 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-Induced Generative Incomplete Image-Text Clustering (CIGIT-C)
Sep 28, 2022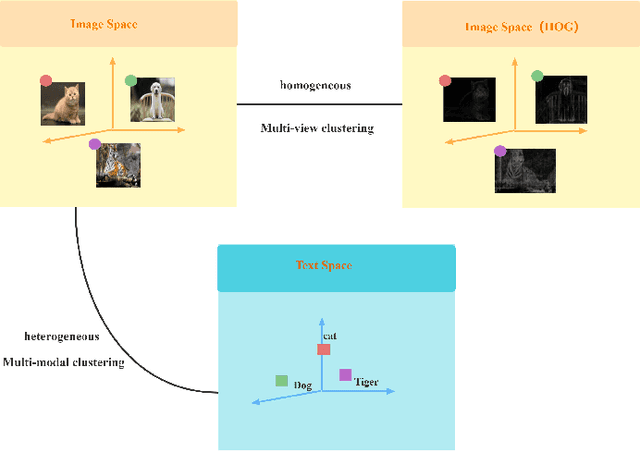
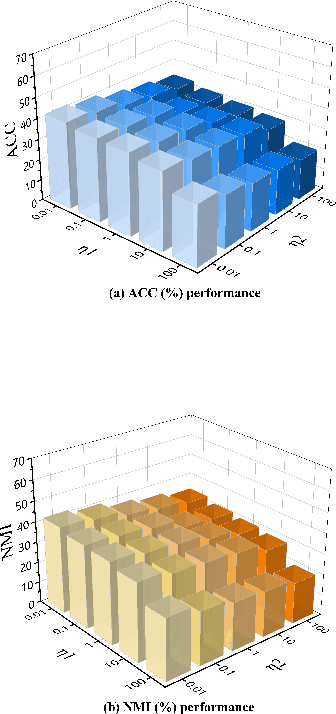
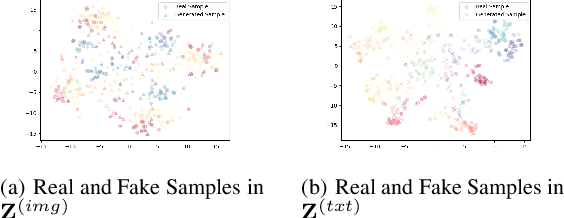

The target of image-text clustering (ITC) is to find correct clusters by integrating complementary and consistent information of multi-modalities for these heterogeneous samples. However, the majority of current studies analyse ITC on the ideal premise that the samples in every modality are complete. This presumption, however, is not always valid in real-world situations. The missing data issue degenerates the image-text feature learning performance and will finally affect the generalization abilities in ITC tasks. Although a series of methods have been proposed to address this incomplete image text clustering issue (IITC), the following problems still exist: 1) most existing methods hardly consider the distinct gap between heterogeneous feature domains. 2) For missing data, the representations generated by existing methods are rarely guaranteed to suit clustering tasks. 3) Existing methods do not tap into the latent connections both inter and intra modalities. In this paper, we propose a Clustering-Induced Generative Incomplete Image-Text Clustering(CIGIT-C) network to address the challenges above. More specifically, we first use modality-specific encoders to map original features to more distinctive subspaces. The latent connections between intra and inter-modalities are thoroughly explored by using the adversarial generating network to produce one modality conditional on the other modality. Finally, we update the corresponding modalityspecific encoders using two KL divergence losses. Experiment results on public image-text datasets demonstrated that the suggested method outperforms and is more effective in the IITC job.