 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Drop: Generalizable Fine-tuning for Pre-trained Language Models via Adaptive Subnetwork Optimization
May 24, 2023



Pretrained language models have achieved remarkable success in a variety of natural language understanding tasks. Nevertheless, finetuning large pretrained models on downstream tasks is susceptible to overfitting if the training set is limited, which will lead to diminished performance. In this work, we propose a dynamic fine-tuning strategy for pretrained language models called Bi-Drop. It utilizes the gradient information of various sub-models generated by dropout to update the model parameters selectively. Experiments on the GLUE benchmark show that Bi-Drop outperforms previous fine-tuning methods by a considerable margin, and exhibits consistent superiority over vanilla fine-tuning across various pretrained models. Furthermore, empirical results indicate that Bi-Drop yields substantial improvements in the multiple task or domain transfer, data imbalance, and low-resource scenarios, demonstrating superb generalization ability and robustness.
Robust Fine-tuning via Perturbation and Interpolation from In-batch Instances
May 02, 2022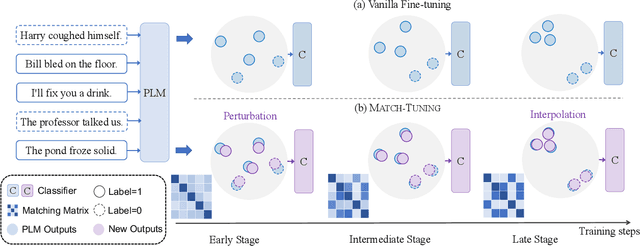
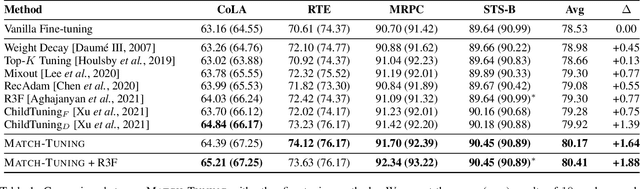
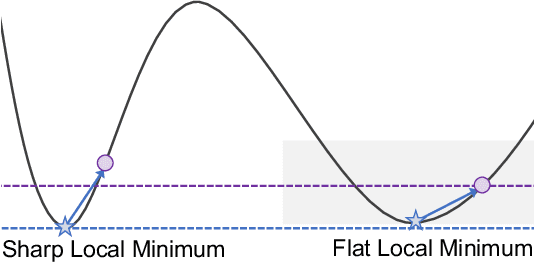

Fine-tuning pretrained language models (PLMs) on downstream tasks has become common practice in natural language processing. However, most of the PLMs are vulnerable, e.g., they are brittle under adversarial attacks or imbalanced data, which hinders the application of the PLMs on some downstream tasks, especially in safe-critical scenarios. In this paper, we propose a simple yet effective fine-tuning method called Match-Tuning to force the PLMs to be more robust. For each instance in a batch, we involve other instances in the same batch to interact with it. To be specific, regarding the instances with other labels as a perturbation, Match-Tuning makes the model more robust to noise at the beginning of training. While nearing the end, Match-Tuning focuses more on performing an interpolation among the instances with the same label for better generalization. Extensive experiments on various tasks in GLUE benchmark show that Match-Tuning consistently outperforms the vanilla fine-tuning by $1.64$ scores. Moreover, Match-Tuning exhibits remarkable robustness to adversarial attacks and data imbalance.
Premise-based Multimodal Reasoning: A Human-like Cognitive Process
May 15, 2021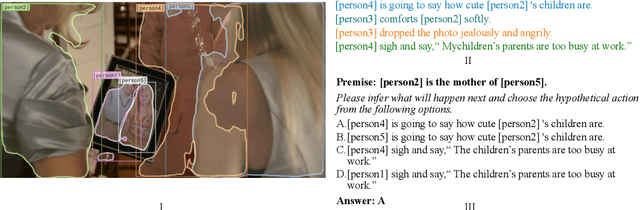
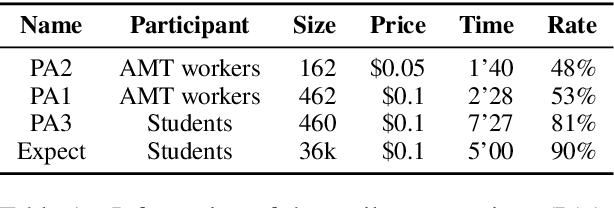
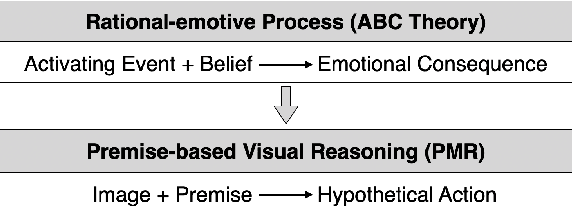

Reasoning is one of the major challenges of Human-like AI and has recently attracted intensive attention from natural language processing (NLP) researchers. However, cross-modal reasoning needs further research. For cross-modal reasoning, we observe that most methods fall into shallow feature matching without in-depth human-like reasoning.The reason lies in that existing cross-modal tasks directly ask questions for a image. However, human reasoning in real scenes is often made under specific background information, a process that is studied by the ABC theory in social psychology. We propose a shared task named "Premise-based Multimodal Reasoning" (PMR), which requires participating models to reason after establishing a profound understanding of background information. We believe that the proposed PMR would contribute to and help shed a light on human-like in-depth reasoning.