 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Pose: A Decoupled Approach for Depth-based 3D Human Pose Estimation
Nov 10, 2020


We propose to leverage recent advances in reliable 2D pose estimation with Convolutional Neural Networks (CNN) to estimate the 3D pose of people from depth images in multi-person Human-Robot Interaction (HRI) scenarios. Our method is based on the observation that using the depth information to obtain 3D lifted points from 2D body landmark detections provides a rough estimate of the true 3D human pose, thus requiring only a refinement step. In that line our contributions are threefold. (i) we propose to perform 3D pose estimation from depth images by decoupling 2D pose estimation and 3D pose refinement; (ii) we propose a deep-learning approach that regresses the residual pose between the lifted 3D pose and the true 3D pose; (iii) we show that despite its simplicity, our approach achieves very competitive results both in accuracy and speed on two public datasets and is therefore appealing for multi-person HRI compared to recent state-of-the-art methods.
Efficient Convolutional Neural Networks for Depth-Based Multi-Person Pose Estimation
Dec 02, 2019
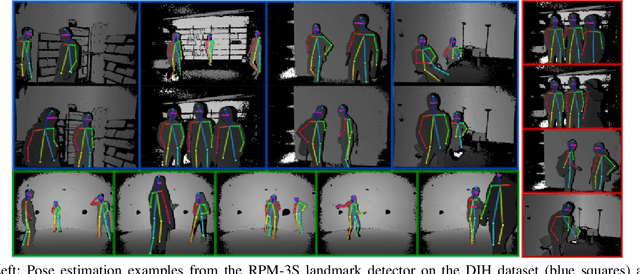
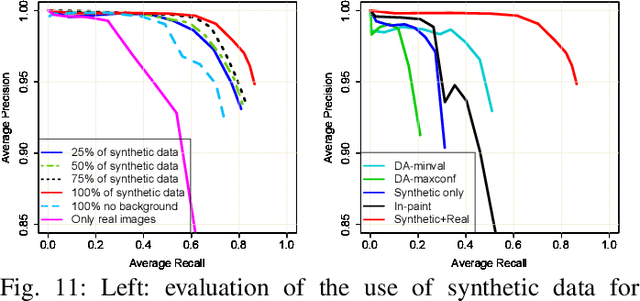

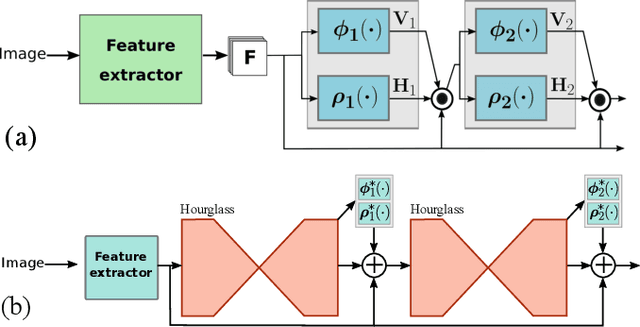
Achieving robust multi-person 2D body landmark localization and pose estimation is essential for human behavior and interaction understanding as encountered for instance in HRI settings. Accurate methods have been proposed recently, but they usually rely on rather deep Convolutional Neural Network (CNN) architecture, thus requiring large computational and training resources. In this paper, we investigate different architectures and methodologies to address these issues and achieve fast and accurate multi-person 2D pose estimation. To foster speed, we propose to work with depth images, whose structure contains sufficient information about body landmarks while being simpler than textured color images and thus potentially requiring less complex CNNs for processing. In this context, we make the following contributions. i) we study several CNN architecture designs combining pose machines relying on the cascade of detectors concept with lightweight and efficient CNN structures; ii) to address the need for large training datasets with high variability, we rely on semi-synthetic data combining multi-person synthetic depth data with real sensor backgrounds; iii) we explore domain adaptation techniques to address the performance gap introduced by testing on real depth images; iv) to increase the accuracy of our fast lightweight CNN models, we investigate knowledge distillation at several architecture levels which effectively enhance performance. Experiments and results on synthetic and real data highlight the impact of our design choices, providing insights into methods addressing standard issues normally faced in practical applications, and resulting in architectures effectively matching our goal in both performance and speed.
Real-time Convolutional Networks for Depth-based Human Pose Estimation
Oct 30, 2019

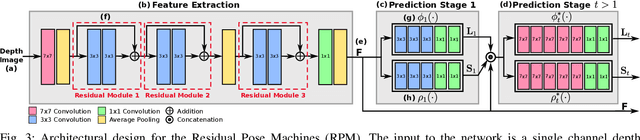

We propose to combine recent Convolutional Neural Networks (CNN) models with depth imaging to obtain a reliable and fast multi-person pose estimation algorithm applicable to Human Robot Interaction (HRI) scenarios. Our hypothesis is that depth images contain less structures and are easier to process than RGB images while keeping the required information for human detection and pose inference, thus allowing the use of simpler networks for the task. Our contributions are threefold. (i) we propose a fast and efficient network based on residual blocks (called RPM) for body landmark localization from depth images; (ii) we created a public dataset DIH comprising more than 170k synthetic images of human bodies with various shapes and viewpoints as well as real (annotated) data for evaluation; (iii) we show that our model trained on synthetic data from scratch can perform well on real data, obtaining similar results to larger models initialized with pre-trained networks. It thus provides a good trade-off between performance and computation. Experiments on real data demonstrate the validity of our approach.
* Published in IROS 2018
MuMMER: Socially Intelligent Human-Robot Interaction in Public Spaces
Sep 15, 2019
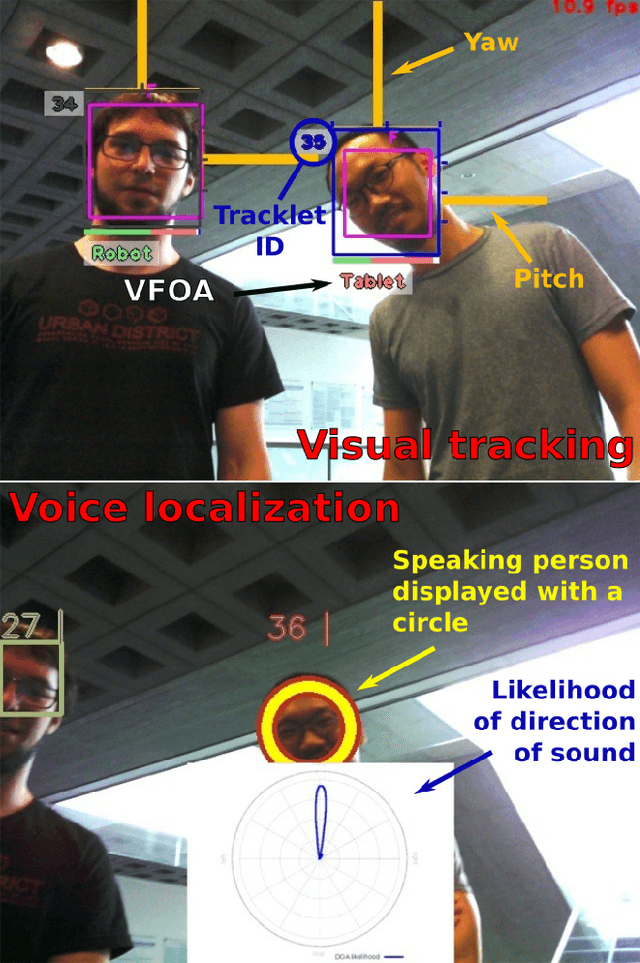

In the EU-funded MuMMER project, we have developed a social robot designed to interact naturally and flexibly with users in public spaces such as a shopping mall. We present the latest version of the robot system developed during the project. This system encompasses audio-visual sensing, social signal processing, conversational interaction, perspective taking, geometric reasoning, and motion planning. It successfully combines all these components in an overarching framework using the Robot Operating System (ROS) and has been deployed to a shopping mall in Finland interacting with customers. In this paper, we describe the system components, their interplay, and the resulting robot behaviours and scenarios provided at the shopping mall.