 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Repair of Process Models with Non-Local Constraints Using State-Based Region Theory
Jun 26, 2021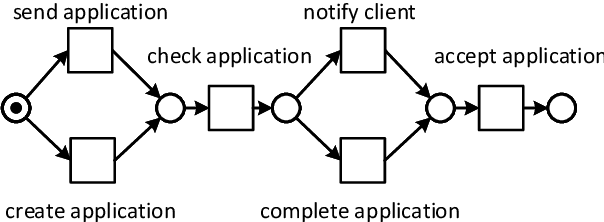
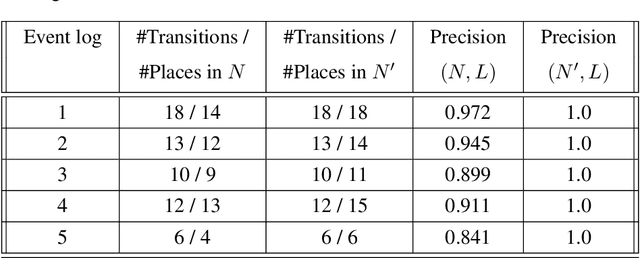
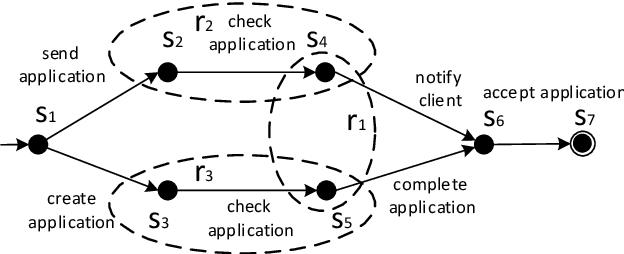
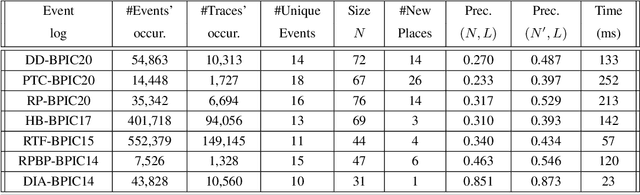
State-of-the-art process discovery methods construct free-choice process models from event logs. Consequently, the constructed models do not take into account indirect dependencies between events. Whenever the input behaviour is not free-choice, these methods fail to provide a precise model. In this paper, we propose a novel approach for enhancing free-choice process models by adding non-free-choice constructs discovered a-posteriori via region-based techniques. This allows us to benefit from the performance of existing process discovery methods and the accuracy of the employed fundamental synthesis techniques. We prove that the proposed approach preserves fitness with respect to the event log while improving the precision when indirect dependencies exist. The approach has been implemented and tested on both synthetic and real-life datasets. The results show its effectiveness in repairing models discovered from event logs.
An Iterative Approach based on Explainability to Improve the Learning of Fraud Detection Models
Sep 28, 2020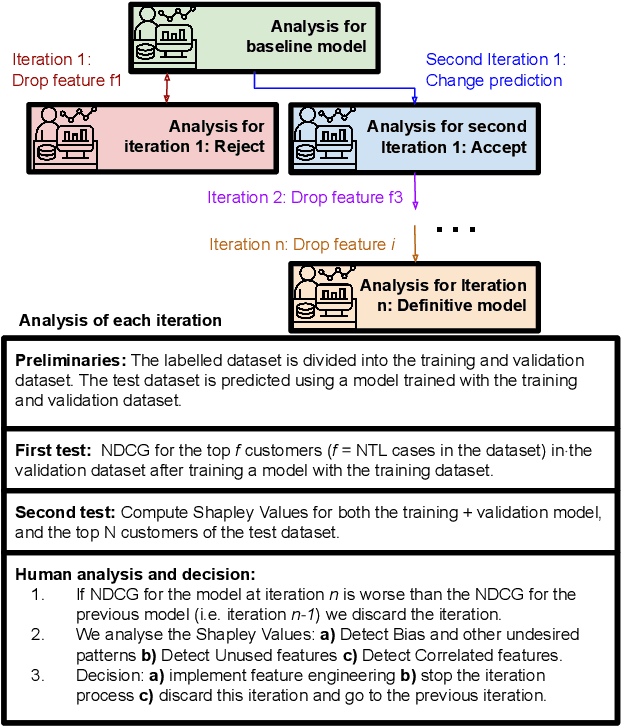
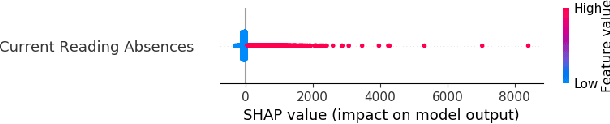
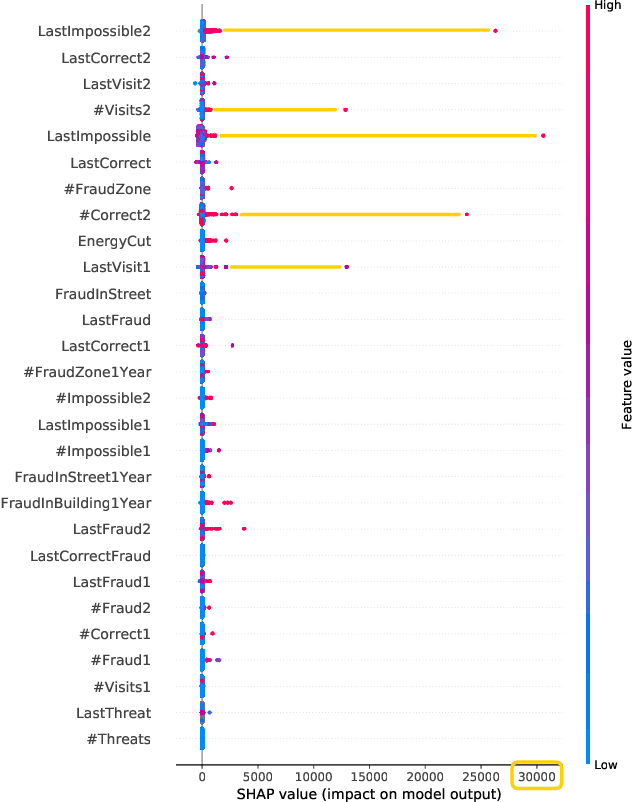
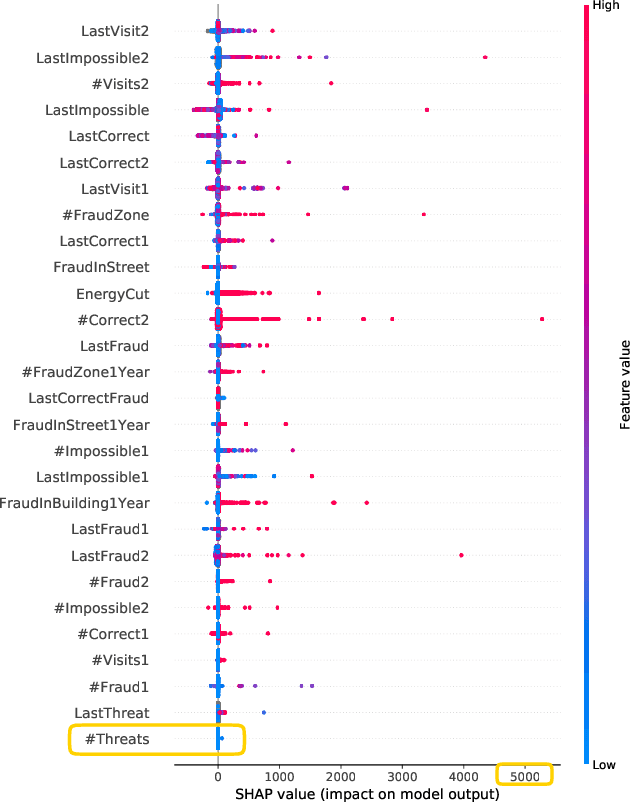
Implementing predictive models in utility companies to detect Non-Technical Losses (i.e. fraud and other meter problems) is challenging: the data available is biased, and the algorithms usually used are black-boxes that can not be either easily trusted or understood by the stakeholders. In this work, we explain our approach to mitigate these problems in a real supervised system to detect non-technical losses for an international utility company from Spain. This approach exploits human knowledge (e.g. from the data scientists or the company's stakeholders), and the information provided by explanatory methods to implement smart feature engineering. This simple, efficient method that can be easily implemented in other industrial projects is tested in a real dataset and the results evidence that the derived prediction model is better in terms of accuracy, interpretability, robustness and flexibility.
Explainable Predictive Process Monitoring
Sep 16, 2020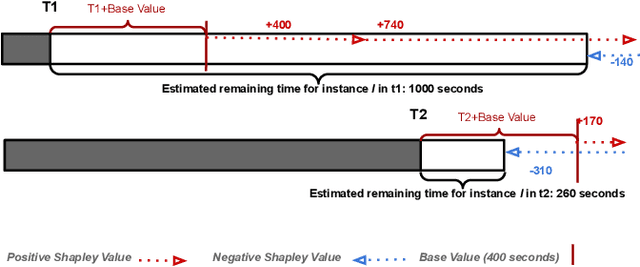
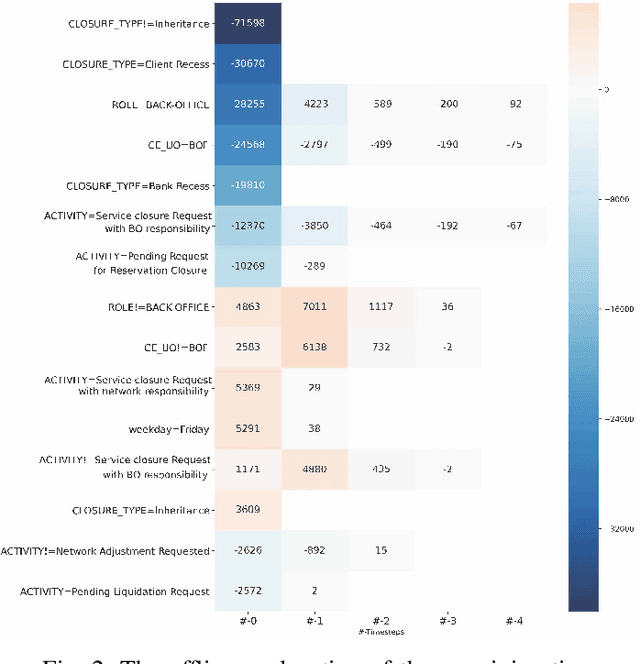
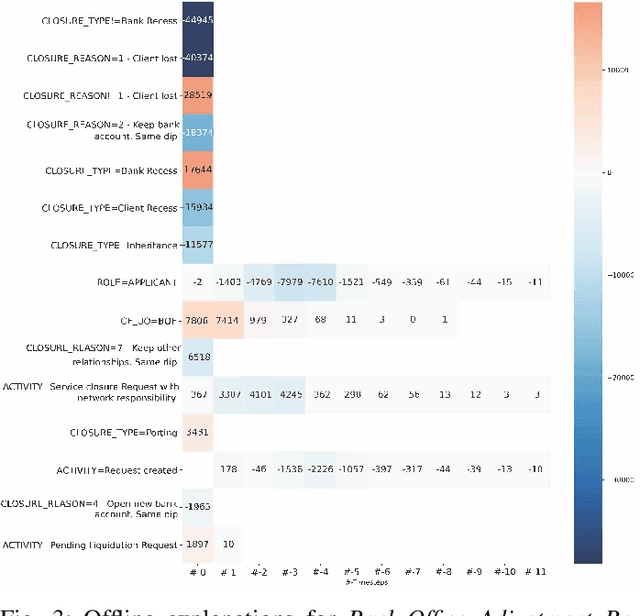
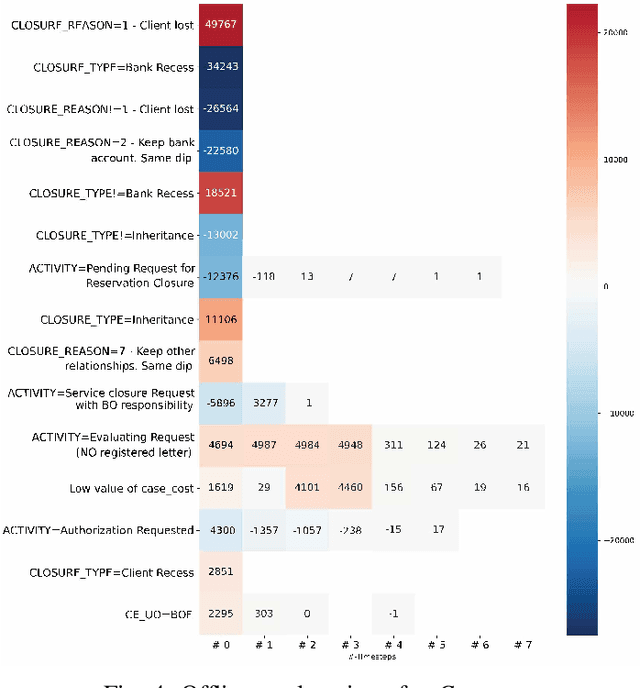
Predictive Business Process Monitoring is becoming an essential aid for organizations, providing online operational support of their processes. This paper tackles the fundamental problem of equipping predictive business process monitoring with explanation capabilities, so that not only the what but also the why is reported when predicting generic KPIs like remaining time, or activity execution. We use the game theory of Shapley Values to obtain robust explanations of the predictions. The approach has been implemented and tested on real-life benchmarks, showing for the first time how explanations can be given in the field of predictive business process monitoring.
Business Process Variant Analysis based on Mutual Fingerprints of Event Logs
Dec 23, 2019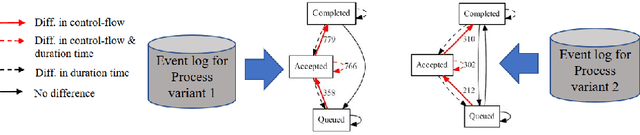
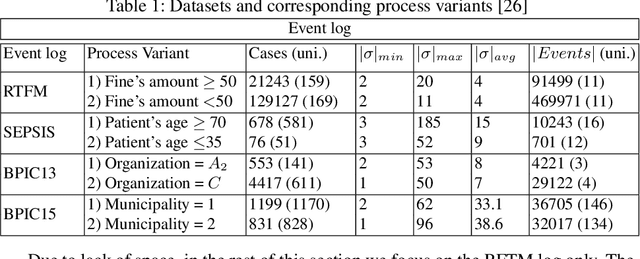
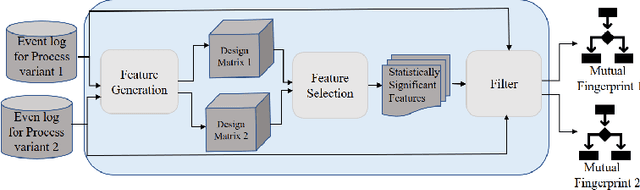

Comparing business process variants using event logs is a common use case in process mining. Existing techniques for process variant analysis detect statistically-significant differences between variants at the level of individual entities (such as process activities) and their relationships (e.g. directly-follows relations between activities). This may lead to a proliferation of differences due to the low level of granularity in which such differences are captured. This paper presents a novel approach to detect statistically-significant differences between variants at the level of entire process traces (i.e. sequences of directly-follows relations). The cornerstone of this approach is a technique to learn a directly follows graph called mutual fingerprint from the event logs of the two variants. A mutual fingerprint is a lossless encoding of a set of traces and their duration using discrete wavelet transformation. This structure facilitates the understanding of statistical differences along the control-flow and performance dimensions. The approach has been evaluated using real-life event logs against two baselines. The results show that at a trace level, the baselines cannot always reveal the differences discovered by our approach, or can detect spurious differences.
Anti-Alignments -- Measuring The Precision of Process Models and Event Logs
Nov 28, 2019



Processes are a crucial artefact in organizations, since they coordinate the execution of activities so that products and services are provided. The use of models to analyse the underlying processes is a well-known practice. However, due to the complexity and continuous evolution of their processes, organizations need an effective way of analysing the relation between processes and models. Conformance checking techniques asses the suitability of a process model in representing an underlying process, observed through a collection of real executions. One important metric in conformance checking is to asses the precision of the model with respect to the observed executions, i.e., characterize the ability of the model to produce behavior unrelated to the one observed. In this paper we present the notion of anti-alignment as a concept to help unveiling runs in the model that may deviate significantly from the observed behavior. Using anti-alignments, a new metric for precision is proposed. In contrast to existing metrics, anti-alignment based precision metrics satisfy most of the required axioms highlighted in a recent publication. Moreover, a complexity analysis of the problem of computing anti-alignments is provided, which sheds light into the practicability of using anti-alignment to estimate precision. Experiments are provided that witness the validity of the concepts introduced in this paper.