 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Guided Attention for Video Action Anticipation
Mar 02, 2026Anticipating future actions in videos is challenging, as the observed frames provide only evidence of past activities, requiring the inference of latent intentions to predict upcoming actions. Existing transformer-based approaches, which rely on dot-product attention over pixel representations, often lack the high-level semantics necessary to model video sequences for effective action anticipation. As a result, these methods tend to overfit to explicit visual cues present in the past frames, limiting their ability to capture underlying intentions and degrading generalization to unseen samples. To address this, we propose Action-Guided Attention (AGA), an attention mechanism that explicitly leverages predicted action sequences as queries and keys to guide sequence modeling. Our approach fosters the attention module to emphasize relevant moments from the past based on the upcoming activity and combine this information with the current frame embedding via a dedicated gating function. The design of AGA enables post-training analysis of the knowledge discovered from the training set. Experiments on the widely adopted EPIC-Kitchens-100 benchmark demonstrate that AGA generalizes well from validation to unseen test sets. Post-training analysis can further examine the action dependencies captured by the model and the counterfactual evidence it has internalized, offering transparent and interpretable insights into its anticipative predictions.
Complete Approximations of Incomplete Queries
Jul 30, 2024This paper studies the completeness of conjunctive queries over a partially complete database and the approximation of incomplete queries. Given a query and a set of completeness rules (a special kind of tuple generating dependencies) that specify which parts of the database are complete, we investigate whether the query can be fully answered, as if all data were available. If not, we explore reformulating the query into either Maximal Complete Specializations (MCSs) or the (unique up to equivalence) Minimal Complete Generalization (MCG) that can be fully answered, that is, the best complete approximations of the query from below or above in the sense of query containment. We show that the MSG can be characterized as the least fixed-point of a monotonic operator in a preorder. Then, we show that an MCS can be computed by recursive backward application of completeness rules. We study the complexity of both problems and discuss implementation techniques that rely on an ASP and Prolog engines, respectively.
On Expansion and Contraction of DL-Lite Knowledge Bases
Jan 25, 2020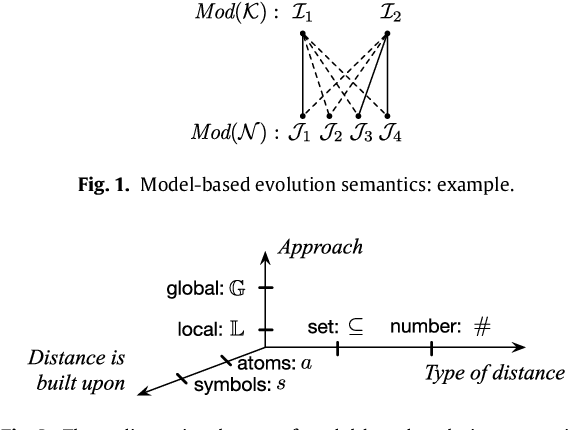
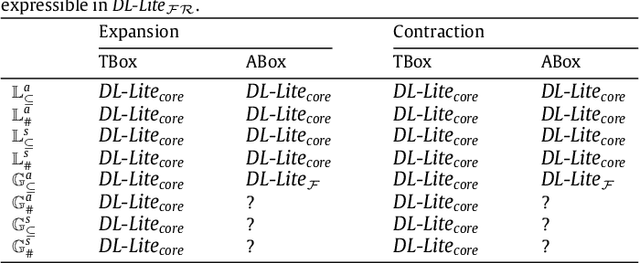
Knowledge bases (KBs) are not static entities: new information constantly appears and some of the previous knowledge becomes obsolete. In order to reflect this evolution of knowledge, KBs should be expanded with the new knowledge and contracted from the obsolete one. This problem is well-studied for propositional but much less for first-order KBs. In this work we investigate knowledge expansion and contraction for KBs expressed in DL-Lite, a family of description logics (DLs) that underlie the tractable fragment OWL 2 QL of the Web Ontology Language OWL 2. We start with a novel knowledge evolution framework and natural postulates that evolution should respect, and compare our postulates to the well-established AGM postulates. We then review well-known model and formula-based approaches for expansion and contraction for propositional theories and show how they can be adapted to the case of DL-Lite. In particular, we show intrinsic limitations of model-based approaches: besides the fact that some of them do not respect the postulates we have established, they ignore the structural properties of KBs. This leads to undesired properties of evolution results: evolution of DL-Lite KBs cannot be captured in DL-Lite. Moreover, we show that well-known formula-based approaches are also not appropriate for DL-Lite expansion and contraction: they either have a high complexity of computation, or they produce logical theories that cannot be expressed in DL-Lite. Thus, we propose a novel formula-based approach that respects our principles and for which evolution is expressible in DL-Lite. For this approach we also propose polynomial time deterministic algorithms to compute evolution of DL-Lite KBs when evolution affects only factual data.
Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]
Sep 20, 2017![Figure 1 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F9-Table2-1.png&w=640&q=75)
In knowledge bases such as Wikidata, it is possible to assert a large set of properties for entities, ranging from generic ones such as name and place of birth to highly profession-specific or background-specific ones such as doctoral advisor or medical condition. Determining a preference or ranking in this large set is a challenge in tasks such as prioritisation of edits or natural-language generation. Most previous approaches to ranking knowledge base properties are purely data-driven, that is, as we show, mistake frequency for interestingness. In this work, we have developed a human-annotated dataset of 350 preference judgments among pairs of knowledge base properties for fixed entities. From this set, we isolate a subset of pairs for which humans show a high level of agreement (87.5% on average). We show, however, that baseline and state-of-the-art techniques achieve only 61.3% precision in predicting human preferences for this subset. We then analyze what contributes to one property being rated as more important than another one, and identify that at least three factors play a role, namely (i) general frequency, (ii) applicability to similar entities and (iii) semantic similarity between property and entity. We experimentally analyze the contribution of each factor and show that a combination of techniques addressing all the three factors achieves 74% precision on the task. The dataset is available at www.kaggle.com/srazniewski/wikidatapropertyranking.
Mapping-equivalence and oid-equivalence of single-function object-creating conjunctive queries
Jan 12, 2016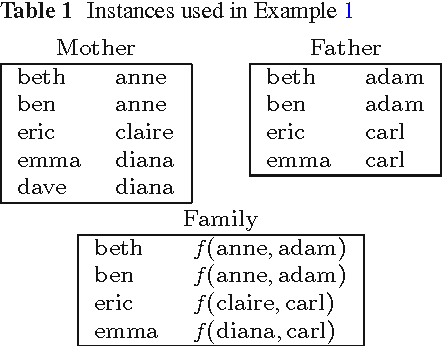
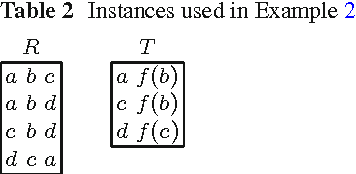
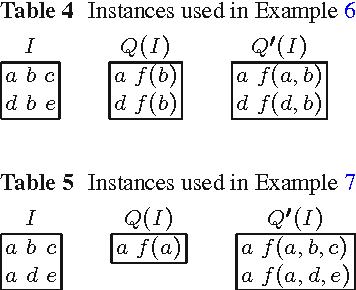
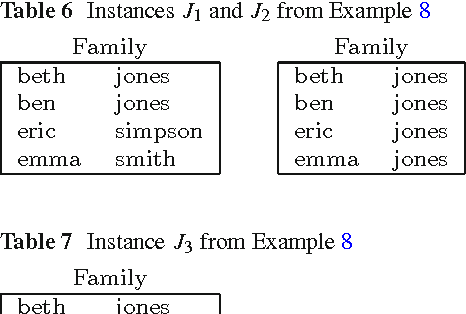
Conjunctive database queries have been extended with a mechanism for object creation to capture important applications such as data exchange, data integration, and ontology-based data access. Object creation generates new object identifiers in the result, that do not belong to the set of constants in the source database. The new object identifiers can be also seen as Skolem terms. Hence, object-creating conjunctive queries can also be regarded as restricted second-order tuple-generating dependencies (SO tgds), considered in the data exchange literature. In this paper, we focus on the class of single-function object-creating conjunctive queries, or sifo CQs for short. We give a new characterization for oid-equivalence of sifo CQs that is simpler than the one given by Hull and Yoshikawa and places the problem in the complexity class NP. Our characterization is based on Cohen's equivalence notions for conjunctive queries with multiplicities. We also solve the logical entailment problem for sifo CQs, showing that also this problem belongs to NP. Results by Pichler et al. have shown that logical equivalence for more general classes of SO tgds is either undecidable or decidable with as yet unknown complexity upper bounds.