 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo that's not what I meant: Handling Third Position Repair in Conversational Question Answering
Jul 31, 2023


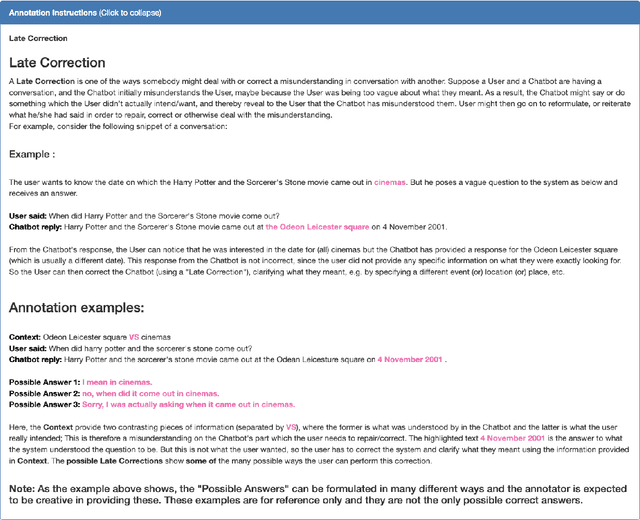
The ability to handle miscommunication is crucial to robust and faithful conversational AI. People usually deal with miscommunication immediately as they detect it, using highly systematic interactional mechanisms called repair. One important type of repair is Third Position Repair (TPR) whereby a speaker is initially misunderstood but then corrects the misunderstanding as it becomes apparent after the addressee's erroneous response. Here, we collect and publicly release Repair-QA, the first large dataset of TPRs in a conversational question answering (QA) setting. The data is comprised of the TPR turns, corresponding dialogue contexts, and candidate repairs of the original turn for execution of TPRs. We demonstrate the usefulness of the data by training and evaluating strong baseline models for executing TPRs. For stand-alone TPR execution, we perform both automatic and human evaluations on a fine-tuned T5 model, as well as OpenAI's GPT-3 LLMs. Additionally, we extrinsically evaluate the LLMs' TPR processing capabilities in the downstream conversational QA task. The results indicate poor out-of-the-box performance on TPR's by the GPT-3 models, which then significantly improves when exposed to Repair-QA.
Domain-Aware Dialogue State Tracker for Multi-Domain Dialogue Systems
Jan 21, 2020

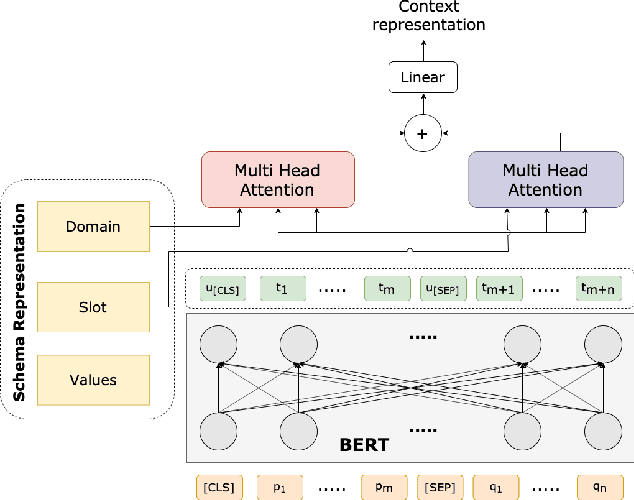
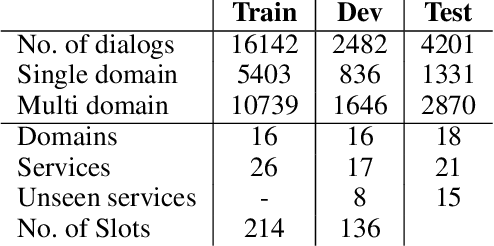
In task-oriented dialogue systems the dialogue state tracker (DST) component is responsible for predicting the state of the dialogue based on the dialogue history. Current DST approaches rely on a predefined domain ontology, a fact that limits their effective usage for large scale conversational agents, where the DST constantly needs to be interfaced with ever-increasing services and APIs. Focused towards overcoming this drawback, we propose a domain-aware dialogue state tracker, that is completely data-driven and it is modeled to predict for dynamic service schemas. The proposed model utilizes domain and slot information to extract both domain and slot specific representations for a given dialogue, and then uses such representations to predict the values of the corresponding slot. Integrating this mechanism with a pretrained language model (i.e. BERT), our approach can effectively learn semantic relations.
A Robust Data-Driven Approach for Dialogue State Tracking of Unseen Slot Values
Nov 01, 2019
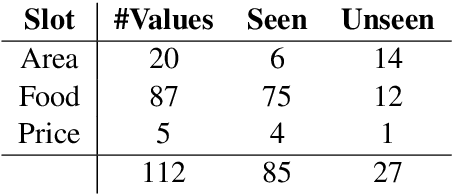

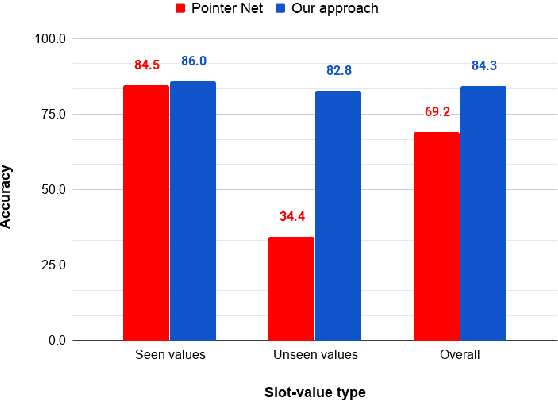
A Dialogue State Tracker is a key component in dialogue systems which estimates the beliefs of possible user goals at each dialogue turn. Deep learning approaches using recurrent neural networks have shown state-of-the-art performance for the task of dialogue state tracking. Generally, these approaches assume a predefined candidate list and struggle to predict any new dialogue state values that are not seen during training. This makes extending the candidate list for a slot without model retaining infeasible and also has limitations in modelling for low resource domains where training data for slot values are expensive. In this paper, we propose a novel dialogue state tracker based on copying mechanism that can effectively track such unseen slot values without compromising performance on slot values seen during training. The proposed model is also flexible in extending the candidate list without requiring any retraining or change in the model. We evaluate the proposed model on various benchmark datasets (DSTC2, DSTC3 and WoZ2.0) and show that our approach, outperform other end-to-end data-driven approaches in tracking unseen slot values and also provides significant advantages in modelling for DST.
Scalable Neural Dialogue State Tracking
Oct 22, 2019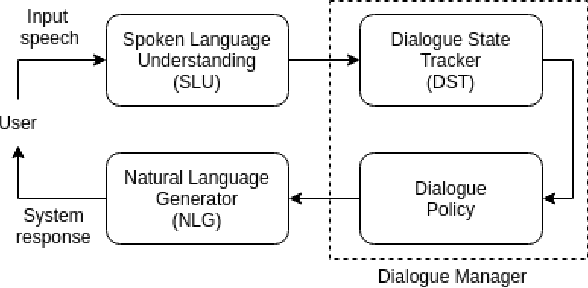
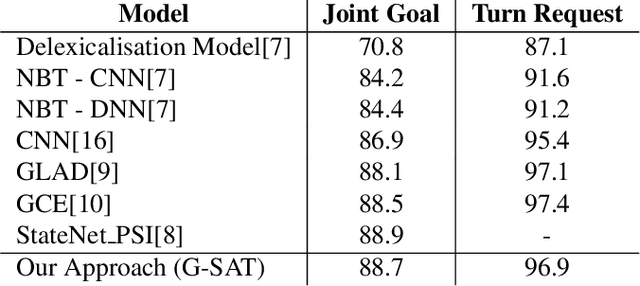


A Dialogue State Tracker (DST) is a key component in a dialogue system aiming at estimating the beliefs of possible user goals at each dialogue turn. Most of the current DST trackers make use of recurrent neural networks and are based on complex architectures that manage several aspects of a dialogue, including the user utterance, the system actions, and the slot-value pairs defined in a domain ontology. However, the complexity of such neural architectures incurs into a considerable latency in the dialogue state prediction, which limits the deployments of the models in real-world applications, particularly when task scalability (i.e. amount of slots) is a crucial factor. In this paper, we propose an innovative neural model for dialogue state tracking, named Global encoder and Slot-Attentive decoders (G-SAT), which can predict the dialogue state with a very low latency time, while maintaining high-level performance. We report experiments on three different languages (English, Italian, and German) of the WoZ2.0 dataset, and show that the proposed approach provides competitive advantages over state-of-art DST systems, both in terms of accuracy and in terms of time complexity for predictions, being over 15 times faster than the other systems.
Benchmarking machine learning models on eICU critical care dataset
Oct 02, 2019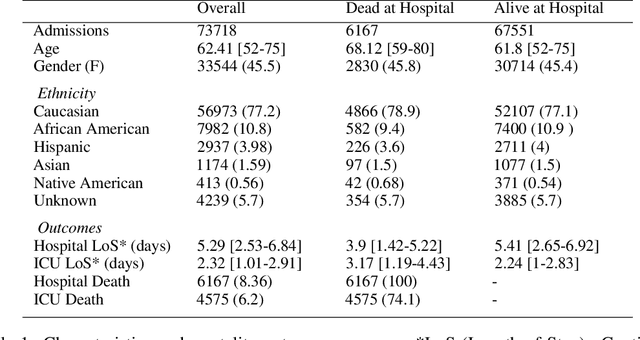
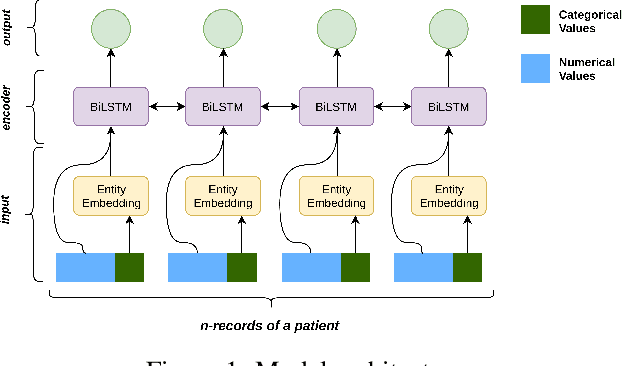

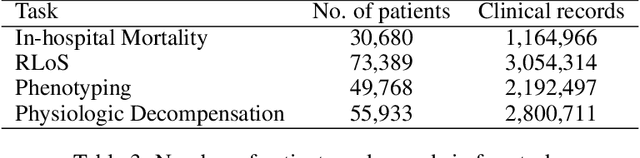
Progress of machine learning in critical care has been difficult to track, in part due to absence of public benchmarks. Other fields of research (such as vision and NLP) have already established various competitions and benchmarks, whereas only recent availability of large clinical datasets has enabled the possibility of public benchmarks. Taking advantage of this opportunity, we propose a public benchmark suite to address four areas of critical care, namely mortality prediction, estimation of length of stay, patient phenotyping and risk of decompensation. We define each task and compare the performance of both clinical models as well as baseline and deep models using eICU critical care dataset of around 73,000 patients. Furthermore, we investigate the impact of numerical variables as well as handling of categorical variables for each of the defined tasks.
Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]
Sep 20, 2017![Figure 1 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F3-Figure1-1.png&w=640&q=75)
![Figure 2 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F8-Table1-1.png&w=640&q=75)
![Figure 3 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for Doctoral Advisor or Medical Condition: Towards Entity-specific Rankings of Knowledge Base Properties [Extended Version]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fef605ac495fac09604eb0f2ed0a6854772e6ae51%2F9-Table2-1.png&w=640&q=75)
In knowledge bases such as Wikidata, it is possible to assert a large set of properties for entities, ranging from generic ones such as name and place of birth to highly profession-specific or background-specific ones such as doctoral advisor or medical condition. Determining a preference or ranking in this large set is a challenge in tasks such as prioritisation of edits or natural-language generation. Most previous approaches to ranking knowledge base properties are purely data-driven, that is, as we show, mistake frequency for interestingness. In this work, we have developed a human-annotated dataset of 350 preference judgments among pairs of knowledge base properties for fixed entities. From this set, we isolate a subset of pairs for which humans show a high level of agreement (87.5% on average). We show, however, that baseline and state-of-the-art techniques achieve only 61.3% precision in predicting human preferences for this subset. We then analyze what contributes to one property being rated as more important than another one, and identify that at least three factors play a role, namely (i) general frequency, (ii) applicability to similar entities and (iii) semantic similarity between property and entity. We experimentally analyze the contribution of each factor and show that a combination of techniques addressing all the three factors achieves 74% precision on the task. The dataset is available at www.kaggle.com/srazniewski/wikidatapropertyranking.