 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoor Obstacle Discovery on Reflective Ground via Monocular Camera
Jan 02, 2024Visual obstacle discovery is a key step towards autonomous navigation of indoor mobile robots. Successful solutions have many applications in multiple scenes. One of the exceptions is the reflective ground. In this case, the reflections on the floor resemble the true world, which confuses the obstacle discovery and leaves navigation unsuccessful. We argue that the key to this problem lies in obtaining discriminative features for reflections and obstacles. Note that obstacle and reflection can be separated by the ground plane in 3D space. With this observation, we firstly introduce a pre-calibration based ground detection scheme that uses robot motion to predict the ground plane. Due to the immunity of robot motion to reflection, this scheme avoids failed ground detection caused by reflection. Given the detected ground, we design a ground-pixel parallax to describe the location of a pixel relative to the ground. Based on this, a unified appearance-geometry feature representation is proposed to describe objects inside rectangular boxes. Eventually, based on segmenting by detection framework, an appearance-geometry fusion regressor is designed to utilize the proposed feature to discover the obstacles. It also prevents our model from concentrating too much on parts of obstacles instead of whole obstacles. For evaluation, we introduce a new dataset for Obstacle on Reflective Ground (ORG), which comprises 15 scenes with various ground reflections, a total of more than 200 image sequences and 3400 RGB images. The pixel-wise annotations of ground and obstacle provide a comparison to our method and other methods. By reducing the misdetection of the reflection, the proposed approach outperforms others. The source code and the dataset will be available at https://github.com/XuefengBUPT/IndoorObstacleDiscovery-RG.
Monocular Depth Distribution Alignment with Low Computation
Mar 09, 2022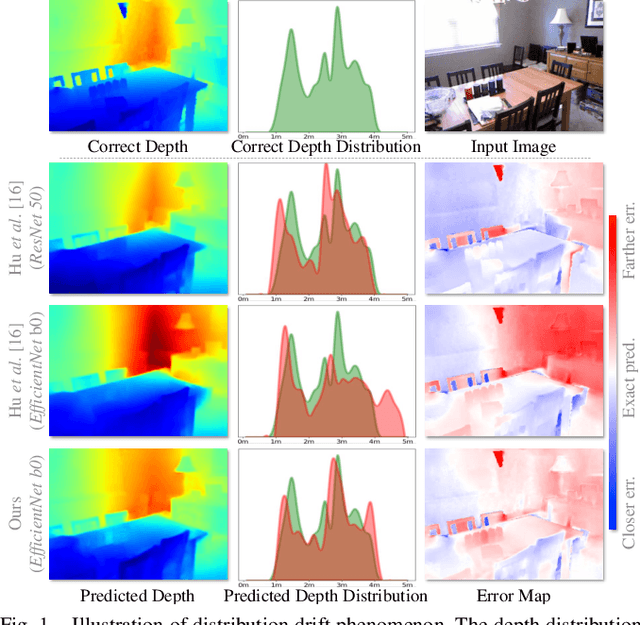
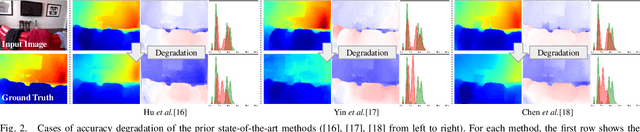
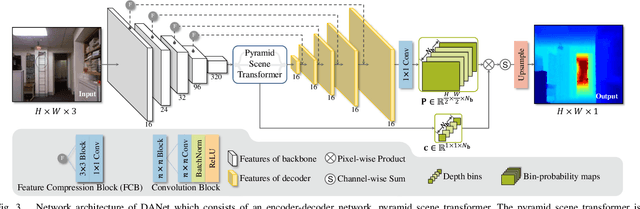
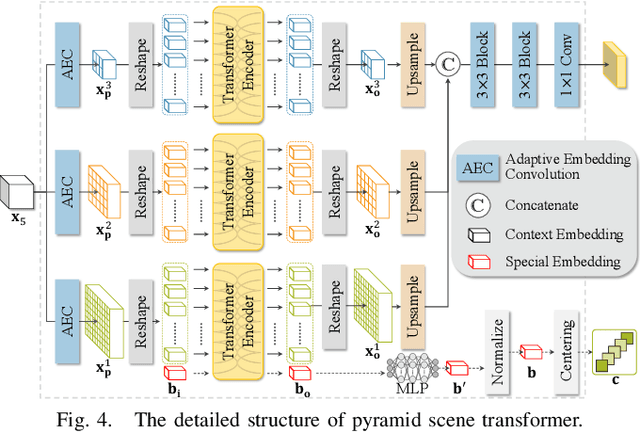
The performance of monocular depth estimation generally depends on the amount of parameters and computational cost. It leads to a large accuracy contrast between light-weight networks and heavy-weight networks, which limits their application in the real world. In this paper, we model the majority of accuracy contrast between them as the difference of depth distribution, which we call "Distribution drift". To this end, a distribution alignment network (DANet) is proposed. We firstly design a pyramid scene transformer (PST) module to capture inter-region interaction in multiple scales. By perceiving the difference of depth features between every two regions, DANet tends to predict a reasonable scene structure, which fits the shape of distribution to ground truth. Then, we propose a local-global optimization (LGO) scheme to realize the supervision of global range of scene depth. Thanks to the alignment of depth distribution shape and scene depth range, DANet sharply alleviates the distribution drift, and achieves a comparable performance with prior heavy-weight methods, but uses only 1% floating-point operations per second (FLOPs) of them. The experiments on two datasets, namely the widely used NYUDv2 dataset and the more challenging iBims-1 dataset, demonstrate the effectiveness of our method. The source code is available at https://github.com/YiLiM1/DANet.
Fast Road Segmentation via Uncertainty-aware Symmetric Network
Mar 09, 2022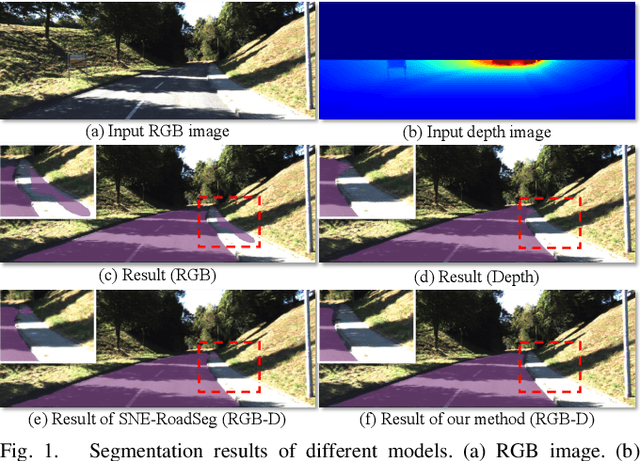
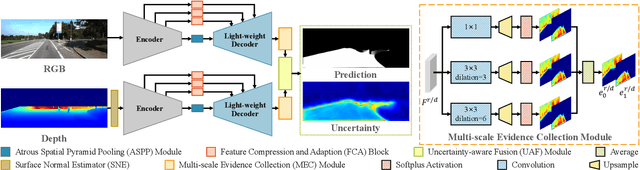

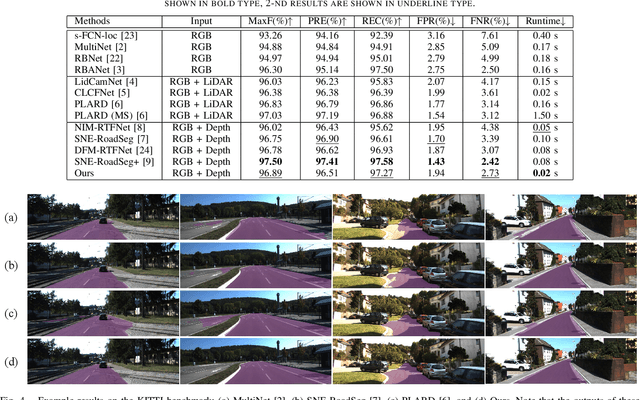
The high performance of RGB-D based road segmentation methods contrasts with their rare application in commercial autonomous driving, which is owing to two reasons: 1) the prior methods cannot achieve high inference speed and high accuracy in both ways; 2) the different properties of RGB and depth data are not well-exploited, limiting the reliability of predicted road. In this paper, based on the evidence theory, an uncertainty-aware symmetric network (USNet) is proposed to achieve a trade-off between speed and accuracy by fully fusing RGB and depth data. Firstly, cross-modal feature fusion operations, which are indispensable in the prior RGB-D based methods, are abandoned. We instead separately adopt two light-weight subnetworks to learn road representations from RGB and depth inputs. The light-weight structure guarantees the real-time inference of our method. Moreover, a multiscale evidence collection (MEC) module is designed to collect evidence in multiple scales for each modality, which provides sufficient evidence for pixel class determination. Finally, in uncertainty-aware fusion (UAF) module, the uncertainty of each modality is perceived to guide the fusion of the two subnetworks. Experimental results demonstrate that our method achieves a state-of-the-art accuracy with real-time inference speed of 43+ FPS. The source code is available at https://github.com/morancyc/USNet.