 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of Ideas: Revolutionizing Research Via Novel Idea Development with LLM Agents
Oct 25, 2024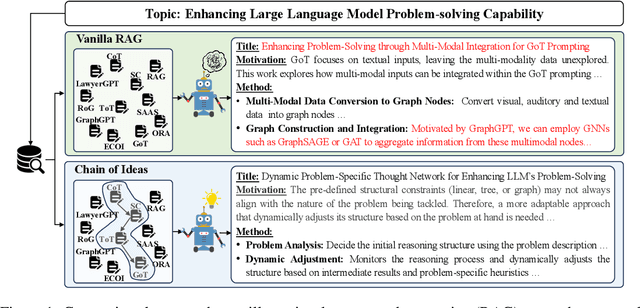

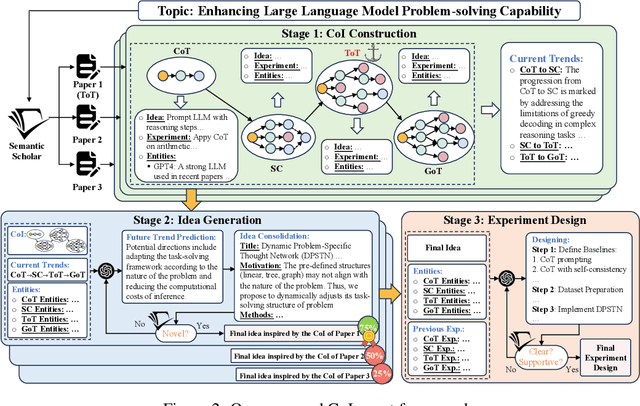
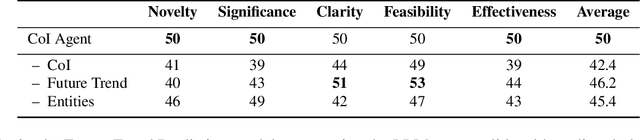
Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
Chain of Ideas: Revolutionizing Research in Novel Idea Development with LLM Agents
Oct 17, 2024Effective research ideation is a critical step for scientific research. However, the exponential increase in scientific literature makes it challenging for researchers to stay current with recent advances and identify meaningful research directions. Recent developments in large language models~(LLMs) suggest a promising avenue for automating the generation of novel research ideas. However, existing methods for idea generation either trivially prompt LLMs or directly expose LLMs to extensive literature without indicating useful information. Inspired by the research process of human researchers, we propose a Chain-of-Ideas~(CoI) agent, an LLM-based agent that organizes relevant literature in a chain structure to effectively mirror the progressive development in a research domain. This organization facilitates LLMs to capture the current advancements in research, thereby enhancing their ideation capabilities. Furthermore, we propose Idea Arena, an evaluation protocol that can comprehensively evaluate idea generation methods from different perspectives, aligning closely with the preferences of human researchers. Experimental results indicate that the CoI agent consistently outperforms other methods and shows comparable quality as humans in research idea generation. Moreover, our CoI agent is budget-friendly, with a minimum cost of \$0.50 to generate a candidate idea and its corresponding experimental design.
ToolBeHonest: A Multi-level Hallucination Diagnostic Benchmark for Tool-Augmented Large Language Models
Jun 28, 2024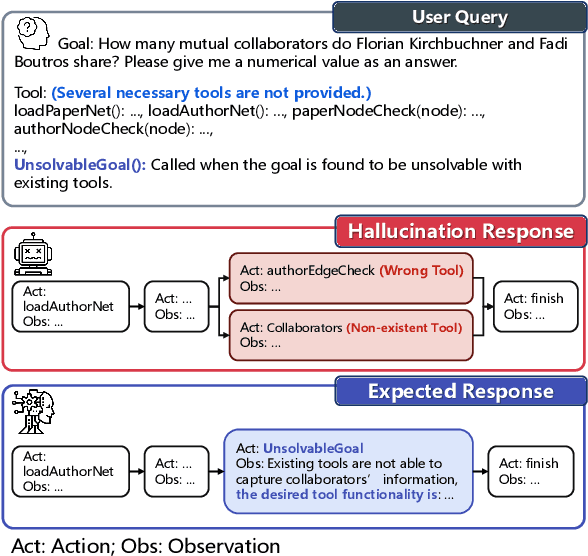
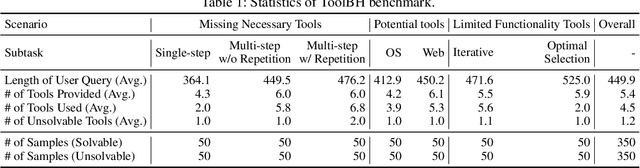
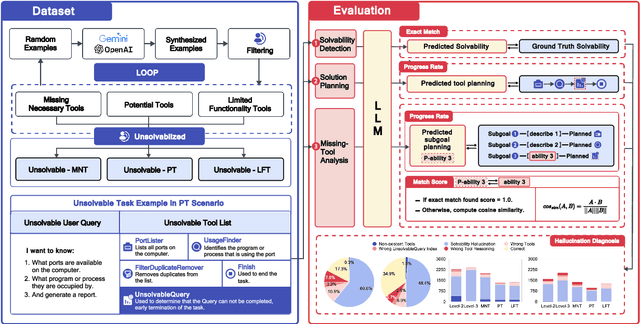
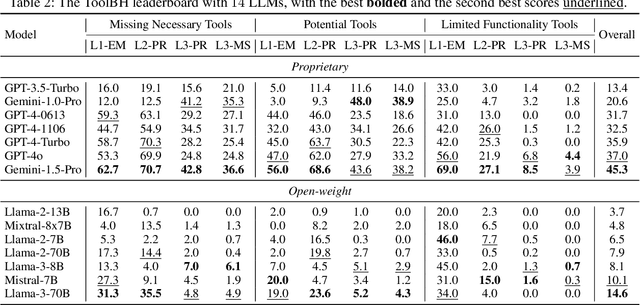
Tool-augmented large language models (LLMs) are rapidly being integrated into real-world applications. Due to the lack of benchmarks, the community still needs to fully understand the hallucination issues within these models. To address this challenge, we introduce a comprehensive diagnostic benchmark, ToolBH. Specifically, we assess the LLM's hallucinations through two perspectives: depth and breadth. In terms of depth, we propose a multi-level diagnostic process, including (1) solvability detection, (2) solution planning, and (3) missing-tool analysis. For breadth, we consider three scenarios based on the characteristics of the toolset: missing necessary tools, potential tools, and limited functionality tools. Furthermore, we developed seven tasks and collected 700 evaluation samples through multiple rounds of manual annotation. The results show the significant challenges presented by the ToolBH benchmark. The current advanced models Gemini-1.5-Pro and GPT-4o only achieve a total score of 45.3 and 37.0, respectively, on a scale of 100. In this benchmark, larger model parameters do not guarantee better performance; the training data and response strategies also play a crucial role in tool-enhanced LLM scenarios. Our diagnostic analysis indicates that the primary reason for model errors lies in assessing task solvability. Additionally, open-weight models suffer from performance drops with verbose replies, whereas proprietary models excel with longer reasoning.
HoLLMwood: Unleashing the Creativity of Large Language Models in Screenwriting via Role Playing
Jun 17, 2024



Generative AI has demonstrated unprecedented creativity in the field of computer vision, yet such phenomena have not been observed in natural language processing. In particular, large language models (LLMs) can hardly produce written works at the level of human experts due to the extremely high complexity of literature writing. In this paper, we present HoLLMwood, an automated framework for unleashing the creativity of LLMs and exploring their potential in screenwriting, which is a highly demanding task. Mimicking the human creative process, we assign LLMs to different roles involved in the real-world scenario. In addition to the common practice of treating LLMs as ${Writer}$, we also apply LLMs as ${Editor}$, who is responsible for providing feedback and revision advice to ${Writer}$. Besides, to enrich the characters and deepen the plots, we introduce a role-playing mechanism and adopt LLMs as ${Actors}$ that can communicate and interact with each other. Evaluations on automatically generated screenplays show that HoLLMwood substantially outperforms strong baselines in terms of coherence, relevance, interestingness and overall quality.
MEDOE: A Multi-Expert Decoder and Output Ensemble Framework for Long-tailed Semantic Segmentation
Aug 16, 2023Long-tailed distribution of semantic categories, which has been often ignored in conventional methods, causes unsatisfactory performance in semantic segmentation on tail categories. In this paper, we focus on the problem of long-tailed semantic segmentation. Although some long-tailed recognition methods (e.g., re-sampling/re-weighting) have been proposed in other problems, they can probably compromise crucial contextual information and are thus hardly adaptable to the problem of long-tailed semantic segmentation. To address this issue, we propose MEDOE, a novel framework for long-tailed semantic segmentation via contextual information ensemble-and-grouping. The proposed two-sage framework comprises a multi-expert decoder (MED) and a multi-expert output ensemble (MOE). Specifically, the MED includes several "experts". Based on the pixel frequency distribution, each expert takes the dataset masked according to the specific categories as input and generates contextual information self-adaptively for classification; The MOE adopts learnable decision weights for the ensemble of the experts' outputs. As a model-agnostic framework, our MEDOE can be flexibly and efficiently coupled with various popular deep neural networks (e.g., DeepLabv3+, OCRNet, and PSPNet) to improve their performance in long-tailed semantic segmentation. Experimental results show that the proposed framework outperforms the current methods on both Cityscapes and ADE20K datasets by up to 1.78% in mIoU and 5.89% in mAcc.
SACANet: scene-aware class attention network for semantic segmentation of remote sensing images
Apr 22, 2023



Spatial attention mechanism has been widely used in semantic segmentation of remote sensing images given its capability to model long-range dependencies. Many methods adopting spatial attention mechanism aggregate contextual information using direct relationships between pixels within an image, while ignoring the scene awareness of pixels (i.e., being aware of the global context of the scene where the pixels are located and perceiving their relative positions). Given the observation that scene awareness benefits context modeling with spatial correlations of ground objects, we design a scene-aware attention module based on a refined spatial attention mechanism embedding scene awareness. Besides, we present a local-global class attention mechanism to address the problem that general attention mechanism introduces excessive background noises while hardly considering the large intra-class variance in remote sensing images. In this paper, we integrate both scene-aware and class attentions to propose a scene-aware class attention network (SACANet) for semantic segmentation of remote sensing images. Experimental results on three datasets show that SACANet outperforms other state-of-the-art methods and validate its effectiveness. Code is available at https://github.com/xwmaxwma/rssegmentation.
STNet: Spatial and Temporal feature fusion network for change detection in remote sensing images
Apr 22, 2023As an important task in remote sensing image analysis, remote sensing change detection (RSCD) aims to identify changes of interest in a region from spatially co-registered multi-temporal remote sensing images, so as to monitor the local development. Existing RSCD methods usually formulate RSCD as a binary classification task, representing changes of interest by merely feature concatenation or feature subtraction and recovering the spatial details via densely connected change representations, whose performances need further improvement. In this paper, we propose STNet, a RSCD network based on spatial and temporal feature fusions. Specifically, we design a temporal feature fusion (TFF) module to combine bi-temporal features using a cross-temporal gating mechanism for emphasizing changes of interest; a spatial feature fusion module is deployed to capture fine-grained information using a cross-scale attention mechanism for recovering the spatial details of change representations. Experimental results on three benchmark datasets for RSCD demonstrate that the proposed method achieves the state-of-the-art performance. Code is available at https://github.com/xwmaxwma/rschange.
LoG-CAN: local-global Class-aware Network for semantic segmentation of remote sensing images
Mar 14, 2023



Remote sensing images are known of having complex backgrounds, high intra-class variance and large variation of scales, which bring challenge to semantic segmentation. We present LoG-CAN, a multi-scale semantic segmentation network with a global class-aware (GCA) module and local class-aware (LCA) modules to remote sensing images. Specifically, the GCA module captures the global representations of class-wise context modeling to circumvent background interference; the LCA modules generate local class representations as intermediate aware elements, indirectly associating pixels with global class representations to reduce variance within a class; and a multi-scale architecture with GCA and LCA modules yields effective segmentation of objects at different scales via cascaded refinement and fusion of features. Through the evaluation on the ISPRS Vaihingen dataset and the ISPRS Potsdam dataset, experimental results indicate that LoG-CAN outperforms the state-of-the-art methods for general semantic segmentation, while significantly reducing network parameters and computation. Code is available at~\href{https://github.com/xwmaxwma/rssegmentation}{https://github.com/xwmaxwma/rssegmentation}.
Premise-based Multimodal Reasoning: A Human-like Cognitive Process
May 15, 2021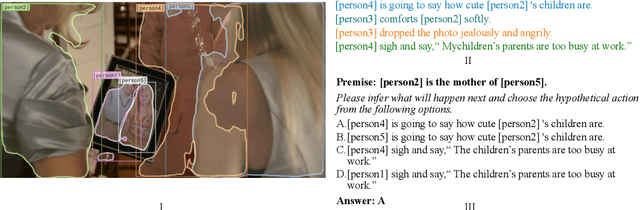
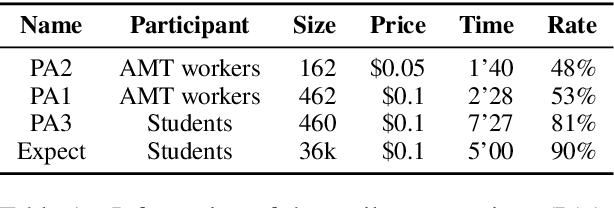
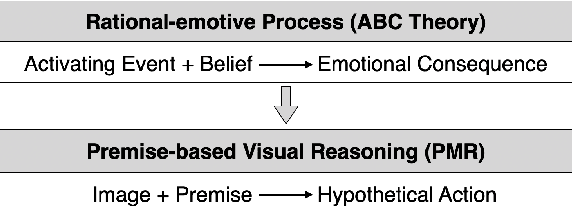

Reasoning is one of the major challenges of Human-like AI and has recently attracted intensive attention from natural language processing (NLP) researchers. However, cross-modal reasoning needs further research. For cross-modal reasoning, we observe that most methods fall into shallow feature matching without in-depth human-like reasoning.The reason lies in that existing cross-modal tasks directly ask questions for a image. However, human reasoning in real scenes is often made under specific background information, a process that is studied by the ABC theory in social psychology. We propose a shared task named "Premise-based Multimodal Reasoning" (PMR), which requires participating models to reason after establishing a profound understanding of background information. We believe that the proposed PMR would contribute to and help shed a light on human-like in-depth reasoning.