 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKullback-Leibler Principal Component for Tensors is not NP-hard
Paper and Code
Nov 21, 2017
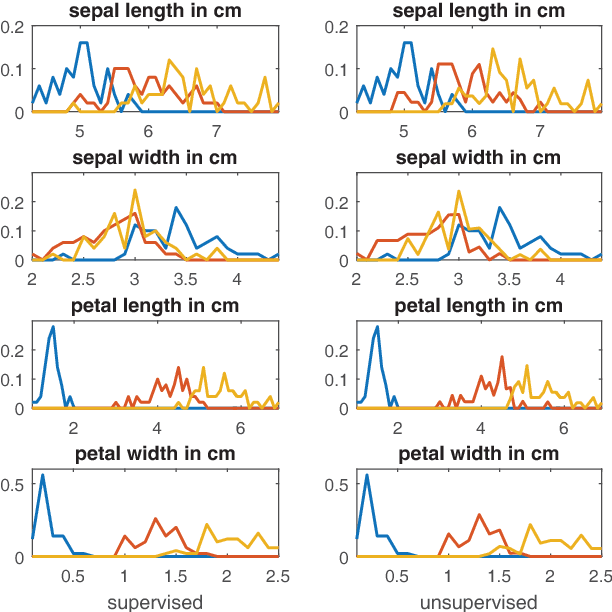
We study the problem of nonnegative rank-one approximation of a nonnegative tensor, and show that the globally optimal solution that minimizes the generalized Kullback-Leibler divergence can be efficiently obtained, i.e., it is not NP-hard. This result works for arbitrary nonnegative tensors with an arbitrary number of modes (including two, i.e., matrices). We derive a closed-form expression for the KL principal component, which is easy to compute and has an intuitive probabilistic interpretation. For generalized KL approximation with higher ranks, the problem is for the first time shown to be equivalent to multinomial latent variable modeling, and an iterative algorithm is derived that resembles the expectation-maximization algorithm. On the Iris dataset, we showcase how the derived results help us learn the model in an \emph{unsupervised} manner, and obtain strikingly close performance to that from supervised methods.