 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnknown Sniffer for Object Detection: Don't Turn a Blind Eye to Unknown Objects
Mar 24, 2023The recently proposed open-world object and open-set detection achieve a breakthrough in finding never-seen-before objects and distinguishing them from class-known ones. However, their studies on knowledge transfer from known classes to unknown ones need to be deeper, leading to the scanty capability for detecting unknowns hidden in the background. In this paper, we propose the unknown sniffer (UnSniffer) to find both unknown and known objects. Firstly, the generalized object confidence (GOC) score is introduced, which only uses class-known samples for supervision and avoids improper suppression of unknowns in the background. Significantly, such confidence score learned from class-known objects can be generalized to unknown ones. Additionally, we propose a negative energy suppression loss to further limit the non-object samples in the background. Next, the best box of each unknown is hard to obtain during inference due to lacking their semantic information in training. To solve this issue, we introduce a graph-based determination scheme to replace hand-designed non-maximum suppression (NMS) post-processing. Finally, we present the Unknown Object Detection Benchmark, the first publicly benchmark that encompasses precision evaluation for unknown object detection to our knowledge. Experiments show that our method is far better than the existing state-of-the-art methods. Code is available at: https://github.com/Went-Liang/UnSniffer.
Monocular Depth Distribution Alignment with Low Computation
Mar 09, 2022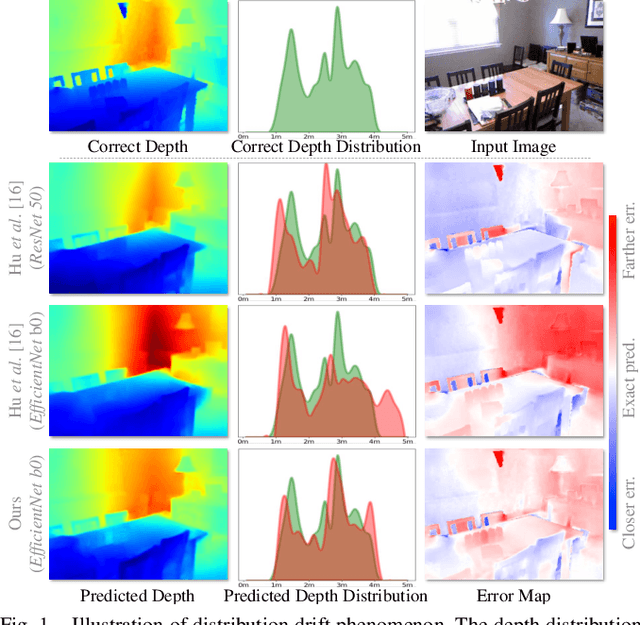
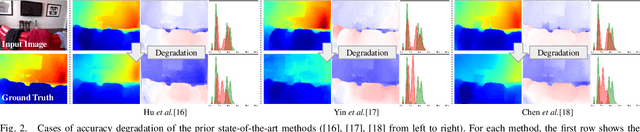
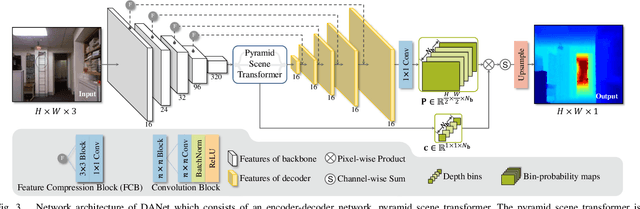
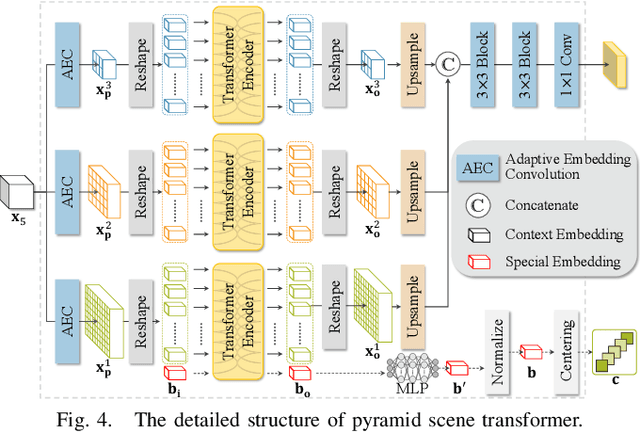
The performance of monocular depth estimation generally depends on the amount of parameters and computational cost. It leads to a large accuracy contrast between light-weight networks and heavy-weight networks, which limits their application in the real world. In this paper, we model the majority of accuracy contrast between them as the difference of depth distribution, which we call "Distribution drift". To this end, a distribution alignment network (DANet) is proposed. We firstly design a pyramid scene transformer (PST) module to capture inter-region interaction in multiple scales. By perceiving the difference of depth features between every two regions, DANet tends to predict a reasonable scene structure, which fits the shape of distribution to ground truth. Then, we propose a local-global optimization (LGO) scheme to realize the supervision of global range of scene depth. Thanks to the alignment of depth distribution shape and scene depth range, DANet sharply alleviates the distribution drift, and achieves a comparable performance with prior heavy-weight methods, but uses only 1% floating-point operations per second (FLOPs) of them. The experiments on two datasets, namely the widely used NYUDv2 dataset and the more challenging iBims-1 dataset, demonstrate the effectiveness of our method. The source code is available at https://github.com/YiLiM1/DANet.
Fast Road Segmentation via Uncertainty-aware Symmetric Network
Mar 09, 2022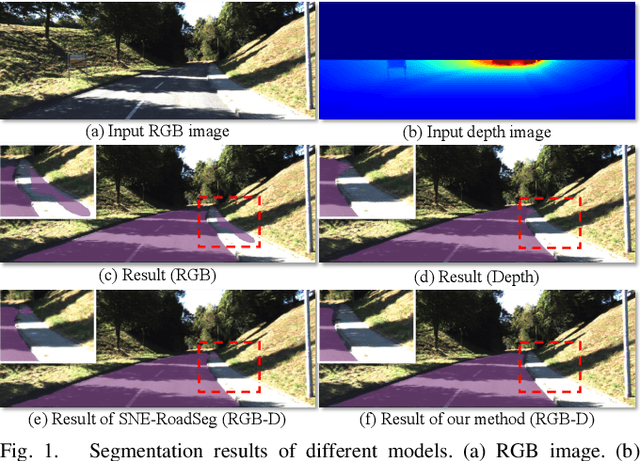
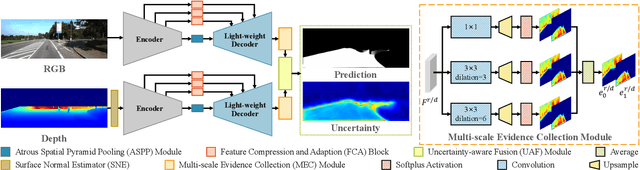

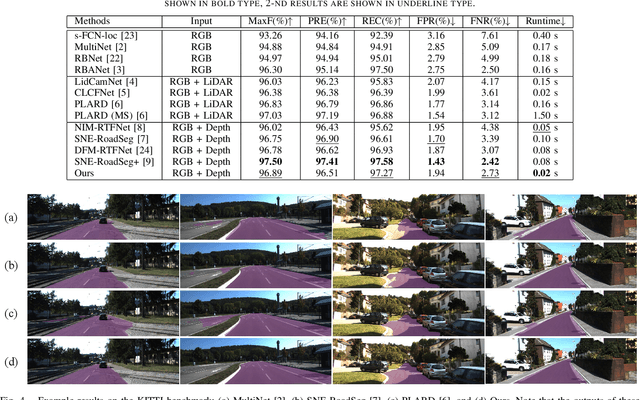
The high performance of RGB-D based road segmentation methods contrasts with their rare application in commercial autonomous driving, which is owing to two reasons: 1) the prior methods cannot achieve high inference speed and high accuracy in both ways; 2) the different properties of RGB and depth data are not well-exploited, limiting the reliability of predicted road. In this paper, based on the evidence theory, an uncertainty-aware symmetric network (USNet) is proposed to achieve a trade-off between speed and accuracy by fully fusing RGB and depth data. Firstly, cross-modal feature fusion operations, which are indispensable in the prior RGB-D based methods, are abandoned. We instead separately adopt two light-weight subnetworks to learn road representations from RGB and depth inputs. The light-weight structure guarantees the real-time inference of our method. Moreover, a multiscale evidence collection (MEC) module is designed to collect evidence in multiple scales for each modality, which provides sufficient evidence for pixel class determination. Finally, in uncertainty-aware fusion (UAF) module, the uncertainty of each modality is perceived to guide the fusion of the two subnetworks. Experimental results demonstrate that our method achieves a state-of-the-art accuracy with real-time inference speed of 43+ FPS. The source code is available at https://github.com/morancyc/USNet.
MegBA: A High-Performance and Distributed Library for Large-Scale Bundle Adjustment
Dec 10, 2021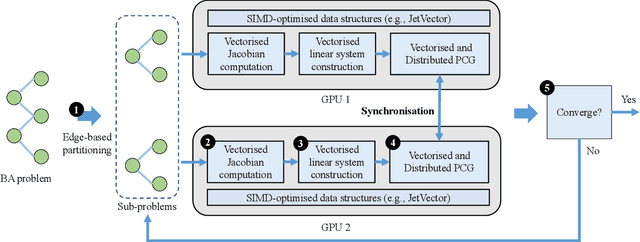
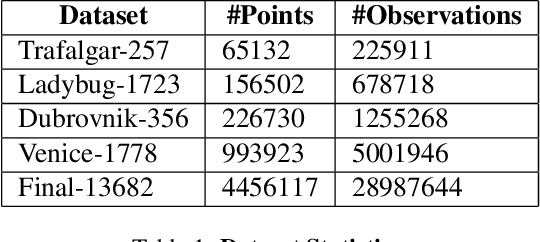
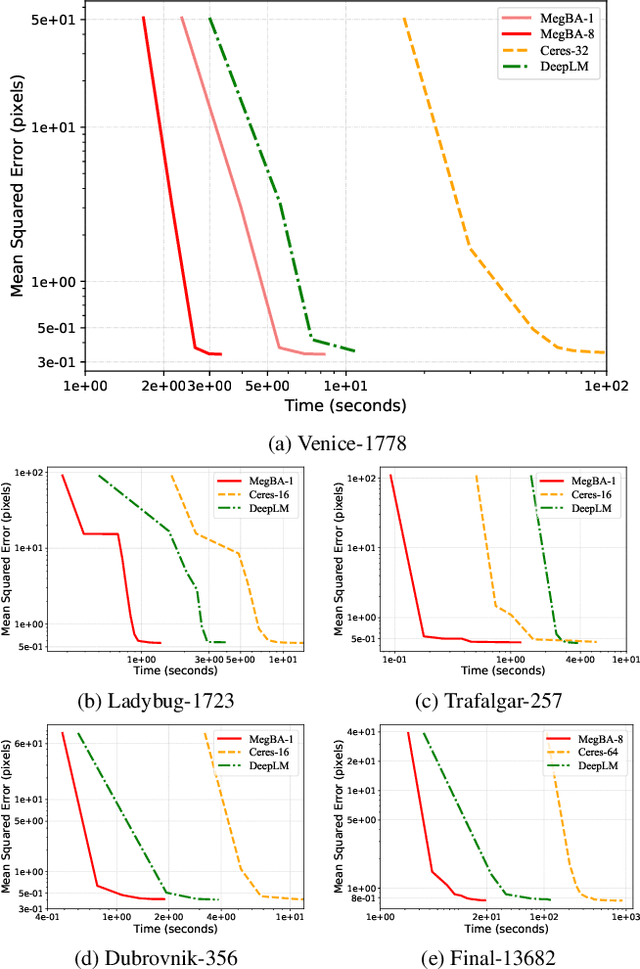
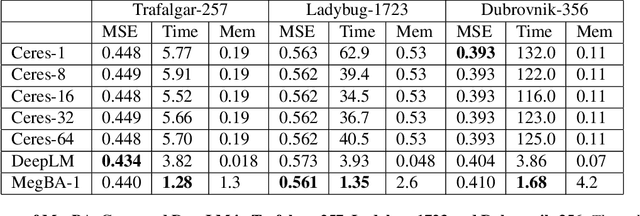
Large-scale Bundle Adjustment (BA) is the key for many 3D vision applications (e.g., Structure-from-Motion and SLAM). Though important, large-scale BA is still poorly supported by existing BA libraries (e.g., Ceres and g2o). These libraries under-utilise accelerators (i.e., GPUs), and they lack algorithms to distribute BA computation constrained by the memory on a single device. In this paper, we propose MegBA, a high-performance and distributed library for large-scale BA. MegBA has a novel end-to-end vectorised BA algorithm that can fully exploit the massive parallel cores on GPUs, thus speeding up the entire BA computation. It also has a novel distributed BA algorithm that can automatically partition BA problems, and solve BA sub-problems using distributed GPUs. The GPUs synchronise intermediate solving state using network-efficient collective communication, and the synchronisation is designed to minimise communication cost. MegBA has a memory-efficient GPU runtime and exposes g2o-compatible APIs. Experiments show that MegBA can out-perform state-of-the-art BA libraries (i.e., Ceres and DeepLM) by up to 47.6x and 6.4x respectively, in public large-scale BA benchmarks. The code of MegBA is available at: https://github.com/MegviiRobot/MegBA.