 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecode Neural signal as Speech
Paper and Code
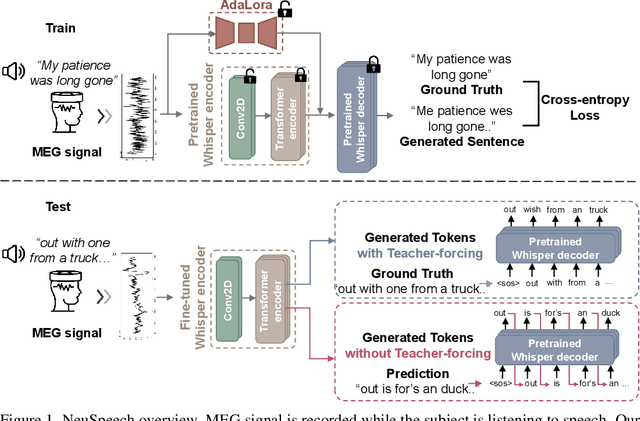
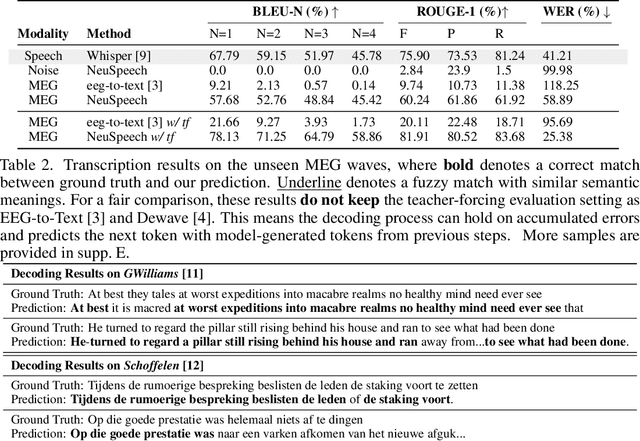
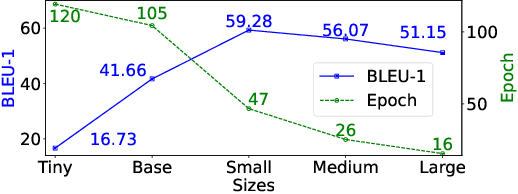
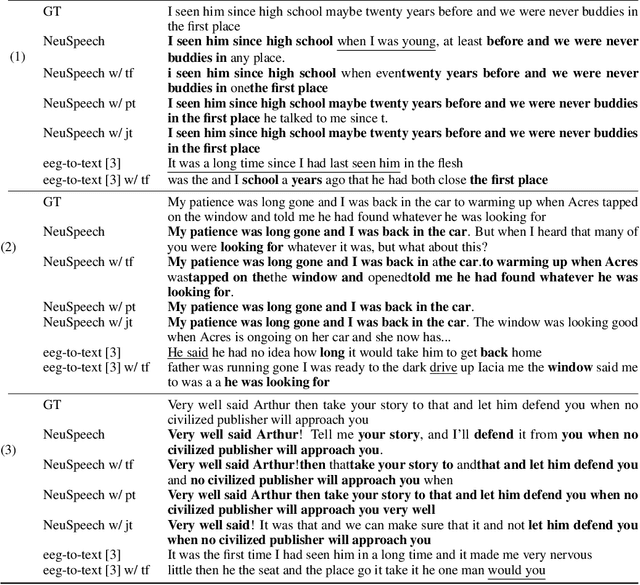
Decoding language from brain dynamics is an important open direction in the realm of brain-computer interface (BCI), especially considering the rapid growth of large language models. Compared to invasive-based signals which require electrode implantation surgery, non-invasive neural signals (e.g. EEG, MEG) have attracted increasing attention considering their safety and generality. However, the exploration is not adequate in three aspects: 1) previous methods mainly focus on EEG but none of the previous works address this problem on MEG with better signal quality; 2) prior works have predominantly used ``teacher-forcing" during generative decoding, which is impractical; 3) prior works are mostly ``BART-based" not fully auto-regressive, which performs better in other sequence tasks. In this paper, we explore the brain-to-text translation of MEG signals in a speech-decoding formation. Here we are the first to investigate a cross-attention-based ``whisper" model for generating text directly from MEG signals without teacher forcing. Our model achieves impressive BLEU-1 scores of 60.30 and 52.89 without pretraining \& teacher-forcing on two major datasets (\textit{GWilliams} and \textit{Schoffelen}). This paper conducts a comprehensive review to understand how speech decoding formation performs on the neural decoding tasks, including pretraining initialization, training \& evaluation set splitting, augmentation, and scaling law.