Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO). The reward combines answer correctness, action validity, update timing, latency synchronization, reasoning quality, and chain consistency, optimizing the complete wait-think-answer trajectory and not the final answer alone. On a six-task synthetic spoken reasoning question answering (SRQA) benchmark, the six-reward DAPO controller improves the row-weighted accuracy from 67.6% to 70.3% while reducing post-endpoint final-think length by 14% under the same Qwen deployment harness. On a 186-item human-recorded Real Audio Bench, a transfer check beyond text-to-speech (TTS)-rendered speech, the controller family remains functional: SFT achieves the strongest accuracy, while the six-reward DAPO controller is the only learned variant whose final-think length falls below the base. These results suggest that a streaming model should learn when to make intermediate reasoning explicit during the audio stream.
Fast and Safe Trajectory Optimization for Mobile Manipulators With Neural Configuration Space Distance Field
Jan 27, 2026Mobile manipulators promise agile, long-horizon behavior by coordinating base and arm motion, yet whole-body trajectory optimization in cluttered, confined spaces remains difficult due to high-dimensional nonconvexity and the need for fast, accurate collision reasoning. Configuration Space Distance Fields (CDF) enable fixed-base manipulators to model collisions directly in configuration space via smooth, implicit distances. This representation holds strong potential to bypass the nonlinear configuration-to-workspace mapping while preserving accurate whole-body geometry and providing optimization-friendly collision costs. Yet, extending this capability to mobile manipulators is hindered by unbounded workspaces and tighter base-arm coupling. We lift this promise to mobile manipulation with Generalized Configuration Space Distance Fields (GCDF), extending CDF to robots with both translational and rotational joints in unbounded workspaces with tighter base-arm coupling. We prove that GCDF preserves Euclidean-like local distance structure and accurately encodes whole-body geometry in configuration space, and develop a data generation and training pipeline that yields continuous neural GCDFs with accurate values and gradients, supporting efficient GPU-batched queries. Building on this representation, we develop a high-performance sequential convex optimization framework centered on GCDF-based collision reasoning. The solver scales to large numbers of implicit constraints through (i) online specification of neural constraints, (ii) sparsity-aware active-set detection with parallel batched evaluation across thousands of constraints, and (iii) incremental constraint management for rapid replanning under scene changes.
Online Trajectory Optimization for Arbitrary-Shaped Mobile Robots via Polynomial Separating Hypersurfaces
Jan 14, 2026An emerging class of trajectory optimization methods enforces collision avoidance by jointly optimizing the robot's configuration and a separating hyperplane. However, as linear separators only apply to convex sets, these methods require convex approximations of both the robot and obstacles, which becomes an overly conservative assumption in cluttered and narrow environments. In this work, we unequivocally remove this limitation by introducing nonlinear separating hypersurfaces parameterized by polynomial functions. We first generalize the classical separating hyperplane theorem and prove that any two disjoint bounded closed sets in Euclidean space can be separated by a polynomial hypersurface, serving as the theoretical foundation for nonlinear separation of arbitrary geometries. Building on this result, we formulate a nonlinear programming (NLP) problem that jointly optimizes the robot's trajectory and the coefficients of the separating polynomials, enabling geometry-aware collision avoidance without conservative convex simplifications. The optimization remains efficiently solvable using standard NLP solvers. Simulation and real-world experiments with nonconvex robots demonstrate that our method achieves smooth, collision-free, and agile maneuvers in environments where convex-approximation baselines fail.
Robust Egocentric Referring Video Object Segmentation via Dual-Modal Causal Intervention
Dec 30, 2025Egocentric Referring Video Object Segmentation (Ego-RVOS) aims to segment the specific object actively involved in a human action, as described by a language query, within first-person videos. This task is critical for understanding egocentric human behavior. However, achieving such segmentation robustly is challenging due to ambiguities inherent in egocentric videos and biases present in training data. Consequently, existing methods often struggle, learning spurious correlations from skewed object-action pairings in datasets and fundamental visual confounding factors of the egocentric perspective, such as rapid motion and frequent occlusions. To address these limitations, we introduce Causal Ego-REferring Segmentation (CERES), a plug-in causal framework that adapts strong, pre-trained RVOS backbones to the egocentric domain. CERES implements dual-modal causal intervention: applying backdoor adjustment principles to counteract language representation biases learned from dataset statistics, and leveraging front-door adjustment concepts to address visual confounding by intelligently integrating semantic visual features with geometric depth information guided by causal principles, creating representations more robust to egocentric distortions. Extensive experiments demonstrate that CERES achieves state-of-the-art performance on Ego-RVOS benchmarks, highlighting the potential of applying causal reasoning to build more reliable models for broader egocentric video understanding.
Local Reactive Control for Mobile Manipulators with Whole-Body Safety in Complex Environments
Jan 06, 2025



Mobile manipulators typically encounter significant challenges in navigating narrow, cluttered environments due to their high-dimensional state spaces and complex kinematics. While reactive methods excel in dynamic settings, they struggle to efficiently incorporate complex, coupled constraints across the entire state space. In this work, we present a novel local reactive controller that reformulates the time-domain single-step problem into a multi-step optimization problem in the spatial domain, leveraging the propagation of a serial kinematic chain. This transformation facilitates the formulation of customized, decoupled link-specific constraints, which is further solved efficiently with augmented Lagrangian differential dynamic programming (AL-DDP). Our approach naturally absorbs spatial kinematic propagation in the forward pass and processes all link-specific constraints simultaneously during the backward pass, enhancing both constraint management and computational efficiency. Notably, in this framework, we formulate collision avoidance constraints for each link using accurate geometric models with extracted free regions, and this improves the maneuverability of the mobile manipulator in narrow, cluttered spaces. Experimental results showcase significant improvements in safety, efficiency, and task completion rates. These findings underscore the robustness of the proposed method, particularly in narrow, cluttered environments where conventional approaches could falter. The open-source project can be found at https://github.com/Chunx1nZHENG/MM-with-Whole-Body-Safety-Release.git.
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024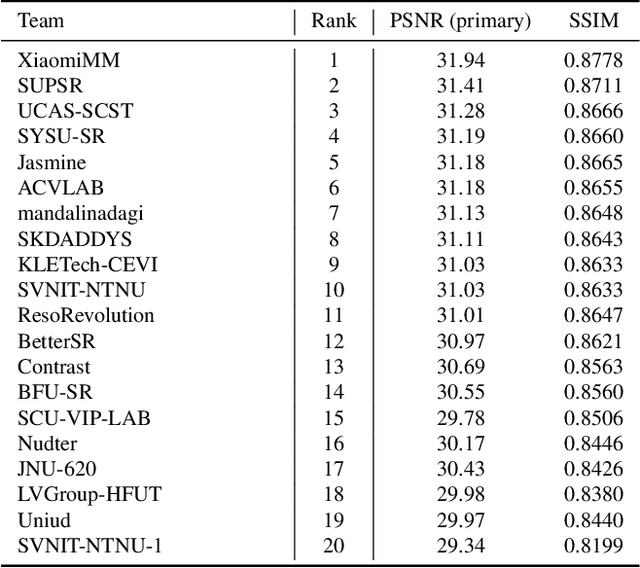
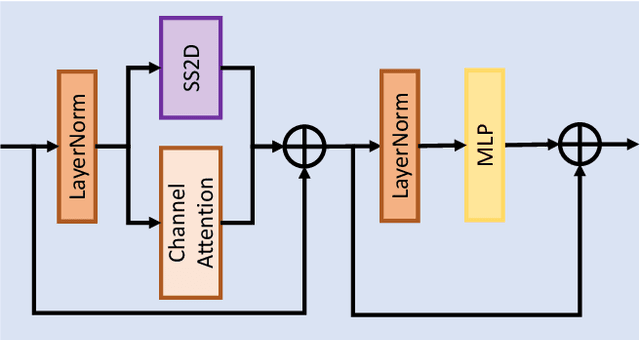
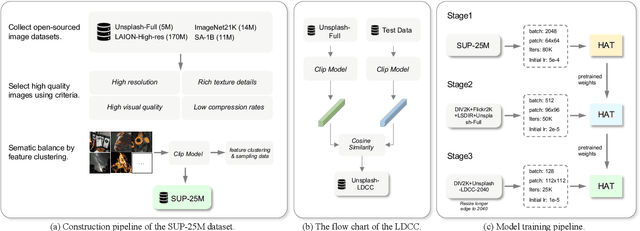
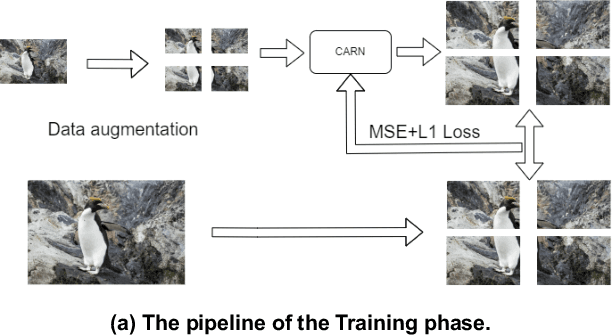
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
LoG-CAN: local-global Class-aware Network for semantic segmentation of remote sensing images
Mar 14, 2023



Remote sensing images are known of having complex backgrounds, high intra-class variance and large variation of scales, which bring challenge to semantic segmentation. We present LoG-CAN, a multi-scale semantic segmentation network with a global class-aware (GCA) module and local class-aware (LCA) modules to remote sensing images. Specifically, the GCA module captures the global representations of class-wise context modeling to circumvent background interference; the LCA modules generate local class representations as intermediate aware elements, indirectly associating pixels with global class representations to reduce variance within a class; and a multi-scale architecture with GCA and LCA modules yields effective segmentation of objects at different scales via cascaded refinement and fusion of features. Through the evaluation on the ISPRS Vaihingen dataset and the ISPRS Potsdam dataset, experimental results indicate that LoG-CAN outperforms the state-of-the-art methods for general semantic segmentation, while significantly reducing network parameters and computation. Code is available at~\href{https://github.com/xwmaxwma/rssegmentation}{https://github.com/xwmaxwma/rssegmentation}.
GRATIS: Deep Learning Graph Representation with Task-specific Topology and Multi-dimensional Edge Features
Nov 19, 2022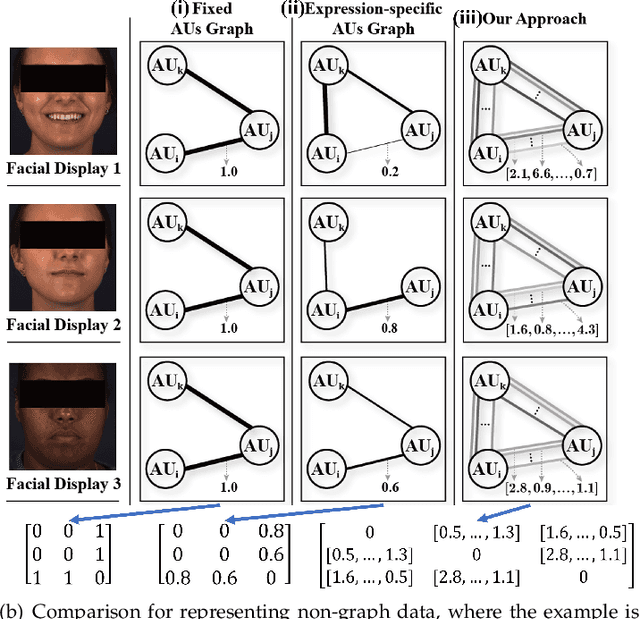
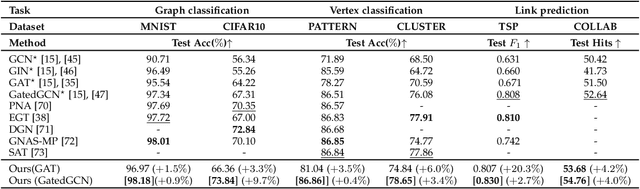
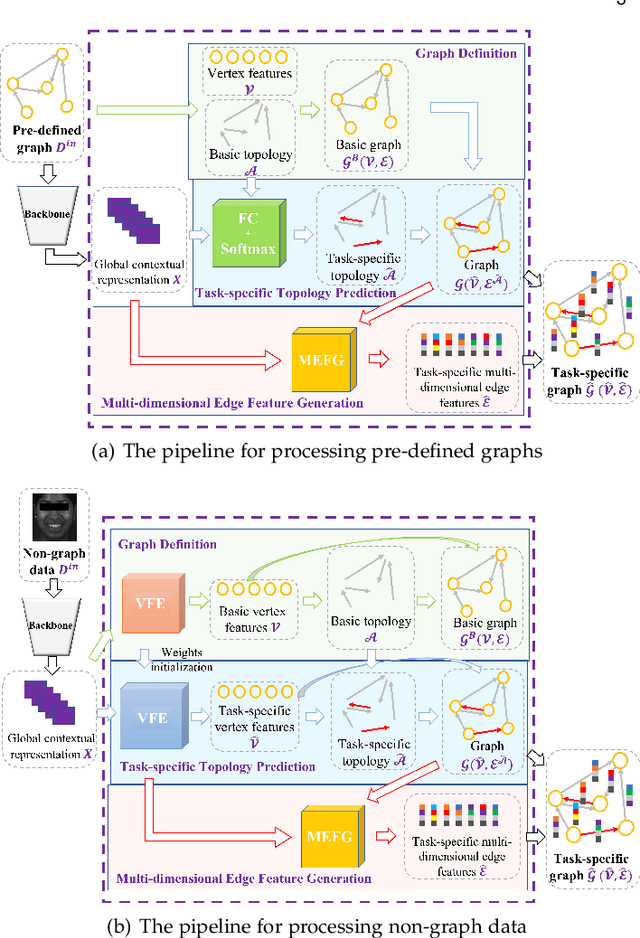
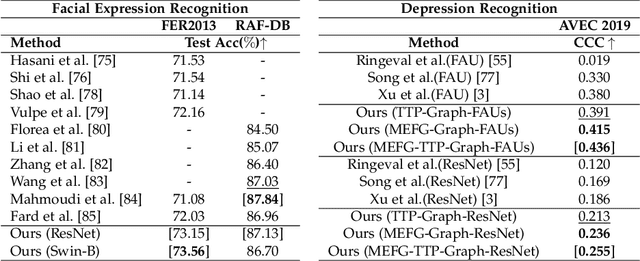
Graph is powerful for representing various types of real-world data. The topology (edges' presence) and edges' features of a graph decides the message passing mechanism among vertices within the graph. While most existing approaches only manually define a single-value edge to describe the connectivity or strength of association between a pair of vertices, task-specific and crucial relationship cues may be disregarded by such manually defined topology and single-value edge features. In this paper, we propose the first general graph representation learning framework (called GRATIS) which can generate a strong graph representation with a task-specific topology and task-specific multi-dimensional edge features from any arbitrary input. To learn each edge's presence and multi-dimensional feature, our framework takes both of the corresponding vertices pair and their global contextual information into consideration, enabling the generated graph representation to have a globally optimal message passing mechanism for different down-stream tasks. The principled investigation results achieved for various graph analysis tasks on 11 graph and non-graph datasets show that our GRATIS can not only largely enhance pre-defined graphs but also learns a strong graph representation for non-graph data, with clear performance improvements on all tasks. In particular, the learned topology and multi-dimensional edge features provide complementary task-related cues for graph analysis tasks. Our framework is effective, robust and flexible, and is a plug-and-play module that can be combined with different backbones and Graph Neural Networks (GNNs) to generate a task-specific graph representation from various graph and non-graph data. Our code is made publicly available at https://github.com/SSYSteve/Learning-Graph-Representation-with-Task-specific-Topology-and-Multi-dimensional-Edge-Features.