 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Complementary Separation Pruning Toward Lightweight CNNs
May 19, 2025In this paper, we present Automatic Complementary Separation Pruning (ACSP), a novel and fully automated pruning method for convolutional neural networks. ACSP integrates the strengths of both structured pruning and activation-based pruning, enabling the efficient removal of entire components such as neurons and channels while leveraging activations to identify and retain the most relevant components. Our approach is designed specifically for supervised learning tasks, where we construct a graph space that encodes the separation capabilities of each component with respect to all class pairs. By employing complementary selection principles and utilizing a clustering algorithm, ACSP ensures that the selected components maintain diverse and complementary separation capabilities, reducing redundancy and maintaining high network performance. The method automatically determines the optimal subset of components in each layer, utilizing a knee-finding algorithm to select the minimal subset that preserves performance without requiring user-defined pruning volumes. Extensive experiments on multiple architectures, including VGG-16, ResNet-50, and MobileNet-V2, across datasets like CIFAR-10, CIFAR-100, and ImageNet-1K, demonstrate that ACSP achieves competitive accuracy compared to other methods while significantly reducing computational costs. This fully automated approach not only enhances scalability but also makes ACSP especially practical for real-world deployment by eliminating the need for manually defining the pruning volume.
Graph-Based Automatic Feature Selection for Multi-Class Classification via Mean Simplified Silhouette
Sep 05, 2023
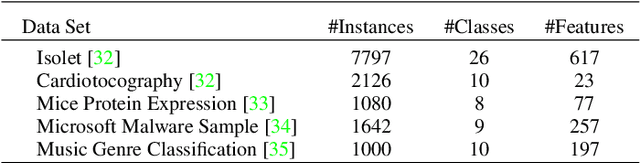
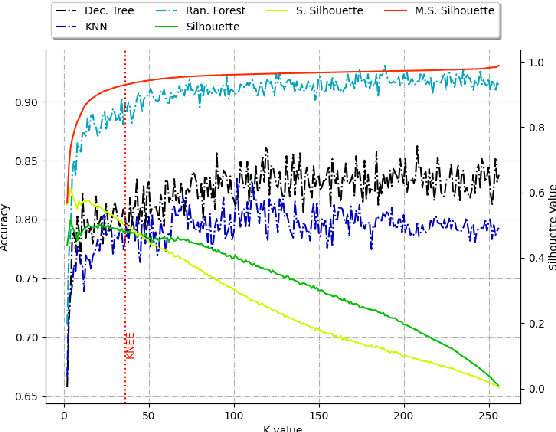
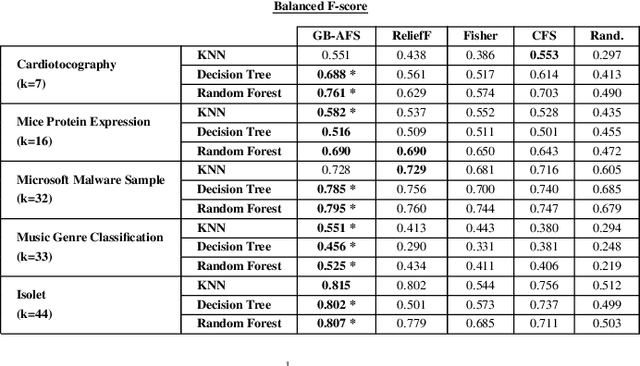
This paper introduces a novel graph-based filter method for automatic feature selection (abbreviated as GB-AFS) for multi-class classification tasks. The method determines the minimum combination of features required to sustain prediction performance while maintaining complementary discriminating abilities between different classes. It does not require any user-defined parameters such as the number of features to select. The methodology employs the Jeffries-Matusita (JM) distance in conjunction with t-distributed Stochastic Neighbor Embedding (t-SNE) to generate a low-dimensional space reflecting how effectively each feature can differentiate between each pair of classes. The minimum number of features is selected using our newly developed Mean Simplified Silhouette (abbreviated as MSS) index, designed to evaluate the clustering results for the feature selection task. Experimental results on public data sets demonstrate the superior performance of the proposed GB-AFS over other filter-based techniques and automatic feature selection approaches. Moreover, the proposed algorithm maintained the accuracy achieved when utilizing all features, while using only $7\%$ to $30\%$ of the features. Consequently, this resulted in a reduction of the time needed for classifications, from $15\%$ to $70\%$.
Graph-based Extreme Feature Selection for Multi-class Classification Tasks
Mar 03, 2023


When processing high-dimensional datasets, a common pre-processing step is feature selection. Filter-based feature selection algorithms are not tailored to a specific classification method, but rather rank the relevance of each feature with respect to the target and the task. This work focuses on a graph-based, filter feature selection method that is suited for multi-class classifications tasks. We aim to drastically reduce the number of selected features, in order to create a sketch of the original data that codes valuable information for the classification task. The proposed graph-based algorithm is constructed by combing the Jeffries-Matusita distance with a non-linear dimension reduction method, diffusion maps. Feature elimination is performed based on the distribution of the features in the low-dimensional space. Then, a very small number of feature that have complementary separation strengths, are selected. Moreover, the low-dimensional embedding allows to visualize the feature space. Experimental results are provided for public datasets and compared with known filter-based feature selection techniques.
Adaptive Learning for the Resource-Constrained Classification Problem
Jul 19, 2022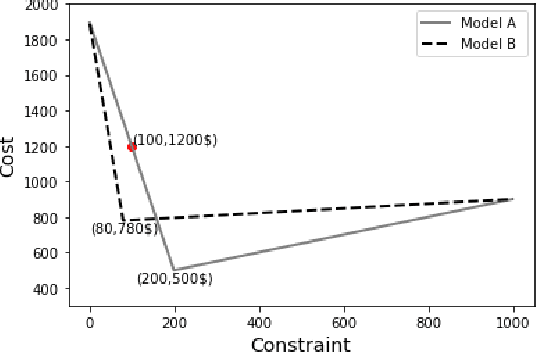
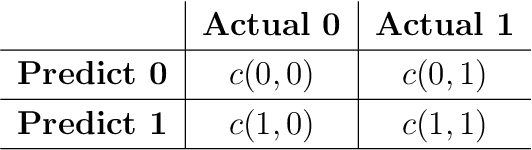

Resource-constrained classification tasks are common in real-world applications such as allocating tests for disease diagnosis, hiring decisions when filling a limited number of positions, and defect detection in manufacturing settings under a limited inspection budget. Typical classification algorithms treat the learning process and the resource constraints as two separate and sequential tasks. Here we design an adaptive learning approach that considers resource constraints and learning jointly by iteratively fine-tuning misclassification costs. Via a structured experimental study using a publicly available data set, we evaluate a decision tree classifier that utilizes the proposed approach. The adaptive learning approach performs significantly better than alternative approaches, especially for difficult classification problems in which the performance of common approaches may be unsatisfactory. We envision the adaptive learning approach as an important addition to the repertoire of techniques for handling resource-constrained classification problems.
Adaptive Cost-Sensitive Learning in Neural Networks for Misclassification Cost Problems
Nov 14, 2021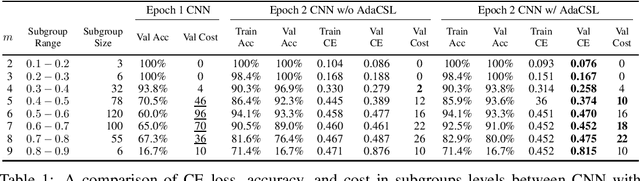

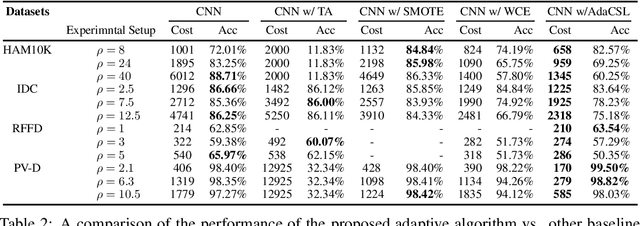
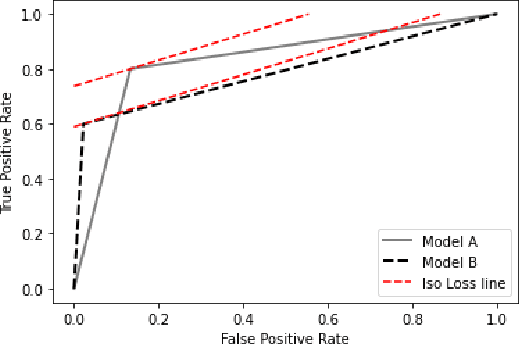
We design a new adaptive learning algorithm for misclassification cost problems that attempt to reduce the cost of misclassified instances derived from the consequences of various errors. Our algorithm (adaptive cost sensitive learning - AdaCSL) adaptively adjusts the loss function such that the classifier bridges the difference between the class distributions between subgroups of samples in the training and test data sets with similar predicted probabilities (i.e., local training-test class distribution mismatch). We provide some theoretical performance guarantees on the proposed algorithm and present empirical evidence that a deep neural network used with the proposed AdaCSL algorithm yields better cost results on several binary classification data sets that have class-imbalanced and class-balanced distributions compared to other alternative approaches.