 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow well can large language models explain business processes?
Jan 23, 2024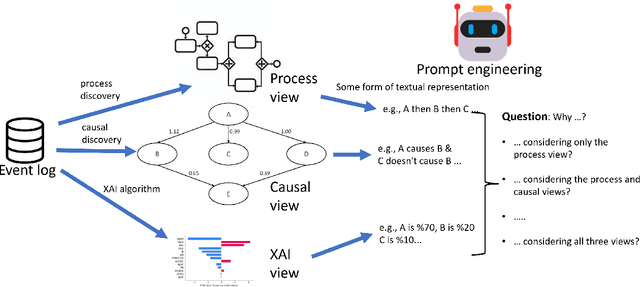
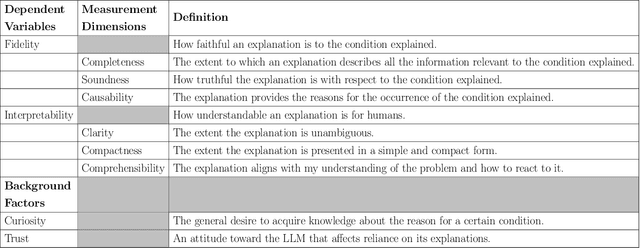
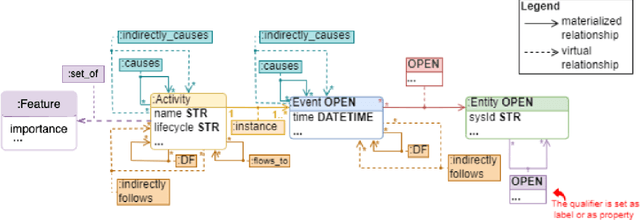
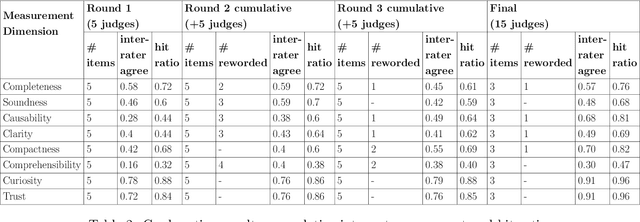
Large Language Models (LLMs) are likely to play a prominent role in future AI-augmented business process management systems (ABPMSs) catering functionalities across all system lifecycle stages. One such system's functionality is Situation-Aware eXplainability (SAX), which relates to generating causally sound and yet human-interpretable explanations that take into account the process context in which the explained condition occurred. In this paper, we present the SAX4BPM framework developed to generate SAX explanations. The SAX4BPM suite consists of a set of services and a central knowledge repository. The functionality of these services is to elicit the various knowledge ingredients that underlie SAX explanations. A key innovative component among these ingredients is the causal process execution view. In this work, we integrate the framework with an LLM to leverage its power to synthesize the various input ingredients for the sake of improved SAX explanations. Since the use of LLMs for SAX is also accompanied by a certain degree of doubt related to its capacity to adequately fulfill SAX along with its tendency for hallucination and lack of inherent capacity to reason, we pursued a methodological evaluation of the quality of the generated explanations. To this aim, we developed a designated scale and conducted a rigorous user study. Our findings show that the input presented to the LLMs aided with the guard-railing of its performance, yielding SAX explanations having better-perceived fidelity. This improvement is moderated by the perception of trust and curiosity. More so, this improvement comes at the cost of the perceived interpretability of the explanation.
Chit-Chat or Deep Talk: Prompt Engineering for Process Mining
Jul 19, 2023


This research investigates the application of Large Language Models (LLMs) to augment conversational agents in process mining, aiming to tackle its inherent complexity and diverse skill requirements. While LLM advancements present novel opportunities for conversational process mining, generating efficient outputs is still a hurdle. We propose an innovative approach that amend many issues in existing solutions, informed by prior research on Natural Language Processing (NLP) for conversational agents. Leveraging LLMs, our framework improves both accessibility and agent performance, as demonstrated by experiments on public question and data sets. Our research sets the stage for future explorations into LLMs' role in process mining and concludes with propositions for enhancing LLM memory, implementing real-time user testing, and examining diverse data sets.
Augmented Business Process Management Systems: A Research Manifesto
Feb 03, 2022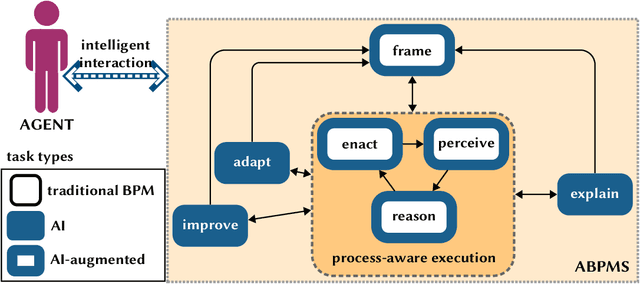
Augmented Business Process Management Systems (ABPMSs) are an emerging class of process-aware information systems that draws upon trustworthy AI technology. An ABPMS enhances the execution of business processes with the aim of making these processes more adaptable, proactive, explainable, and context-sensitive. This manifesto presents a vision for ABPMSs and discusses research challenges that need to be surmounted to realize this vision. To this end, we define the concept of ABPMS, we outline the lifecycle of processes within an ABPMS, we discuss core characteristics of an ABPMS, and we derive a set of challenges to realize systems with these characteristics.
Process Discovery Using Graph Neural Networks
Sep 13, 2021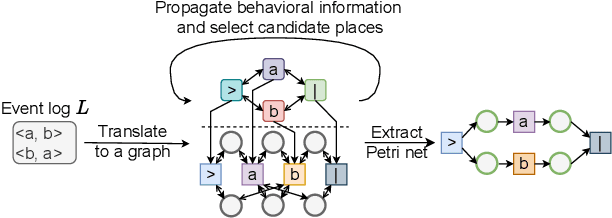
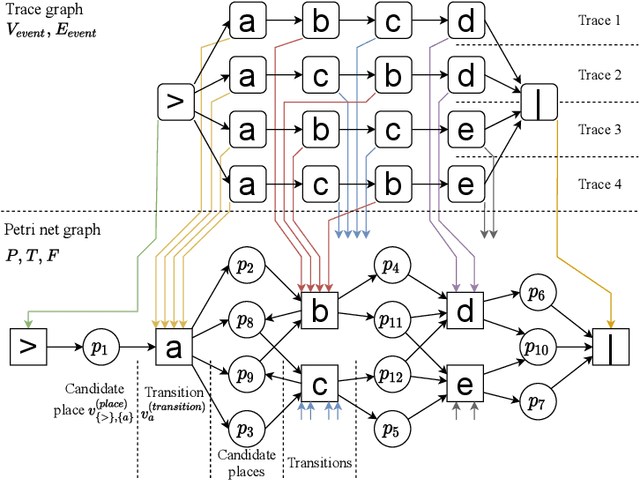
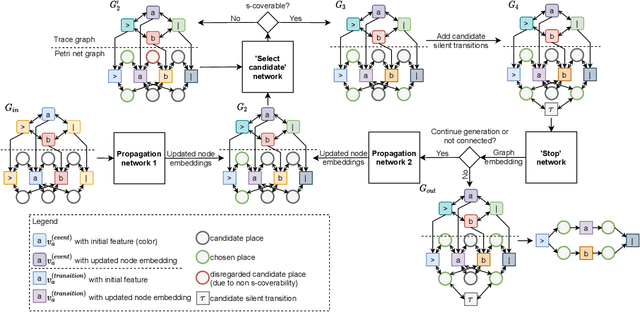
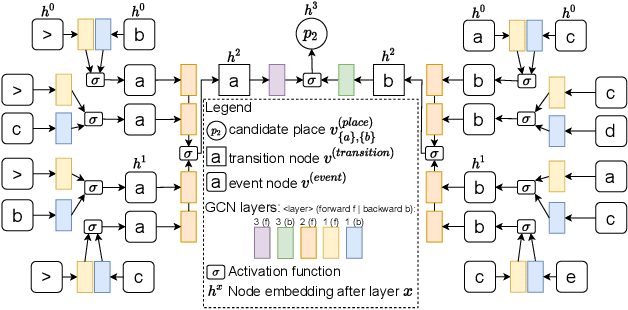
Automatically discovering a process model from an event log is the prime problem in process mining. This task is so far approached as an unsupervised learning problem through graph synthesis algorithms. Algorithmic design decisions and heuristics allow for efficiently finding models in a reduced search space. However, design decisions and heuristics are derived from assumptions about how a given behavioral description - an event log - translates into a process model and were not learned from actual models which introduce biases in the solutions. In this paper, we explore the problem of supervised learning of a process discovery technique D. We introduce a technique for training an ML-based model D using graph convolutional neural networks; D translates a given input event log into a sound Petri net. We show that training D on synthetically generated pairs of input logs and output models allows D to translate previously unseen synthetic and several real-life event logs into sound, arbitrarily structured models of comparable accuracy and simplicity as existing state of the art techniques for discovering imperative process models. We analyze the limitations of the proposed technique and outline alleys for future work.
Inferring Unobserved Events in Systems With Shared Resources and Queues
Feb 27, 2021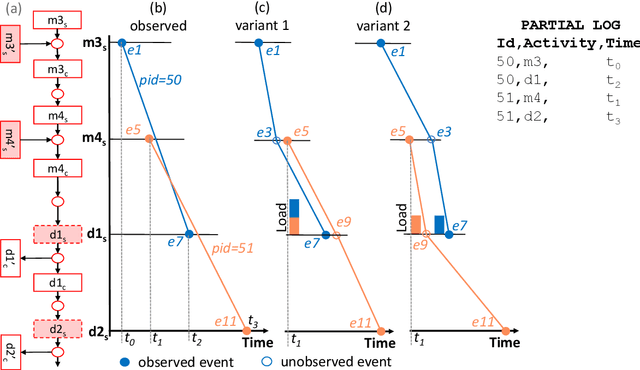
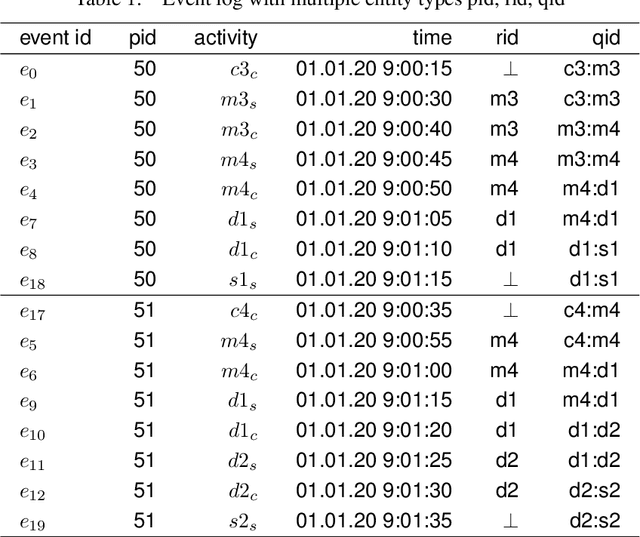
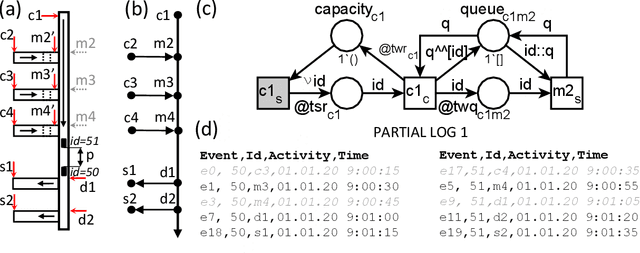
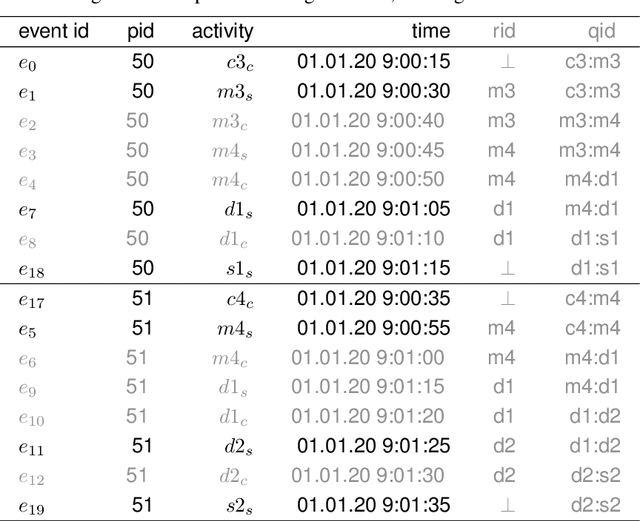
To identify the causes of performance problems or to predict process behavior, it is essential to have correct and complete event data. This is particularly important for distributed systems with shared resources, e.g., one case can block another case competing for the same machine, leading to inter-case dependencies in performance. However, due to a variety of reasons, real-life systems often record only a subset of all events taking place. For example, to reduce costs, the number of sensors is minimized or parts of the system are not connected. To understand and analyze the behavior of processes with shared resources, we aim to reconstruct bounds for timestamps of events that must have happened but were not recorded. We present a novel approach that decomposes system runs into entity traces of cases and resources that may need to synchronize in the presence of many-to-many relationships. Such relationships occur, for example, in warehouses where packages for N incoming orders are not handled in a single delivery but in M different deliveries. We use linear programming over entity traces to derive the timestamps of unobserved events in an efficient manner. This helps to complete the event logs and facilitates analysis. We focus on material handling systems like baggage handling systems in airports to illustrate our approach. However, the approach can be applied to other settings where recording is incomplete. The ideas have been implemented in ProM and were evaluated using both synthetic and real-life event logs.
The Imprecisions of Precision Measures in Process Mining
May 16, 2017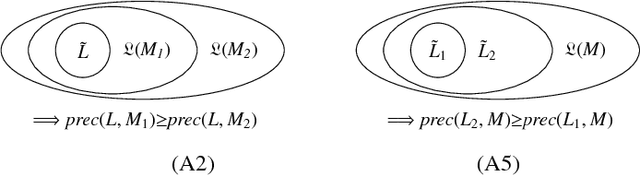

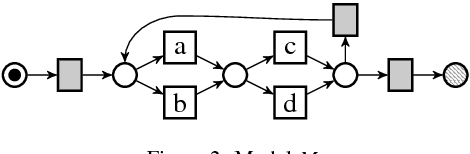
In process mining, precision measures are used to quantify how much a process model overapproximates the behavior seen in an event log. Although several measures have been proposed throughout the years, no research has been done to validate whether these measures achieve the intended aim of quantifying over-approximation in a consistent way for all models and logs. This paper fills this gap by postulating a number of axioms for quantifying precision consistently for any log and any model. Further, we show through counter-examples that none of the existing measures consistently quantifies precision.