 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable and Near-Optimal Conformance Checking Approach for Long Traces
Jun 08, 2024Long traces and large event logs that originate from sensors and prediction models are becoming more common in our data-rich world. In such circumstances, conformance checking, a key task in process mining, can become computationally infeasible due to the exponential complexity of finding an optimal alignment. This paper introduces a novel sliding window approach to address these scalability challenges while preserving the interpretability of alignment-based methods. By breaking down traces into manageable subtraces and iteratively aligning each with the process model, our method significantly reduces the search space. The approach uses global information that captures structural properties of the trace and the process model to make informed alignment decisions, discarding unpromising alignments even if they are optimal for a local subtrace. This improves the overall accuracy of the results. Experimental evaluations demonstrate that the proposed method consistently finds optimal alignments in most cases and highlight its scalability. This is further supported by a theoretical complexity analysis, which shows the reduced growth of the search space compared to other common conformance checking methods. This work provides a valuable contribution towards efficient conformance checking for large-scale process mining applications.
Data-driven project planning: An integrated network learning and constraint relaxation approach in favor of scheduling
Nov 20, 2023Our focus is on projects, i.e., business processes, which are emerging as the economic drivers of our times. Differently from day-to-day operational processes that do not require detailed planning, a project requires planning and resource-constrained scheduling for coordinating resources across sub- or related projects and organizations. A planner in charge of project planning has to select a set of activities to perform, determine their precedence constraints, and schedule them according to temporal project constraints. We suggest a data-driven project planning approach for classes of projects such as infrastructure building and information systems development projects. A project network is first learned from historical records. The discovered network relaxes temporal constraints embedded in individual projects, thus uncovering where planning and scheduling flexibility can be exploited for greater benefit. Then, the network, which contains multiple project plan variations, from which one has to be selected, is enriched by identifying decision rules and frequent paths. The planner can rely on the project network for: 1) decoding a project variation such that it forms a new project plan, and 2) applying resource-constrained project scheduling procedures to determine the project's schedule and resource allocation. Using two real-world project datasets, we show that the suggested approach may provide the planner with significant flexibility (up to a 26% reduction of the critical path of a real project) to adjust the project plan and schedule. We believe that the proposed approach can play an important part in supporting decision making towards automated data-driven project planning.
Adaptive Learning for the Resource-Constrained Classification Problem
Jul 19, 2022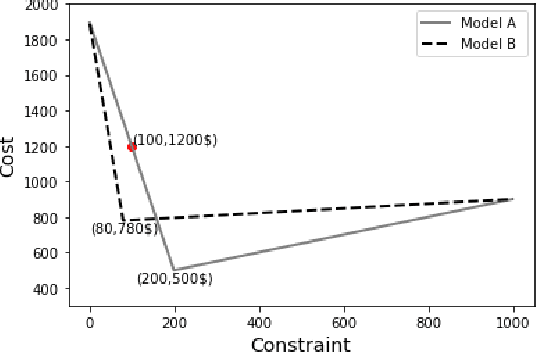
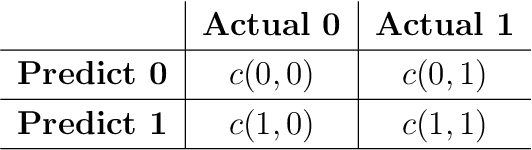
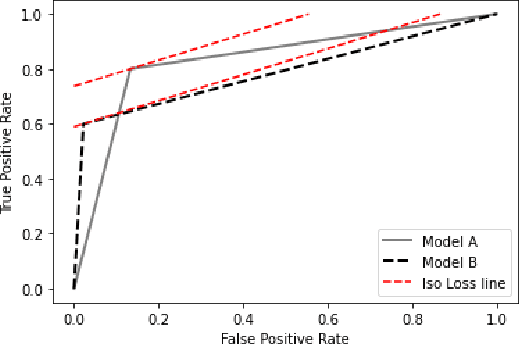

Resource-constrained classification tasks are common in real-world applications such as allocating tests for disease diagnosis, hiring decisions when filling a limited number of positions, and defect detection in manufacturing settings under a limited inspection budget. Typical classification algorithms treat the learning process and the resource constraints as two separate and sequential tasks. Here we design an adaptive learning approach that considers resource constraints and learning jointly by iteratively fine-tuning misclassification costs. Via a structured experimental study using a publicly available data set, we evaluate a decision tree classifier that utilizes the proposed approach. The adaptive learning approach performs significantly better than alternative approaches, especially for difficult classification problems in which the performance of common approaches may be unsatisfactory. We envision the adaptive learning approach as an important addition to the repertoire of techniques for handling resource-constrained classification problems.
Trace Recovery from Stochastically Known Logs
Jun 25, 2022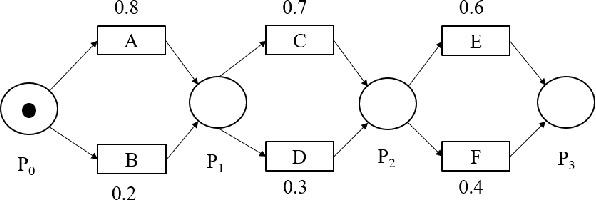

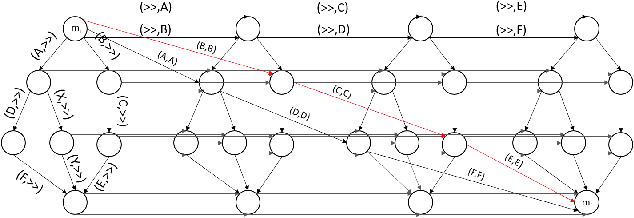
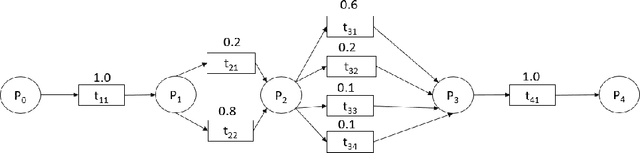
In this work we propose an algorithm for trace recovery from stochastically known logs, a setting that is becoming more common with the increasing number of sensors and predictive models that generate uncertain data. The suggested approach calculates the conformance between a process model and a stochastically known trace and recovers the best alignment within this stochastic trace as the true trace. The paper offers an analysis of the impact of various cost models on trace recovery accuracy and makes use of a product multi-graph to compare alternative trace recovery options. The average accuracy of our approach, evaluated using two publicly available datasets, is impressive, with an average recovery accuracy score of 90-97%, significantly improving a common heuristic that chooses the most likely value for each uncertain activity. We believe that the effectiveness of the proposed algorithm in recovering correct traces from stochastically known logs may be a powerful aid for developing credible decision-making tools in uncertain settings.
Conformance Checking Over Stochastically Known Logs
Mar 14, 2022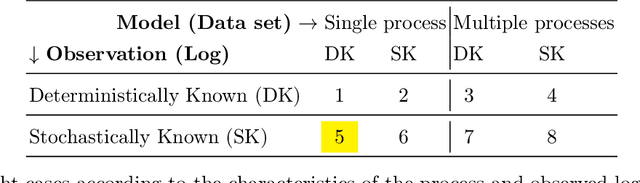

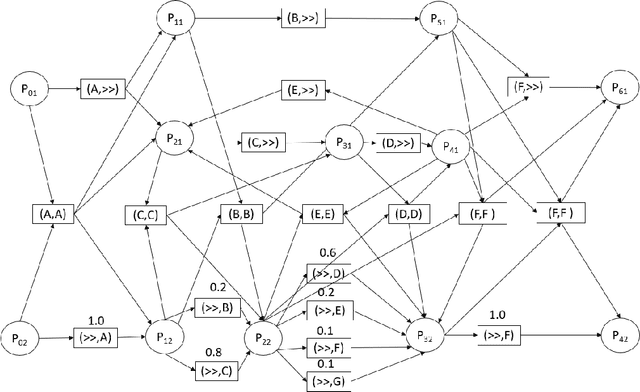
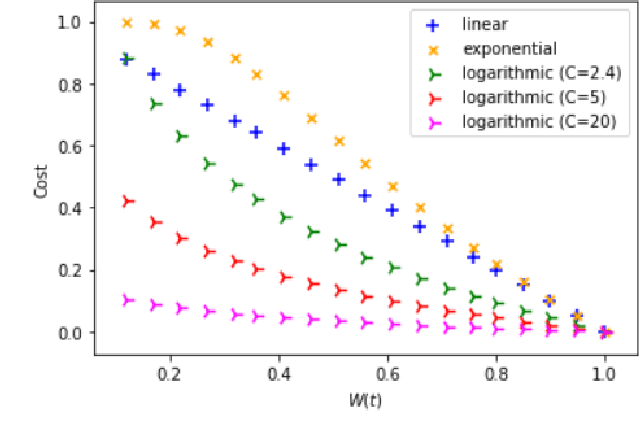
With the growing number of devices, sensors and digital systems, data logs may become uncertain due to, e.g., sensor reading inaccuracies or incorrect interpretation of readings by processing programs. At times, such uncertainties can be captured stochastically, especially when using probabilistic data classification models. In this work we focus on conformance checking, which compares a process model with an event log, when event logs are stochastically known. Building on existing alignment-based conformance checking fundamentals, we mathematically define a stochastic trace model, a stochastic synchronous product, and a cost function that reflects the uncertainty of events in a log. Then, we search for an optimal alignment over the reachability graph of the stochastic synchronous product for finding an optimal alignment between a model and a stochastic process observation. Via structured experiments with two well-known process mining benchmarks, we explore the behavior of the suggested stochastic conformance checking approach and compare it to a standard alignment-based approach as well as to an approach that creates a lower bound on performance. We envision the proposed stochastic conformance checking approach as a viable process mining component for future analysis of stochastic event logs.
Uncertain Process Data with Probabilistic Knowledge: Problem Characterization and Challenges
Jun 07, 2021

Motivated by the abundance of uncertain event data from multiple sources including physical devices and sensors, this paper presents the task of relating a stochastic process observation to a process model that can be rendered from a dataset. In contrast to previous research that suggested to transform a stochastically known event log into a less informative uncertain log with upper and lower bounds on activity frequencies, we consider the challenge of accommodating the probabilistic knowledge into conformance checking techniques. Based on a taxonomy that captures the spectrum of conformance checking cases under stochastic process observations, we present three types of challenging cases. The first includes conformance checking of a stochastically known log with respect to a given process model. The second case extends the first to classify a stochastically known log into one of several process models. The third case extends the two previous ones into settings in which process models are only stochastically known. The suggested problem captures the increasingly growing number of applications in which sensors provide probabilistic process information.