 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch: A Toolkit for Streamlining LLM Operations
Sep 05, 2024



Large language models (LLMs) represented by GPT family have achieved remarkable success. The characteristics of LLMs lie in their ability to accommodate a wide range of tasks through a generative approach. However, the flexibility of their output format poses challenges in controlling and harnessing the model's outputs, thereby constraining the application of LLMs in various domains. In this work, we present Sketch, an innovative toolkit designed to streamline LLM operations across diverse fields. Sketch comprises the following components: (1) a suite of task description schemas and prompt templates encompassing various NLP tasks; (2) a user-friendly, interactive process for building structured output LLM services tailored to various NLP tasks; (3) an open-source dataset for output format control, along with tools for dataset construction; and (4) an open-source model based on LLaMA3-8B-Instruct that adeptly comprehends and adheres to output formatting instructions. We anticipate this initiative to bring considerable convenience to LLM users, achieving the goal of ''plug-and-play'' for various applications. The components of Sketch will be progressively open-sourced at https://github.com/cofe-ai/Sketch.
Open-domain Implicit Format Control for Large Language Model Generation
Aug 08, 2024
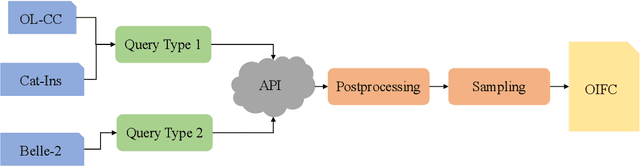
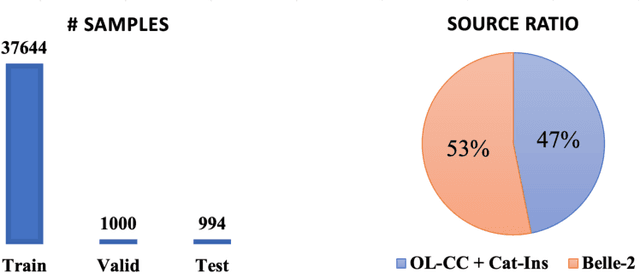

Controlling the format of outputs generated by large language models (LLMs) is a critical functionality in various applications. Current methods typically employ constrained decoding with rule-based automata or fine-tuning with manually crafted format instructions, both of which struggle with open-domain format requirements. To address this limitation, we introduce a novel framework for controlled generation in LLMs, leveraging user-provided, one-shot QA pairs. This study investigates LLMs' capabilities to follow open-domain, one-shot constraints and replicate the format of the example answers. We observe that this is a non-trivial problem for current LLMs. We also develop a dataset collection methodology for supervised fine-tuning that enhances the open-domain format control of LLMs without degrading output quality, as well as a benchmark on which we evaluate both the helpfulness and format correctness of LLM outputs. The resulting datasets, named OIFC-SFT, along with the related code, will be made publicly available at https://github.com/cofe-ai/OIFC.