 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPO-PDT: Demonstrating Role-Play-Based Knowledge Adaptation for Student Support Dialogue (Demonstration System)
Jun 08, 2026We present RPO-PDT: a retrieval-grounded, role-play-based dialogue system for adaptive student support in higher education. RPO-PDT is: (1) able to provide institution-specific Personal Development Tutor (PDT) guidance using structured knowledge sources; (2) constrained by explicit persona, boundary, confidentiality, and safety policies; and (3) designed around a reverse-roleplay loop where unresolved interactions are replayed from the student perspective, enabling alternative tutor strategies to be generated and stored as reusable strategy memory. RPO-PDT supports both text-based and Furhat-based embodied interaction for demonstrating grounded, safe, and adaptive student-support dialogue.
SafeCtrl-RL: Inference-Time Adaptive Behaviour Control for LLM Dialogue via RL-Driven Prompt Optimisation
May 25, 2026Ensuring safe and contextually appropriate behaviour in Large Language Models (LLMs) remains a critical challenge for real-world deployment. We present \textbf{SafeCtrl-RL}, an inference-time behavioural control framework that enables adaptive safety regulation without model retraining or parameter modification. The method formulates dialogue generation as a sequential decision process, where a reinforcement learning agent dynamically selects prompt adjustment strategies based on contextual feedback. This allows unsafe behaviours to be suppressed through iterative refinement, which we conceptualise as inference-time behavioural unlearning. Evaluated across multiple LLMs and unsafe dialogue scenarios, SafeCtrl-RL consistently improves safety and response quality, outperforms existing prompt-based optimisation methods, and achieves favourable performance--efficiency trade-offs. **Warning: This paper may contain examples of harmful language, and reader discretion is recommended.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
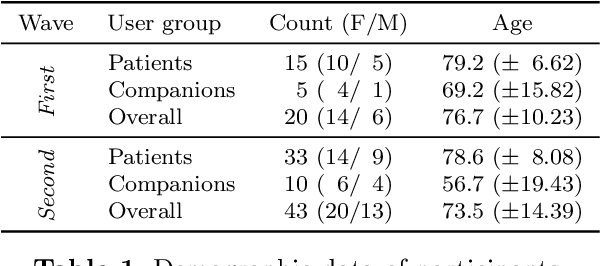
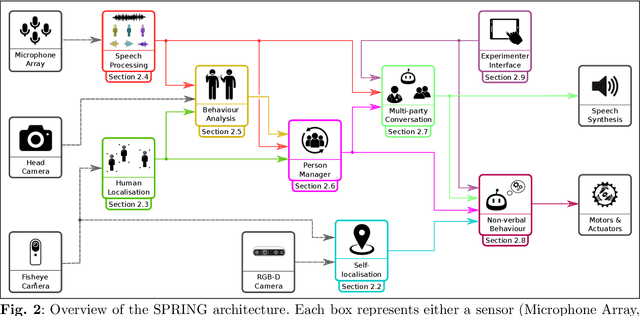
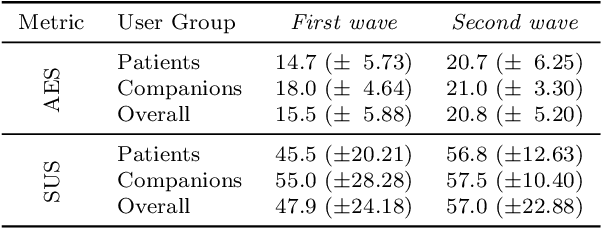
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Explainable Representations of the Social State: A Model for Social Human-Robot Interactions
Oct 09, 2020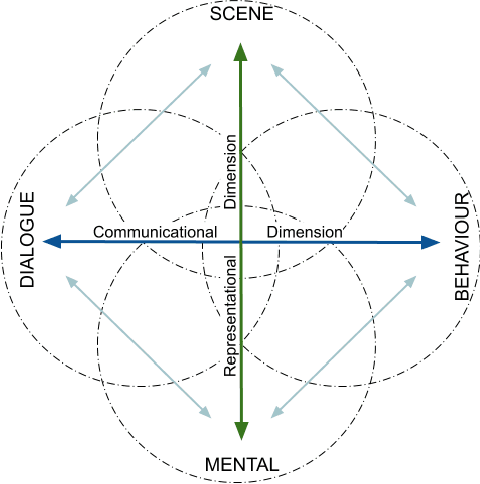
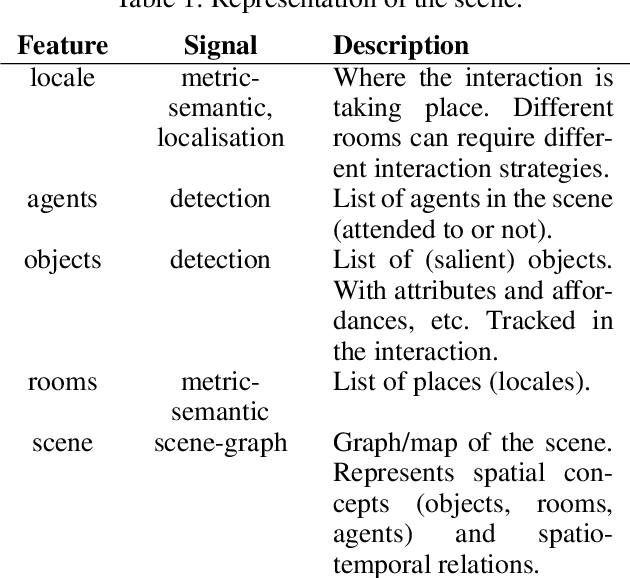


In this paper, we propose a minimum set of concepts and signals needed to track the social state during Human-Robot Interaction. We look into the problem of complex continuous interactions in a social context with multiple humans and robots, and discuss the creation of an explainable and tractable representation/model of their social interaction. We discuss these representations according to their representational and communicational properties, and organize them into four cognitive domains (scene-understanding, behaviour-profiling, mental-state, and dialogue-grounding).
An Ensemble Model with Ranking for Social Dialogue
Dec 20, 2017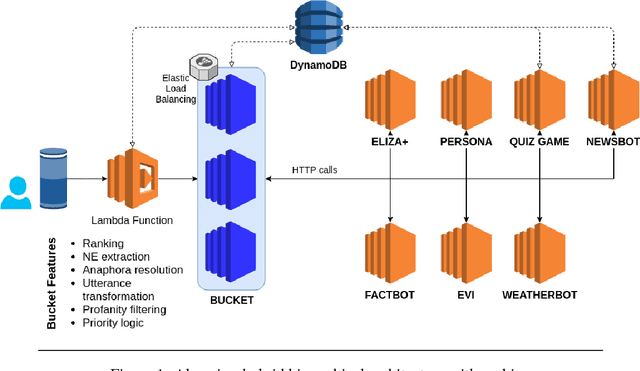

Open-domain social dialogue is one of the long-standing goals of Artificial Intelligence. This year, the Amazon Alexa Prize challenge was announced for the first time, where real customers get to rate systems developed by leading universities worldwide. The aim of the challenge is to converse "coherently and engagingly with humans on popular topics for 20 minutes". We describe our Alexa Prize system (called 'Alana') consisting of an ensemble of bots, combining rule-based and machine learning systems, and using a contextual ranking mechanism to choose a system response. The ranker was trained on real user feedback received during the competition, where we address the problem of how to train on the noisy and sparse feedback obtained during the competition.
The BURCHAK corpus: a Challenge Data Set for Interactive Learning of Visually Grounded Word Meanings
Sep 29, 2017
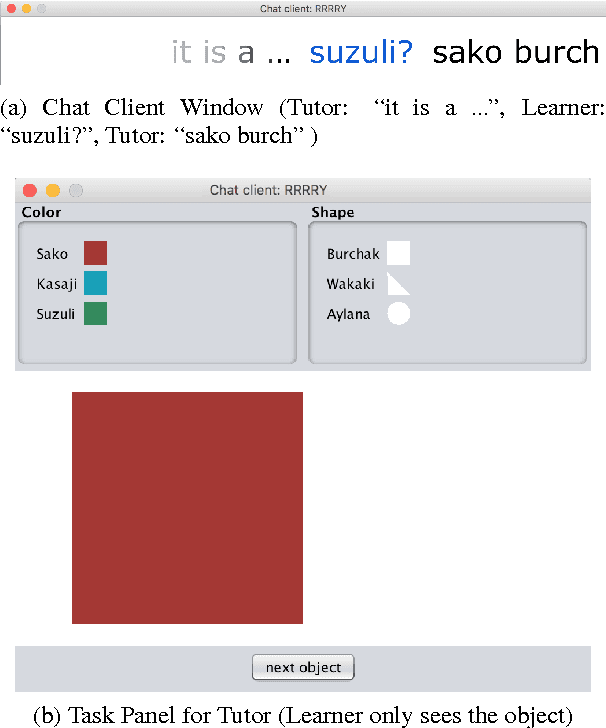

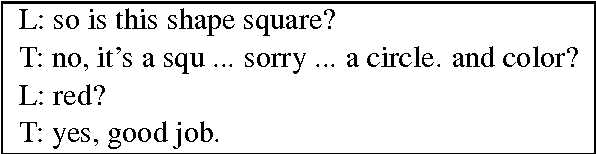
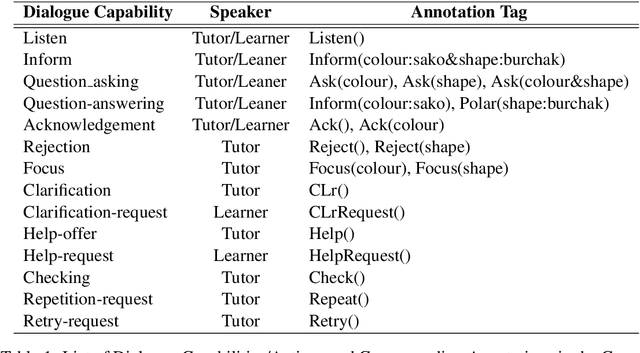
We motivate and describe a new freely available human-human dialogue dataset for interactive learning of visually grounded word meanings through ostensive definition by a tutor to a learner. The data has been collected using a novel, character-by-character variant of the DiET chat tool (Healey et al., 2003; Mills and Healey, submitted) with a novel task, where a Learner needs to learn invented visual attribute words (such as " burchak " for square) from a tutor. As such, the text-based interactions closely resemble face-to-face conversation and thus contain many of the linguistic phenomena encountered in natural, spontaneous dialogue. These include self-and other-correction, mid-sentence continuations, interruptions, overlaps, fillers, and hedges. We also present a generic n-gram framework for building user (i.e. tutor) simulations from this type of incremental data, which is freely available to researchers. We show that the simulations produce outputs that are similar to the original data (e.g. 78% turn match similarity). Finally, we train and evaluate a Reinforcement Learning dialogue control agent for learning visually grounded word meanings, trained from the BURCHAK corpus. The learned policy shows comparable performance to a rule-based system built previously.
Training an adaptive dialogue policy for interactive learning of visually grounded word meanings
Sep 29, 2017

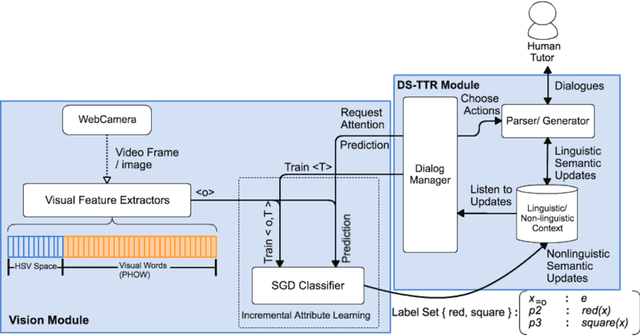
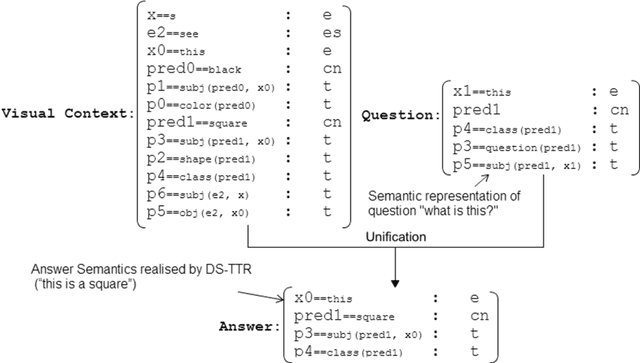
We present a multi-modal dialogue system for interactive learning of perceptually grounded word meanings from a human tutor. The system integrates an incremental, semantic parsing/generation framework - Dynamic Syntax and Type Theory with Records (DS-TTR) - with a set of visual classifiers that are learned throughout the interaction and which ground the meaning representations that it produces. We use this system in interaction with a simulated human tutor to study the effects of different dialogue policies and capabilities on the accuracy of learned meanings, learning rates, and efforts/costs to the tutor. We show that the overall performance of the learning agent is affected by (1) who takes initiative in the dialogues; (2) the ability to express/use their confidence level about visual attributes; and (3) the ability to process elliptical and incrementally constructed dialogue turns. Ultimately, we train an adaptive dialogue policy which optimises the trade-off between classifier accuracy and tutoring costs.
Learning how to learn: an adaptive dialogue agent for incrementally learning visually grounded word meanings
Sep 29, 2017

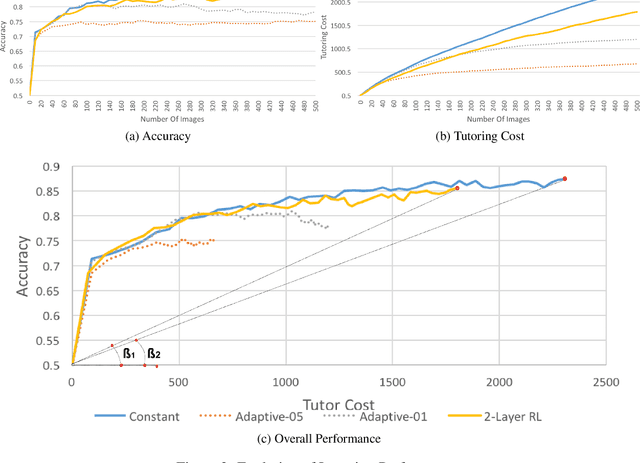
We present an optimised multi-modal dialogue agent for interactive learning of visually grounded word meanings from a human tutor, trained on real human-human tutoring data. Within a life-long interactive learning period, the agent, trained using Reinforcement Learning (RL), must be able to handle natural conversations with human users and achieve good learning performance (accuracy) while minimising human effort in the learning process. We train and evaluate this system in interaction with a simulated human tutor, which is built on the BURCHAK corpus -- a Human-Human Dialogue dataset for the visual learning task. The results show that: 1) The learned policy can coherently interact with the simulated user to achieve the goal of the task (i.e. learning visual attributes of objects, e.g. colour and shape); and 2) it finds a better trade-off between classifier accuracy and tutoring costs than hand-crafted rule-based policies, including ones with dynamic policies.