 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Learning for the Resource-Constrained Classification Problem
Jul 19, 2022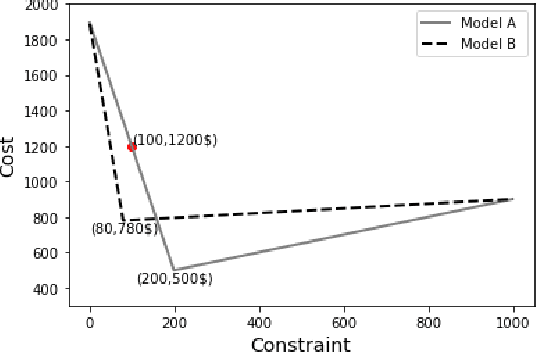
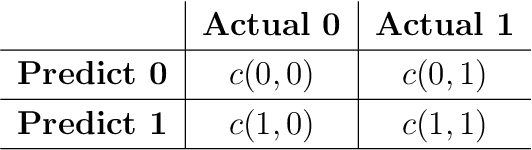
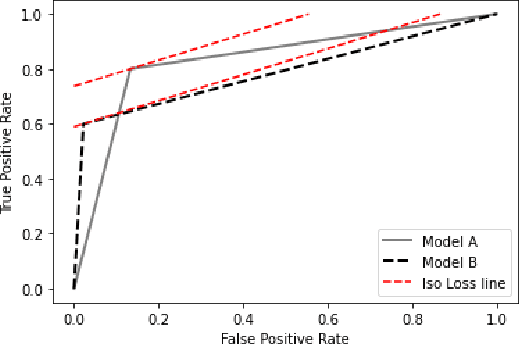

Resource-constrained classification tasks are common in real-world applications such as allocating tests for disease diagnosis, hiring decisions when filling a limited number of positions, and defect detection in manufacturing settings under a limited inspection budget. Typical classification algorithms treat the learning process and the resource constraints as two separate and sequential tasks. Here we design an adaptive learning approach that considers resource constraints and learning jointly by iteratively fine-tuning misclassification costs. Via a structured experimental study using a publicly available data set, we evaluate a decision tree classifier that utilizes the proposed approach. The adaptive learning approach performs significantly better than alternative approaches, especially for difficult classification problems in which the performance of common approaches may be unsatisfactory. We envision the adaptive learning approach as an important addition to the repertoire of techniques for handling resource-constrained classification problems.
JULIA: Joint Multi-linear and Nonlinear Identification for Tensor Completion
Jan 31, 2022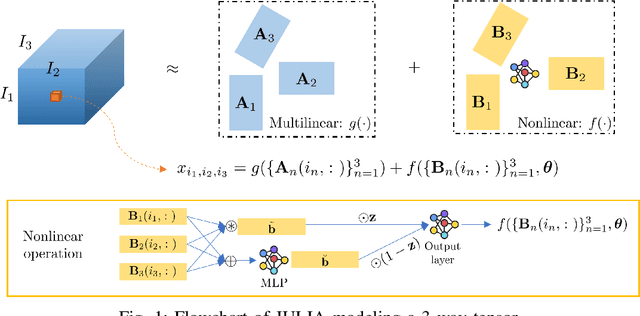
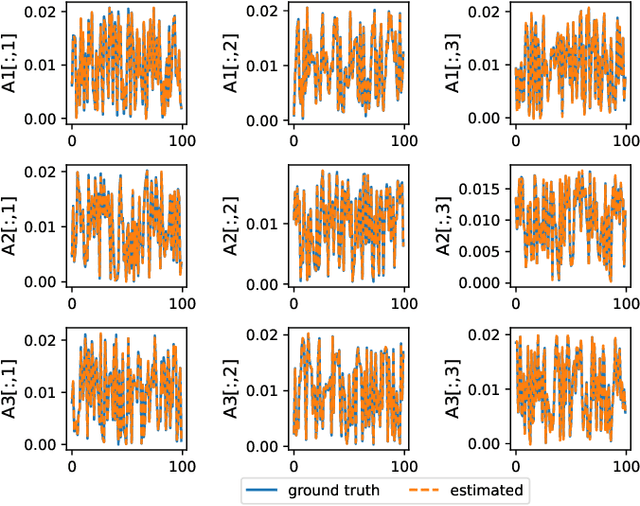
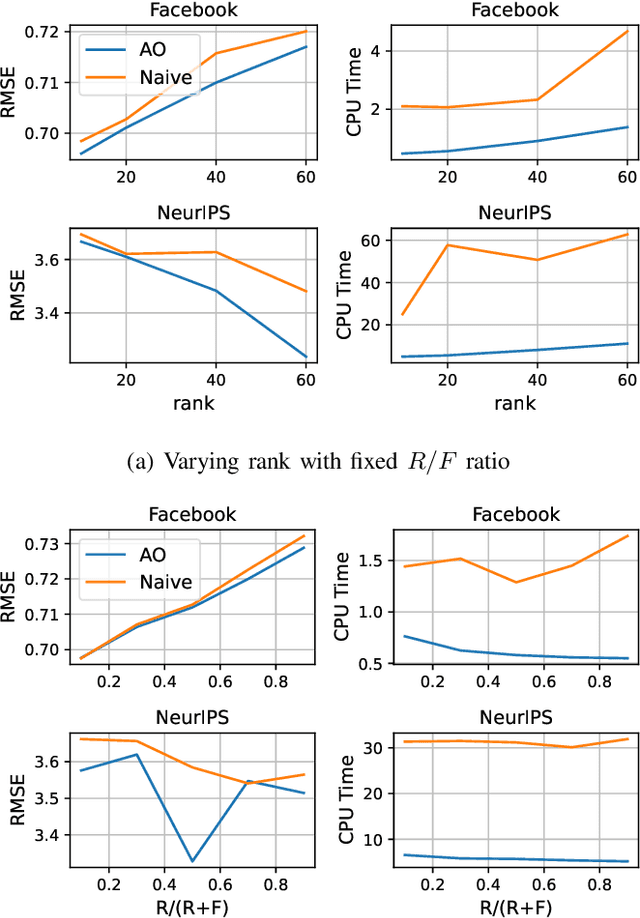
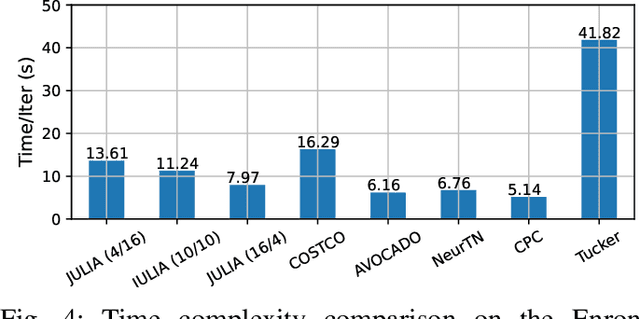
Tensor completion aims at imputing missing entries from a partially observed tensor. Existing tensor completion methods often assume either multi-linear or nonlinear relationships between latent components. However, real-world tensors have much more complex patterns where both multi-linear and nonlinear relationships may coexist. In such cases, the existing methods are insufficient to describe the data structure. This paper proposes a Joint mUlti-linear and nonLinear IdentificAtion (JULIA) framework for large-scale tensor completion. JULIA unifies the multi-linear and nonlinear tensor completion models with several advantages over the existing methods: 1) Flexible model selection, i.e., it fits a tensor by assigning its values as a combination of multi-linear and nonlinear components; 2) Compatible with existing nonlinear tensor completion methods; 3) Efficient training based on a well-designed alternating optimization approach. Experiments on six real large-scale tensors demonstrate that JULIA outperforms many existing tensor completion algorithms. Furthermore, JULIA can improve the performance of a class of nonlinear tensor completion methods. The results show that in some large-scale tensor completion scenarios, baseline methods with JULIA are able to obtain up to 55% lower root mean-squared-error and save 67% computational complexity.
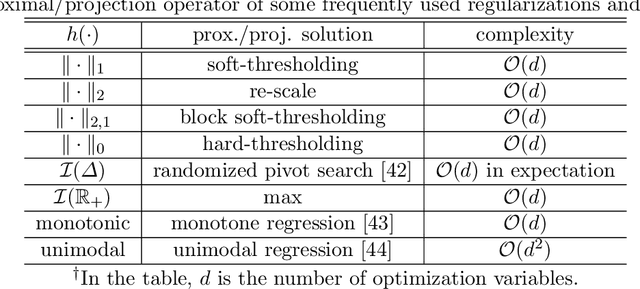
Nonconvex Optimization Tools for Large-Scale Matrix and Tensor Decomposition with Structured Factors
Jun 15, 2020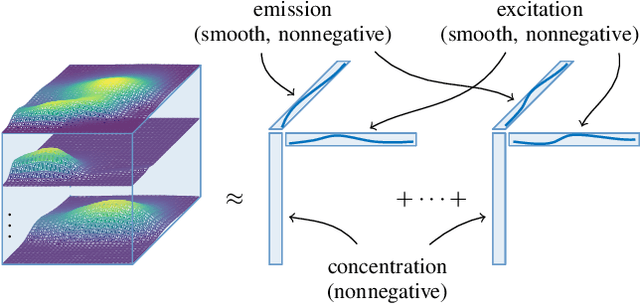
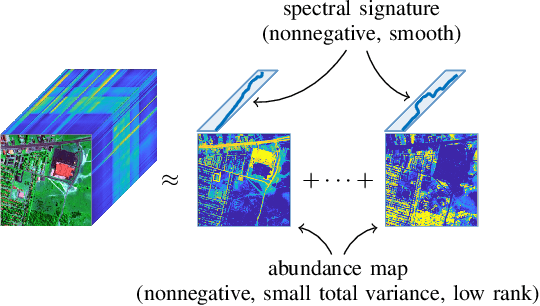
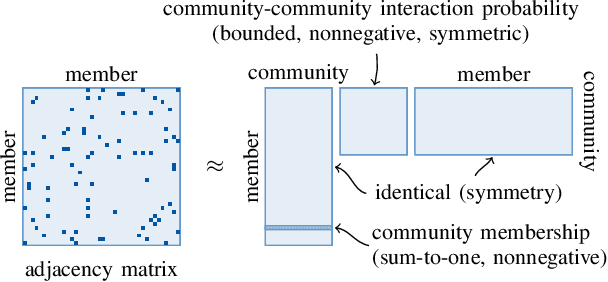
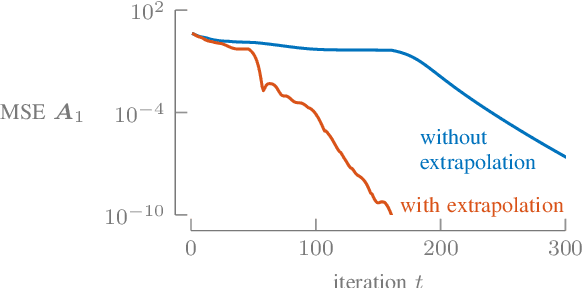
The proposed article aims at offering a comprehensive tutorial for the computational aspects of structured matrix and tensor factorization. Unlike existing tutorials that mainly focus on {\it algorithmic procedures} for a small set of problems, e.g., nonnegativity or sparsity-constrained factorization, we take a {\it top-down} approach: we start with general optimization theory (e.g., inexact and accelerated block coordinate descent, stochastic optimization, and Gauss-Newton methods) that covers a wide range of factorization problems with diverse constraints and regularization terms of engineering interest. Then, we go `under the hood' to showcase specific algorithm design under these introduced principles. We pay a particular attention to recent algorithmic developments in structured tensor and matrix factorization (e.g., random sketching and adaptive step size based stochastic optimization and structure-exploiting second-order algorithms), which are the state of the art---yet much less touched upon in the literature compared to {\it block coordinate descent} (BCD)-based methods. We expect that the article to have an educational values in the field of structured factorization and hope to stimulate more research in this important and exciting direction.
Crowdsourcing via Pairwise Co-occurrences: Identifiability and Algorithms
Sep 26, 2019
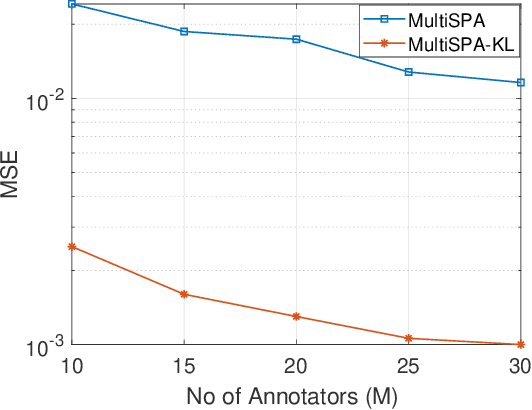
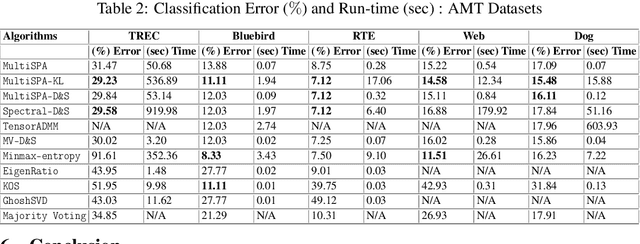
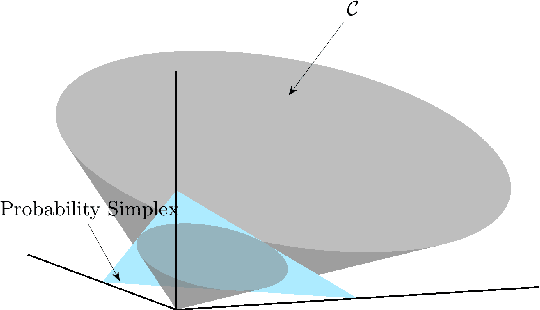
The data deluge comes with high demands for data labeling. Crowdsourcing (or, more generally, ensemble learning) techniques aim to produce accurate labels via integrating noisy, non-expert labeling from annotators. The classic Dawid-Skene estimator and its accompanying expectation maximization (EM) algorithm have been widely used, but the theoretical properties are not fully understood. Tensor methods were proposed to guarantee identification of the Dawid-Skene model, but the sample complexity is a hurdle for applying such approaches---since the tensor methods hinge on the availability of third-order statistics that are hard to reliably estimate given limited data. In this paper, we propose a framework using pairwise co-occurrences of the annotator responses, which naturally admits lower sample complexity. We show that the approach can identify the Dawid-Skene model under realistic conditions. We propose an algebraic algorithm reminiscent of convex geometry-based structured matrix factorization to solve the model identification problem efficiently, and an identifiability-enhanced algorithm for handling more challenging and critical scenarios. Experiments show that the proposed algorithms outperform the state-of-art algorithms under a variety of scenarios.
SNAP: Finding Approximate Second-Order Stationary Solutions Efficiently for Non-convex Linearly Constrained Problems
Jul 09, 2019
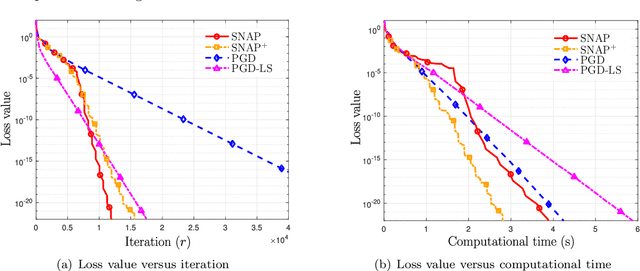
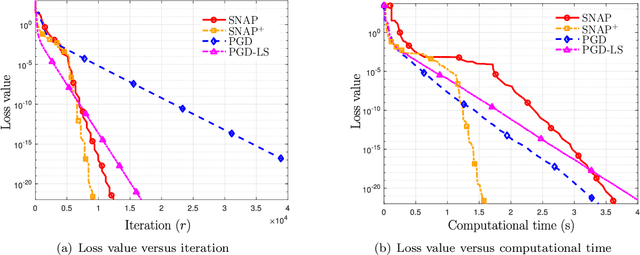
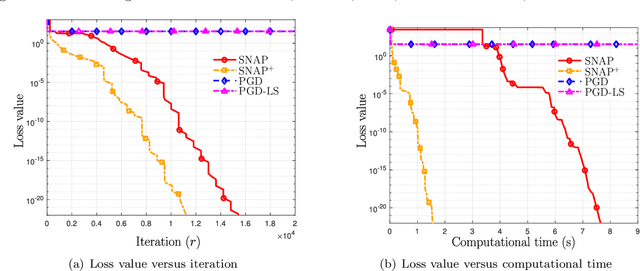
This paper proposes low-complexity algorithms for finding approximate second-order stationary points (SOSPs) of problems with smooth non-convex objective and linear constraints. While finding (approximate) SOSPs is computationally intractable, we first show that generic instances of the problem can be solved efficiently. More specifically, for a generic problem instance, certain strict complementarity (SC) condition holds for all Karush-Kuhn-Tucker (KKT) solutions (with probability one). The SC condition is then used to establish an equivalence relationship between two different notions of SOSPs, one of which is computationally easy to verify. Based on this particular notion of SOSP, we design an algorithm named the Successive Negative-curvature grAdient Projection (SNAP), which successively performs either conventional gradient projection or some negative curvature based projection steps to find SOSPs. SNAP and its first-order extension SNAP$^+$, require $\mathcal{O}(1/\epsilon^{2.5})$ iterations to compute an $(\epsilon, \sqrt{\epsilon})$-SOSP, and their per-iteration computational complexities are polynomial in the number of constraints and problem dimension. To our knowledge, this is the first time that first-order algorithms with polynomial per-iteration complexity and global sublinear rate have been designed to find SOSPs of the important class of non-convex problems with linear constraints.
Block-Randomized Stochastic Proximal Gradient for Low-Rank Tensor Factorization
Jan 16, 2019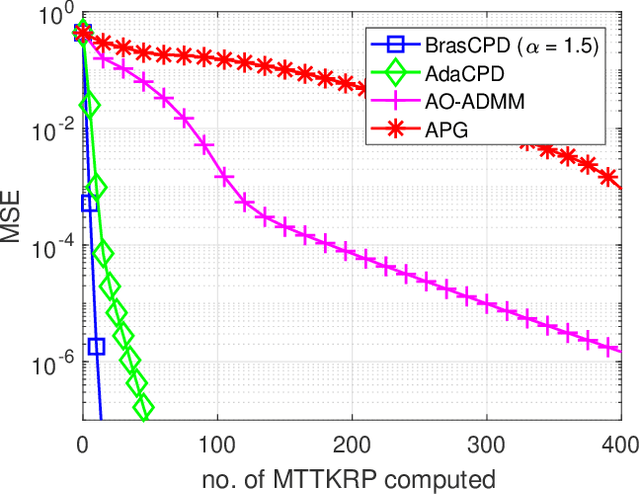
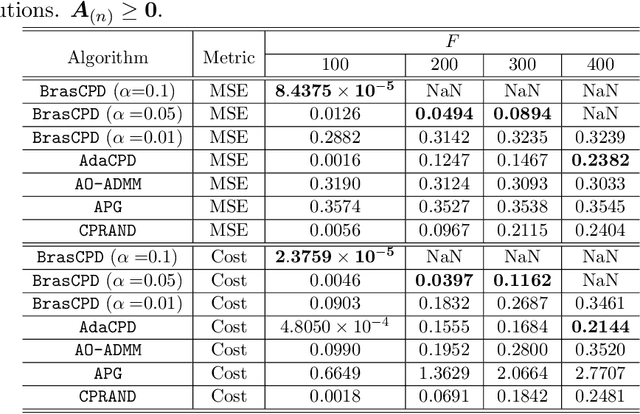
This work considers the problem of computing the \textit{canonical polyadic decomposition} (CPD) of large tensors. Prior works mostly leverage data sparsity to handle this problem, which are not suitable for handling dense tensors that often arise in applications such as medical imaging, computer vision, and remote sensing. Stochastic optimization is known for its low memory cost and per-iteration complexity when handling dense data. However, existing stochastic CPD algorithms are hard to incorporate a variety of constraints and regularizations that are of interest in signal and data analytics. Convergence properties of many such algorithms are also unclear. In this work, we propose a stochastic optimization framework for large-scale CPD with constraints/regularizations. The framework works under a doubly randomized fashion, and can be regarded as a judicious combination of \textit{randomized block coordinate descent} (BCD) and \textit{stochastic proximal gradient} (SPG). The algorithm enjoys lightweight updates and small memory footprint, and thus scales well. In addition, this framework entails considerable flexibility---many frequently used regularizers and constraints can be readily handled under the proposed scheme. The approach is also supported by convergence analysis. Numerical results on large-scale dense tensors are employed to showcase the effectiveness of the proposed approach.
Learning Nonlinear Mixtures: Identifiability and Algorithm
Jan 06, 2019
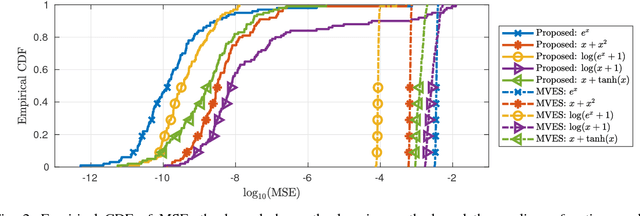

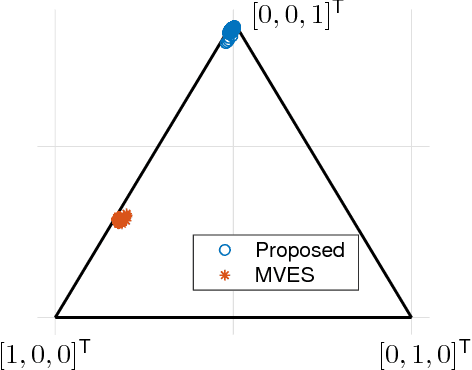
Linear mixture models have proven very useful in a plethora of applications, e.g., topic modeling, clustering, and source separation. As a critical aspect of the linear mixture models, identifiability of the model parameters is well-studied, under frameworks such as independent component analysis and constrained matrix factorization. Nevertheless, when the linear mixtures are distorted by an unknown nonlinear functions -- which is well-motivated and more realistic in many cases -- the identifiability issues are much less studied. This work proposes an identification criterion for a nonlinear mixture model that is well grounded in many real-world applications, and offers identifiability guarantees. A practical implementation based on a judiciously designed neural network is proposed to realize the criterion, and an effective learning algorithm is proposed. Numerical results on synthetic and real-data corroborate effectiveness of the proposed method.
Nonnegative Matrix Factorization for Signal and Data Analytics: Identifiability, Algorithms, and Applications
Oct 18, 2018

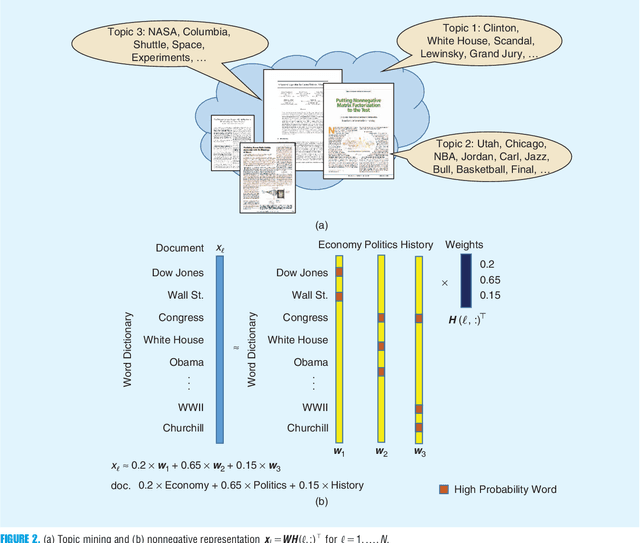

Nonnegative matrix factorization (NMF) has become a workhorse for signal and data analytics, triggered by its model parsimony and interpretability. Perhaps a bit surprisingly, the understanding to its model identifiability---the major reason behind the interpretability in many applications such as topic mining and hyperspectral imaging---had been rather limited until recent years. Beginning from the 2010s, the identifiability research of NMF has progressed considerably: Many interesting and important results have been discovered by the signal processing (SP) and machine learning (ML) communities. NMF identifiability has a great impact on many aspects in practice, such as ill-posed formulation avoidance and performance-guaranteed algorithm design. On the other hand, there is no tutorial paper that introduces NMF from an identifiability viewpoint. In this paper, we aim at filling this gap by offering a comprehensive and deep tutorial on model identifiability of NMF as well as the connections to algorithms and applications. This tutorial will help researchers and graduate students grasp the essence and insights of NMF, thereby avoiding typical `pitfalls' that are often times due to unidentifiable NMF formulations. This paper will also help practitioners pick/design suitable factorization tools for their own problems.
Learning Hidden Markov Models from Pairwise Co-occurrences with Application to Topic Modeling
Jun 18, 2018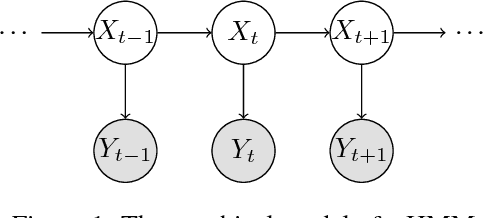

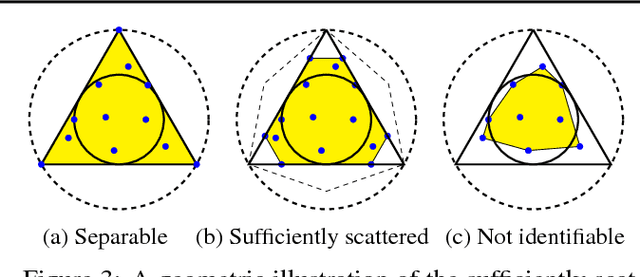
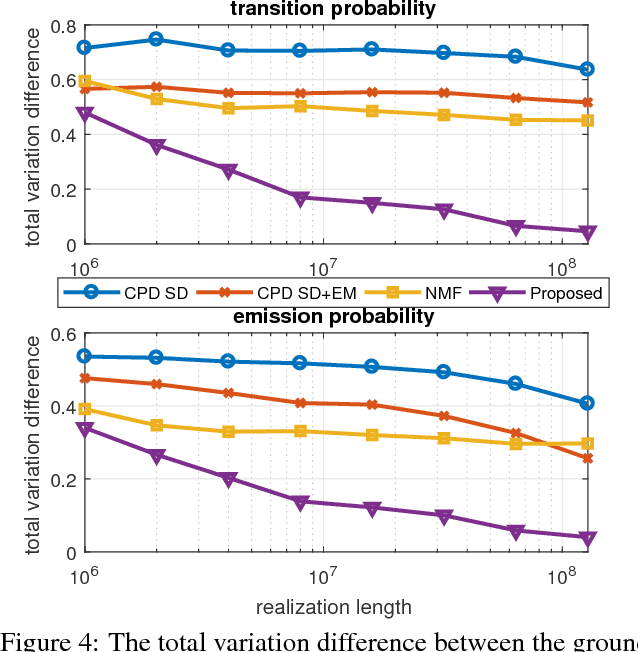
We present a new algorithm for identifying the transition and emission probabilities of a hidden Markov model (HMM) from the emitted data. Expectation-maximization becomes computationally prohibitive for long observation records, which are often required for identification. The new algorithm is particularly suitable for cases where the available sample size is large enough to accurately estimate second-order output probabilities, but not higher-order ones. We show that if one is only able to obtain a reliable estimate of the pairwise co-occurrence probabilities of the emissions, it is still possible to uniquely identify the HMM if the emission probability is \emph{sufficiently scattered}. We apply our method to hidden topic Markov modeling, and demonstrate that we can learn topics with higher quality if documents are modeled as observations of HMMs sharing the same emission (topic) probability, compared to the simple but widely used bag-of-words model.
Kullback-Leibler Principal Component for Tensors is not NP-hard
Nov 21, 2017
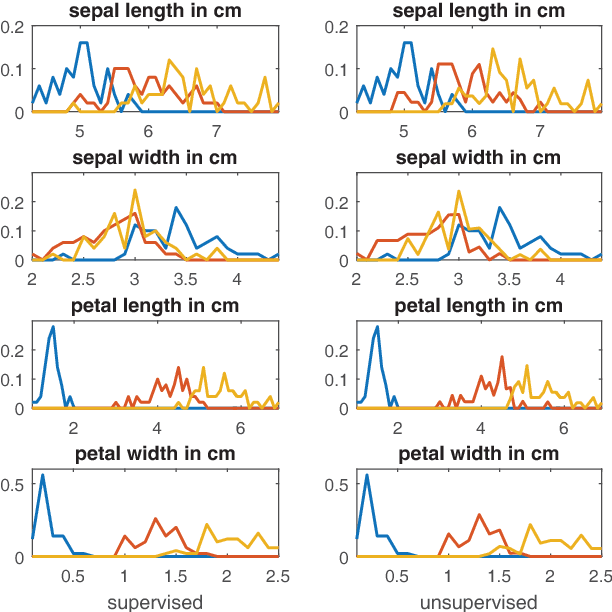
We study the problem of nonnegative rank-one approximation of a nonnegative tensor, and show that the globally optimal solution that minimizes the generalized Kullback-Leibler divergence can be efficiently obtained, i.e., it is not NP-hard. This result works for arbitrary nonnegative tensors with an arbitrary number of modes (including two, i.e., matrices). We derive a closed-form expression for the KL principal component, which is easy to compute and has an intuitive probabilistic interpretation. For generalized KL approximation with higher ranks, the problem is for the first time shown to be equivalent to multinomial latent variable modeling, and an iterative algorithm is derived that resembles the expectation-maximization algorithm. On the Iris dataset, we showcase how the derived results help us learn the model in an \emph{unsupervised} manner, and obtain strikingly close performance to that from supervised methods.