 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlanaVLM: A Multimodal Embodied AI Foundation Model for Egocentric Video Understanding
Jun 19, 2024AI personal assistants deployed via robots or wearables require embodied understanding to collaborate with humans effectively. However, current Vision-Language Models (VLMs) primarily focus on third-person view videos, neglecting the richness of egocentric perceptual experience. To address this gap, we propose three key contributions. First, we introduce the Egocentric Video Understanding Dataset (EVUD) for training VLMs on video captioning and question answering tasks specific to egocentric videos. Second, we present AlanaVLM, a 7B parameter VLM trained using parameter-efficient methods on EVUD. Finally, we evaluate AlanaVLM's capabilities on OpenEQA, a challenging benchmark for embodied video question answering. Our model achieves state-of-the-art performance, outperforming open-source models including strong Socratic models using GPT-4 as a planner by 3.6%. Additionally, we outperform Claude 3 and Gemini Pro Vision 1.0 and showcase competitive results compared to Gemini Pro 1.5 and GPT-4V, even surpassing the latter in spatial reasoning. This research paves the way for building efficient VLMs that can be deployed in robots or wearables, leveraging embodied video understanding to collaborate seamlessly with humans in everyday tasks, contributing to the next generation of Embodied AI
No that's not what I meant: Handling Third Position Repair in Conversational Question Answering
Jul 31, 2023


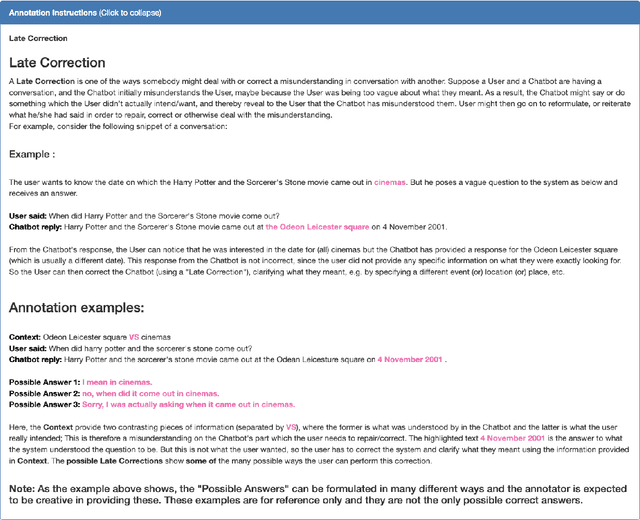
The ability to handle miscommunication is crucial to robust and faithful conversational AI. People usually deal with miscommunication immediately as they detect it, using highly systematic interactional mechanisms called repair. One important type of repair is Third Position Repair (TPR) whereby a speaker is initially misunderstood but then corrects the misunderstanding as it becomes apparent after the addressee's erroneous response. Here, we collect and publicly release Repair-QA, the first large dataset of TPRs in a conversational question answering (QA) setting. The data is comprised of the TPR turns, corresponding dialogue contexts, and candidate repairs of the original turn for execution of TPRs. We demonstrate the usefulness of the data by training and evaluating strong baseline models for executing TPRs. For stand-alone TPR execution, we perform both automatic and human evaluations on a fine-tuned T5 model, as well as OpenAI's GPT-3 LLMs. Additionally, we extrinsically evaluate the LLMs' TPR processing capabilities in the downstream conversational QA task. The results indicate poor out-of-the-box performance on TPR's by the GPT-3 models, which then significantly improves when exposed to Repair-QA.
The Dangers of trusting Stochastic Parrots: Faithfulness and Trust in Open-domain Conversational Question Answering
May 25, 2023



Large language models are known to produce output which sounds fluent and convincing, but is also often wrong, e.g. "unfaithful" with respect to a rationale as retrieved from a knowledge base. In this paper, we show that task-based systems which exhibit certain advanced linguistic dialog behaviors, such as lexical alignment (repeating what the user said), are in fact preferred and trusted more, whereas other phenomena, such as pronouns and ellipsis are dis-preferred. We use open-domain question answering systems as our test-bed for task based dialog generation and compare several open- and closed-book models. Our results highlight the danger of systems that appear to be trustworthy by parroting user input while providing an unfaithful response.
MuMMER: Socially Intelligent Human-Robot Interaction in Public Spaces
Sep 15, 2019
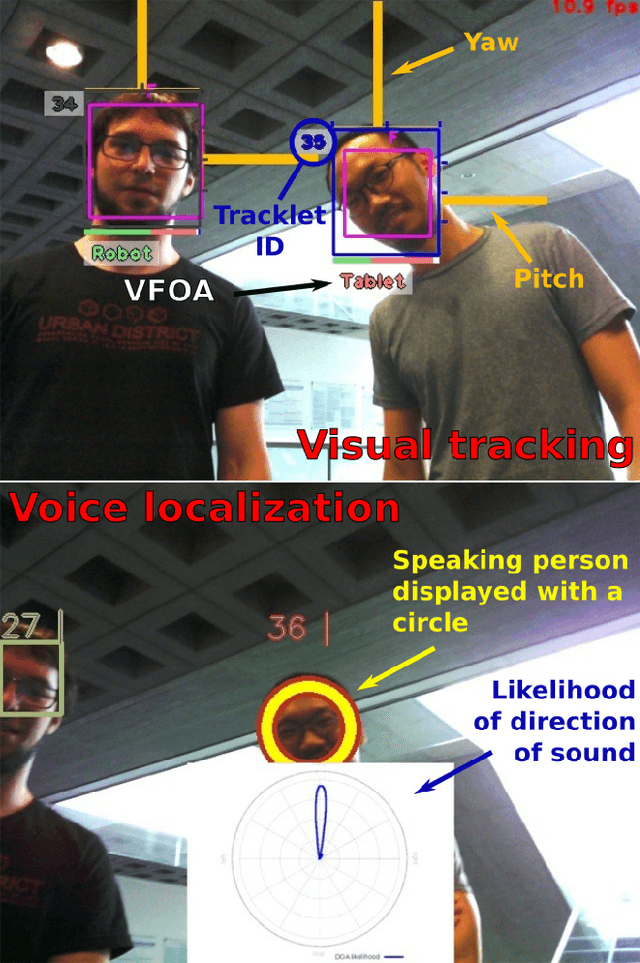

In the EU-funded MuMMER project, we have developed a social robot designed to interact naturally and flexibly with users in public spaces such as a shopping mall. We present the latest version of the robot system developed during the project. This system encompasses audio-visual sensing, social signal processing, conversational interaction, perspective taking, geometric reasoning, and motion planning. It successfully combines all these components in an overarching framework using the Robot Operating System (ROS) and has been deployed to a shopping mall in Finland interacting with customers. In this paper, we describe the system components, their interplay, and the resulting robot behaviours and scenarios provided at the shopping mall.
Petri Net Machines for Human-Agent Interaction
Sep 13, 2019
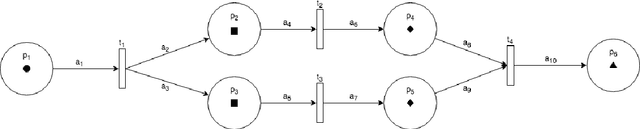
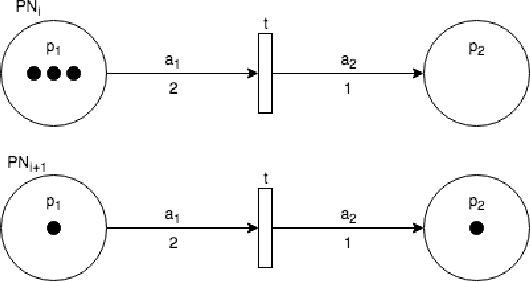
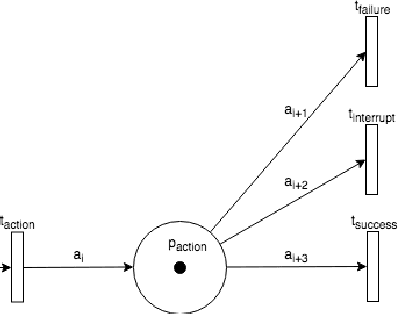
Smart speakers and robots become ever more prevalent in our daily lives. These agents are able to execute a wide range of tasks and actions and, therefore, need systems to control their execution. Current state-of-the-art such as (deep) reinforcement learning, however, requires vast amounts of data for training which is often hard to come by when interacting with humans. To overcome this issue, most systems still rely on Finite State Machines. We introduce Petri Net Machines which present a formal definition for state machines based on Petri Nets that are able to execute concurrent actions reliably, execute and interleave several plans at the same time, and provide an easy to use modelling language. We show their workings based on the example of Human-Robot Interaction in a shopping mall.
An Ensemble Model with Ranking for Social Dialogue
Dec 20, 2017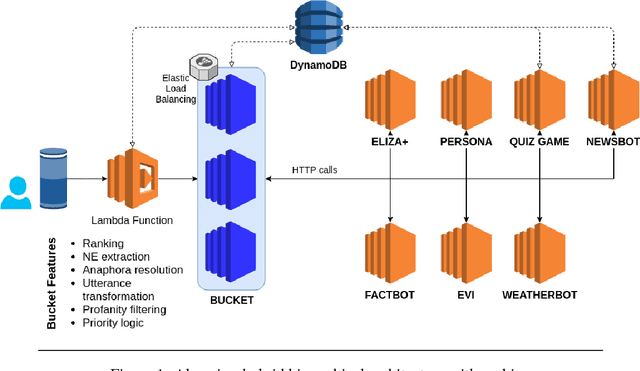

Open-domain social dialogue is one of the long-standing goals of Artificial Intelligence. This year, the Amazon Alexa Prize challenge was announced for the first time, where real customers get to rate systems developed by leading universities worldwide. The aim of the challenge is to converse "coherently and engagingly with humans on popular topics for 20 minutes". We describe our Alexa Prize system (called 'Alana') consisting of an ensemble of bots, combining rule-based and machine learning systems, and using a contextual ranking mechanism to choose a system response. The ranker was trained on real user feedback received during the competition, where we address the problem of how to train on the noisy and sparse feedback obtained during the competition.
Sympathy Begins with a Smile, Intelligence Begins with a Word: Use of Multimodal Features in Spoken Human-Robot Interaction
Jun 08, 2017


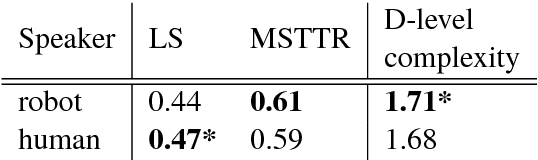
Recognition of social signals, from human facial expressions or prosody of speech, is a popular research topic in human-robot interaction studies. There is also a long line of research in the spoken dialogue community that investigates user satisfaction in relation to dialogue characteristics. However, very little research relates a combination of multimodal social signals and language features detected during spoken face-to-face human-robot interaction to the resulting user perception of a robot. In this paper we show how different emotional facial expressions of human users, in combination with prosodic characteristics of human speech and features of human-robot dialogue, correlate with users' impressions of the robot after a conversation. We find that happiness in the user's recognised facial expression strongly correlates with likeability of a robot, while dialogue-related features (such as number of human turns or number of sentences per robot utterance) correlate with perceiving a robot as intelligent. In addition, we show that facial expression, emotional features, and prosody are better predictors of human ratings related to perceived robot likeability and anthropomorphism, while linguistic and non-linguistic features more often predict perceived robot intelligence and interpretability. As such, these characteristics may in future be used as an online reward signal for in-situ Reinforcement Learning based adaptive human-robot dialogue systems.