 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesture Generation from Trimodal Context for Humanoid Robots
Sep 08, 2024Natural co-speech gestures are essential components to improve the experience of Human-robot interaction (HRI). However, current gesture generation approaches have many limitations of not being natural, not aligning with the speech and content, or the lack of diverse speaker styles. Therefore, this work aims to repoduce the work by Yoon et,al generating natural gestures in simulation based on tri-modal inputs and apply this to a robot. During evaluation, ``motion variance'' and ``Frechet Gesture Distance (FGD)'' is employed to evaluate the performance objectively. Then, human participants were recruited to subjectively evaluate the gestures. Results show that the movements in that paper have been successfully transferred to the robot and the gestures have diverse styles and are correlated with the speech. Moreover, there is a significant likeability and style difference between different gestures.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
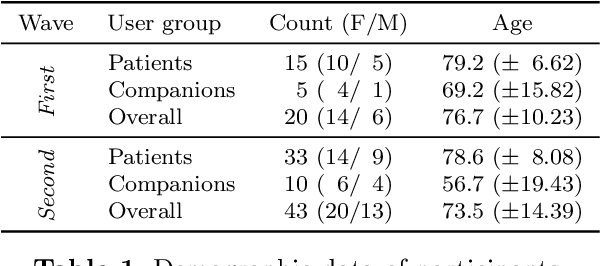
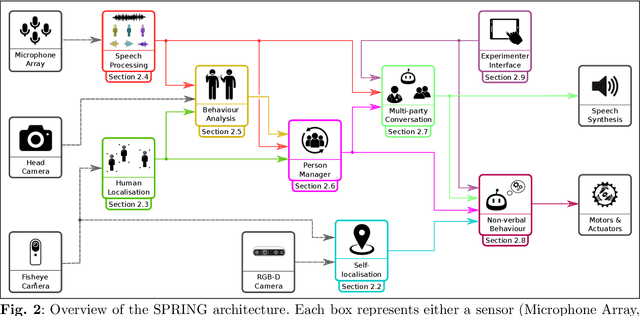
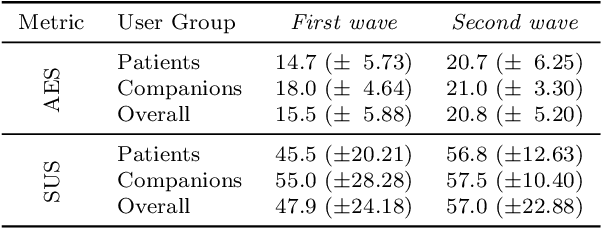
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Come Closer: The Effects of Robot Personality on Human Proxemics Behaviours
Sep 06, 2023



Social Robots in human environments need to be able to reason about their physical surroundings while interacting with people. Furthermore, human proxemics behaviours around robots can indicate how people perceive the robots and can inform robot personality and interaction design. Here, we introduce Charlie, a situated robot receptionist that can interact with people using verbal and non-verbal communication in a dynamic environment, where users might enter or leave the scene at any time. The robot receptionist is stationary and cannot navigate. Therefore, people have full control over their personal space as they are the ones approaching the robot. We investigated the influence of different apparent robot personalities on the proxemics behaviours of the humans. The results indicate that different types of robot personalities, specifically introversion and extroversion, can influence human proxemics behaviours. Participants maintained shorter distances with the introvert robot receptionist, compared to the extrovert robot. Interestingly, we observed that human-robot proxemics were not the same as typical human-human interpersonal distances, as defined in the literature. We therefore propose new proxemics zones for human-robot interaction.
Multi-party Goal Tracking with LLMs: Comparing Pre-training, Fine-tuning, and Prompt Engineering
Aug 29, 2023


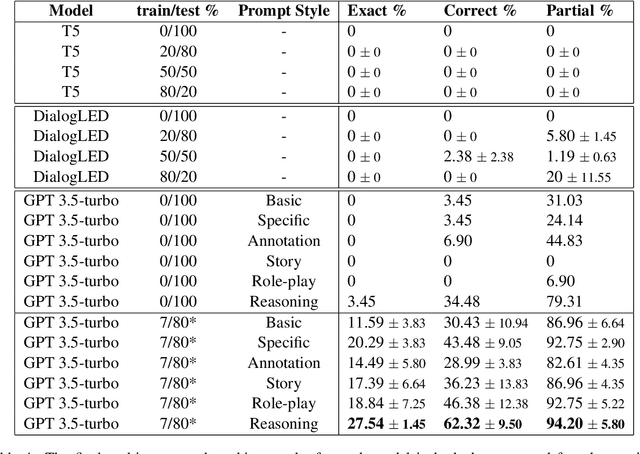
This paper evaluates the extent to which current Large Language Models (LLMs) can capture task-oriented multi-party conversations (MPCs). We have recorded and transcribed 29 MPCs between patients, their companions, and a social robot in a hospital. We then annotated this corpus for multi-party goal-tracking and intent-slot recognition. People share goals, answer each other's goals, and provide other people's goals in MPCs - none of which occur in dyadic interactions. To understand user goals in MPCs, we compared three methods in zero-shot and few-shot settings: we fine-tuned T5, created pre-training tasks to train DialogLM using LED, and employed prompt engineering techniques with GPT-3.5-turbo, to determine which approach can complete this novel task with limited data. GPT-3.5-turbo significantly outperformed the others in a few-shot setting. The `reasoning' style prompt, when given 7% of the corpus as example annotated conversations, was the best performing method. It correctly annotated 62.32% of the goal tracking MPCs, and 69.57% of the intent-slot recognition MPCs. A `story' style prompt increased model hallucination, which could be detrimental if deployed in safety-critical settings. We conclude that multi-party conversations still challenge state-of-the-art LLMs.
SimpleMTOD: A Simple Language Model for Multimodal Task-Oriented Dialogue with Symbolic Scene Representation
Jul 10, 2023



SimpleMTOD is a simple language model which recasts several sub-tasks in multimodal task-oriented dialogues as sequence prediction tasks. SimpleMTOD is built on a large-scale transformer-based auto-regressive architecture, which has already proven to be successful in uni-modal task-oriented dialogues, and effectively leverages transfer learning from pre-trained GPT-2. In-order to capture the semantics of visual scenes, we introduce both local and de-localized tokens for objects within a scene. De-localized tokens represent the type of an object rather than the specific object itself and so possess a consistent meaning across the dataset. SimpleMTOD achieves a state-of-the-art BLEU score (0.327) in the Response Generation sub-task of the SIMMC 2.0 test-std dataset while performing on par in other multimodal sub-tasks: Disambiguation, Coreference Resolution, and Dialog State Tracking. This is despite taking a minimalist approach for extracting visual (and non-visual) information. In addition the model does not rely on task-specific architectural changes such as classification heads.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2020
Nov 11, 2020The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. In that time, the related topic of trust in robotics has been rapidly growing, with major research efforts at universities and laboratories across the world. Indeed, many of the past participants in AI-HRI have been or are now involved with research into trust in HRI. While trust has no consensus definition, it is regularly associated with predictability, reliability, inciting confidence, and meeting expectations. Furthermore, it is generally believed that trust is crucial for adoption of both AI and robotics, particularly when transitioning technologies from the lab to industrial, social, and consumer applications. However, how does trust apply to the specific situations we encounter in the AI-HRI sphere? Is the notion of trust in AI the same as that in HRI? We see a growing need for research that lives directly at the intersection of AI and HRI that is serviced by this symposium. Over the course of the two-day meeting, we propose to create a collaborative forum for discussion of current efforts in trust for AI-HRI, with a sub-session focused on the related topic of explainable AI (XAI) for HRI.
Explainable Representations of the Social State: A Model for Social Human-Robot Interactions
Oct 09, 2020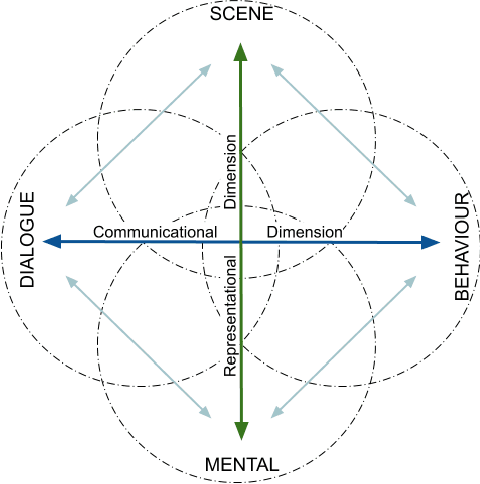
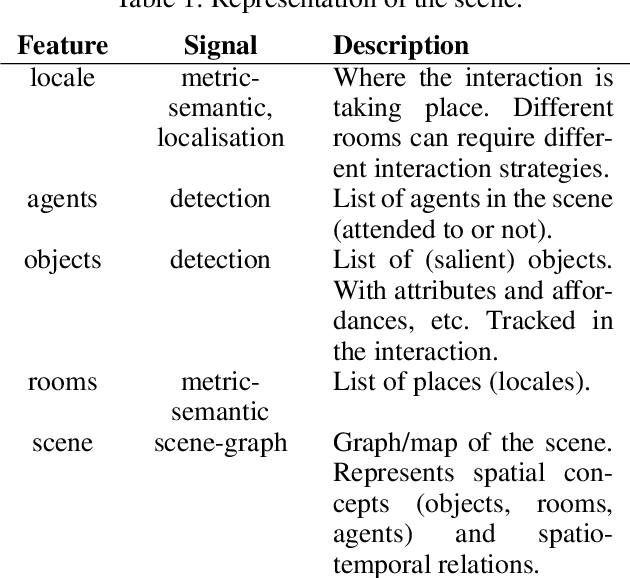


In this paper, we propose a minimum set of concepts and signals needed to track the social state during Human-Robot Interaction. We look into the problem of complex continuous interactions in a social context with multiple humans and robots, and discuss the creation of an explainable and tractable representation/model of their social interaction. We discuss these representations according to their representational and communicational properties, and organize them into four cognitive domains (scene-understanding, behaviour-profiling, mental-state, and dialogue-grounding).
Robots in the Danger Zone: Exploring Public Perception through Engagement
Apr 01, 2020
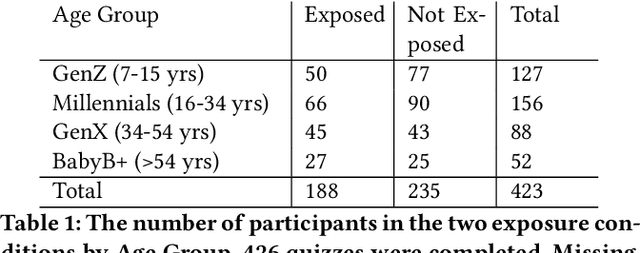

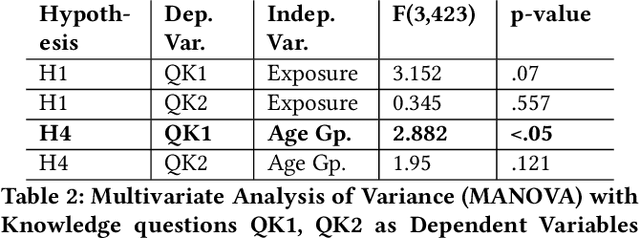
Public perceptions of Robotics and Artificial Intelligence (RAI) are important in the acceptance, uptake, government regulation and research funding of this technology. Recent research has shown that the public's understanding of RAI can be negative or inaccurate. We believe effective public engagement can help ensure that public opinion is better informed. In this paper, we describe our first iteration of a high throughput in-person public engagement activity. We describe the use of a light touch quiz-format survey instrument to integrate in-the-wild research participation into the engagement, allowing us to probe both the effectiveness of our engagement strategy, and public perceptions of the future roles of robots and humans working in dangerous settings, such as in the off-shore energy sector. We critique our methods and share interesting results into generational differences within the public's view of the future of Robotics and AI in hazardous environments. These findings include that older peoples' views about the future of robots in hazardous environments were not swayed by exposure to our exhibit, while the views of younger people were affected by our exhibit, leading us to consider carefully in future how to more effectively engage with and inform older people.
* Accepted in HRI 2020, Keywords: Human robot interaction, robotics, artificial intelligence, public engagement, public perceptions of robots, robotics and society
MuMMER: Socially Intelligent Human-Robot Interaction in Public Spaces
Sep 15, 2019
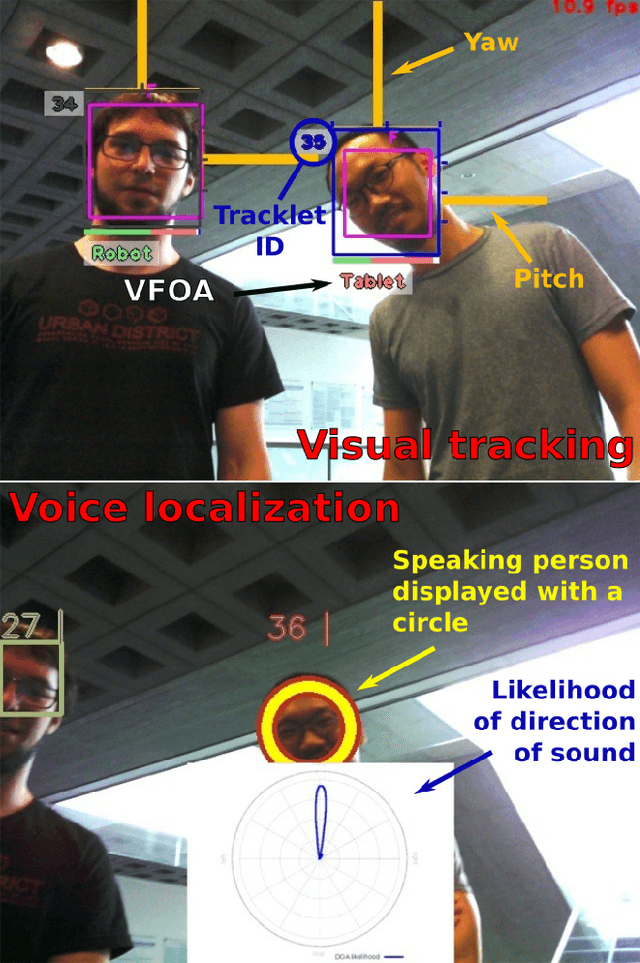

In the EU-funded MuMMER project, we have developed a social robot designed to interact naturally and flexibly with users in public spaces such as a shopping mall. We present the latest version of the robot system developed during the project. This system encompasses audio-visual sensing, social signal processing, conversational interaction, perspective taking, geometric reasoning, and motion planning. It successfully combines all these components in an overarching framework using the Robot Operating System (ROS) and has been deployed to a shopping mall in Finland interacting with customers. In this paper, we describe the system components, their interplay, and the resulting robot behaviours and scenarios provided at the shopping mall.
Petri Net Machines for Human-Agent Interaction
Sep 13, 2019
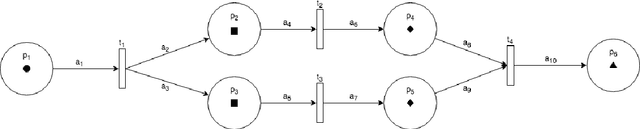
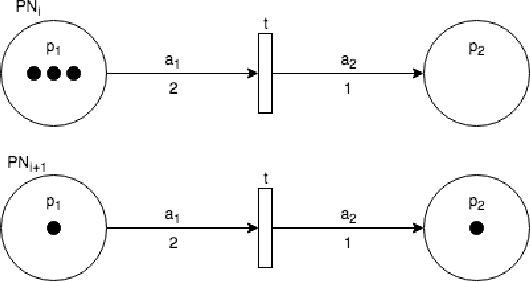
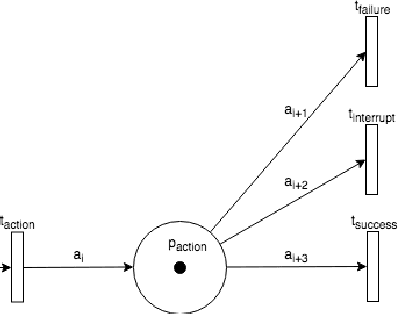
Smart speakers and robots become ever more prevalent in our daily lives. These agents are able to execute a wide range of tasks and actions and, therefore, need systems to control their execution. Current state-of-the-art such as (deep) reinforcement learning, however, requires vast amounts of data for training which is often hard to come by when interacting with humans. To overcome this issue, most systems still rely on Finite State Machines. We introduce Petri Net Machines which present a formal definition for state machines based on Petri Nets that are able to execute concurrent actions reliably, execute and interleave several plans at the same time, and provide an easy to use modelling language. We show their workings based on the example of Human-Robot Interaction in a shopping mall.