 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Mask Reference Image Quality Assessment
Mar 19, 2023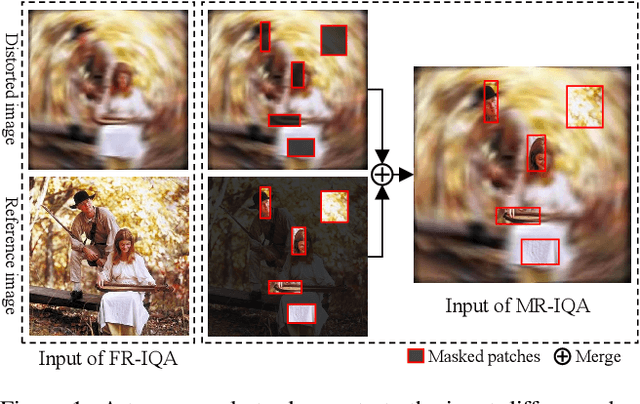
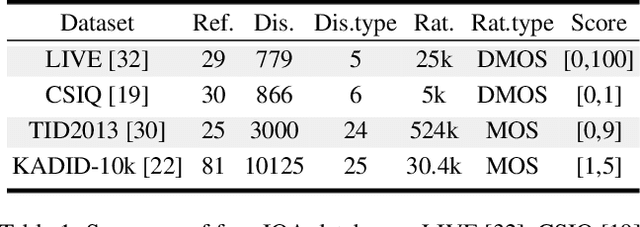
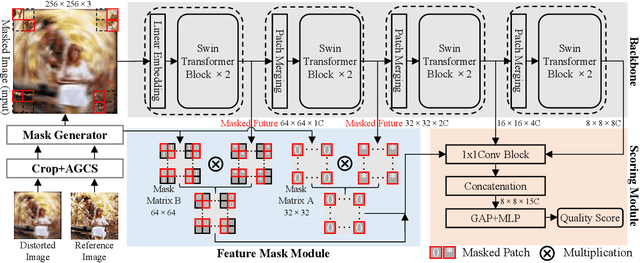
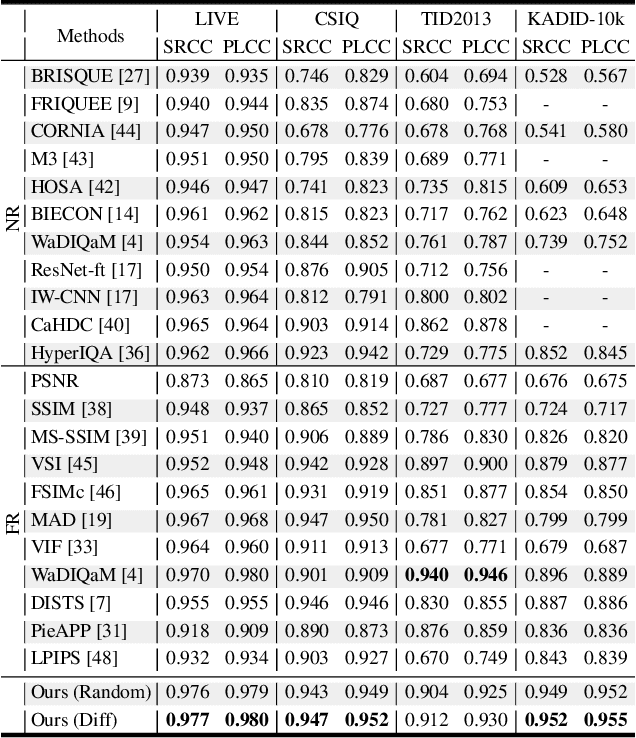
Understanding semantic information is an essential step in knowing what is being learned in both full-reference (FR) and no-reference (NR) image quality assessment (IQA) methods. However, especially for many severely distorted images, even if there is an undistorted image as a reference (FR-IQA), it is difficult to perceive the lost semantic and texture information of distorted images directly. In this paper, we propose a Mask Reference IQA (MR-IQA) method that masks specific patches of a distorted image and supplements missing patches with the reference image patches. In this way, our model only needs to input the reconstructed image for quality assessment. First, we design a mask generator to select the best candidate patches from reference images and supplement the lost semantic information in distorted images, thus providing more reference for quality assessment; in addition, the different masked patches imply different data augmentations, which favors model training and reduces overfitting. Second, we provide a Mask Reference Network (MRNet): the dedicated modules can prevent disturbances due to masked patches and help eliminate the patch discontinuity in the reconstructed image. Our method achieves state-of-the-art performances on the benchmark KADID-10k, LIVE and CSIQ datasets and has better generalization performance across datasets. The code and results are available in the supplementary material.