 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iterative Approach based on Explainability to Improve the Learning of Fraud Detection Models
Sep 28, 2020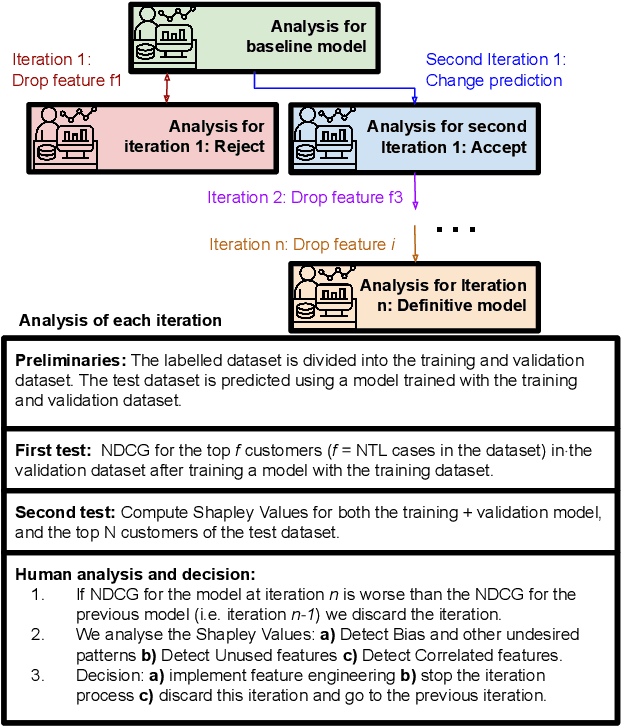
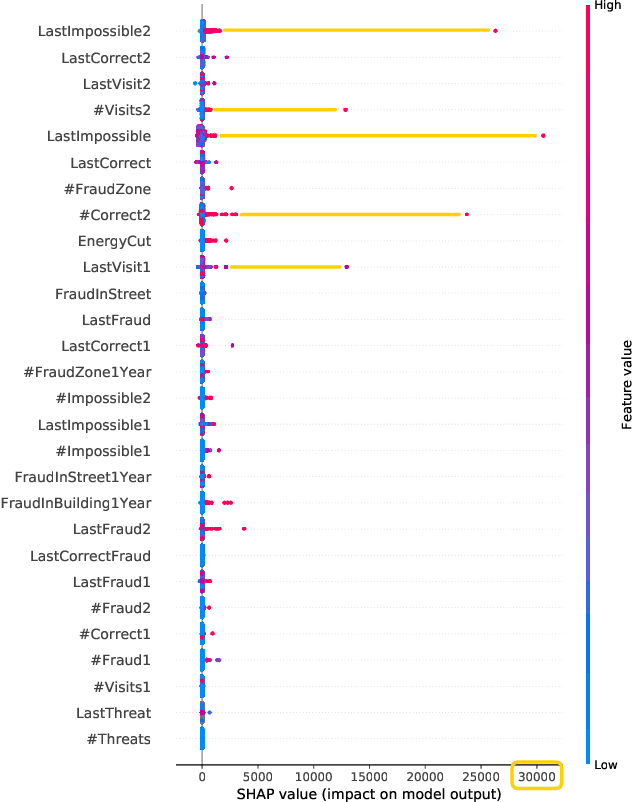
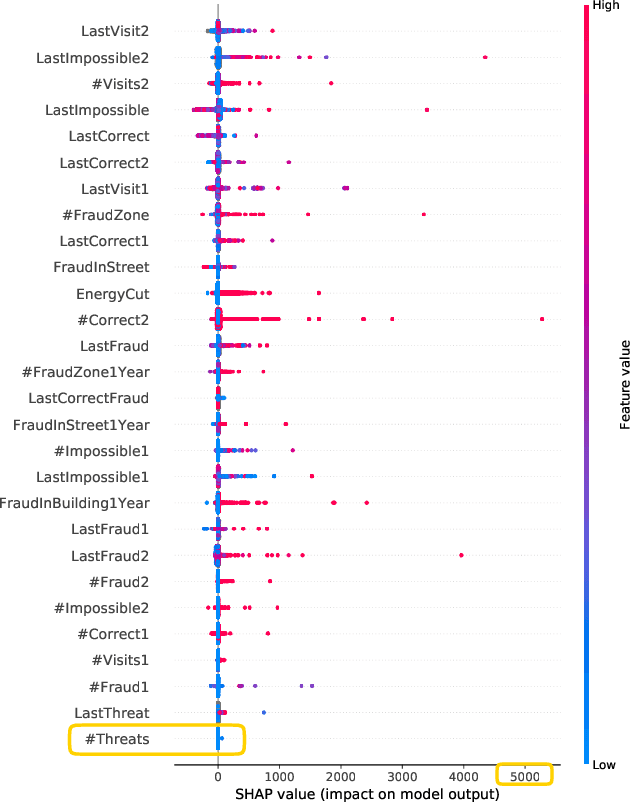
Implementing predictive models in utility companies to detect Non-Technical Losses (i.e. fraud and other meter problems) is challenging: the data available is biased, and the algorithms usually used are black-boxes that can not be either easily trusted or understood by the stakeholders. In this work, we explain our approach to mitigate these problems in a real supervised system to detect non-technical losses for an international utility company from Spain. This approach exploits human knowledge (e.g. from the data scientists or the company's stakeholders), and the information provided by explanatory methods to implement smart feature engineering. This simple, efficient method that can be easily implemented in other industrial projects is tested in a real dataset and the results evidence that the derived prediction model is better in terms of accuracy, interpretability, robustness and flexibility.
Explainable Predictive Process Monitoring
Sep 16, 2020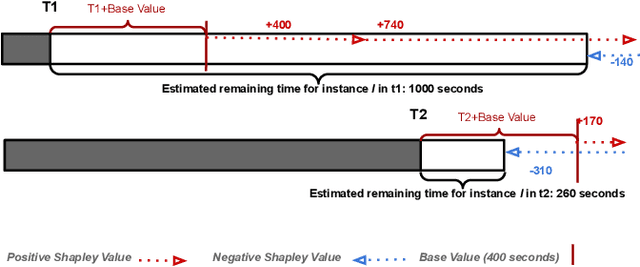
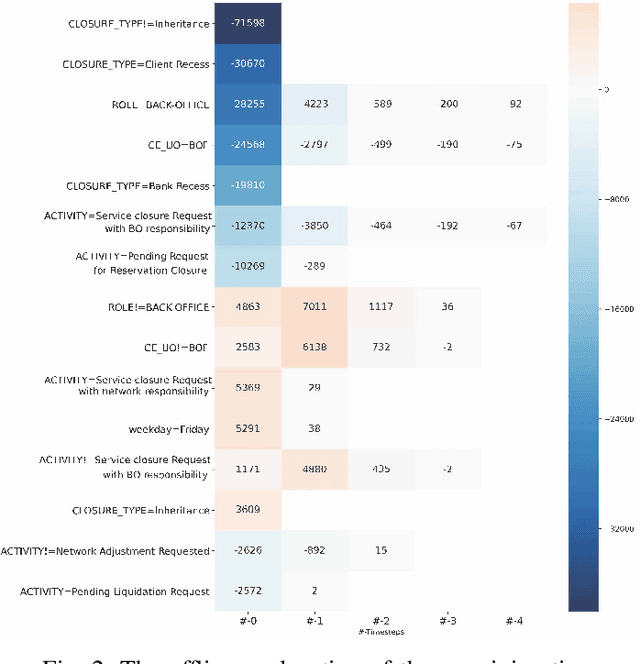
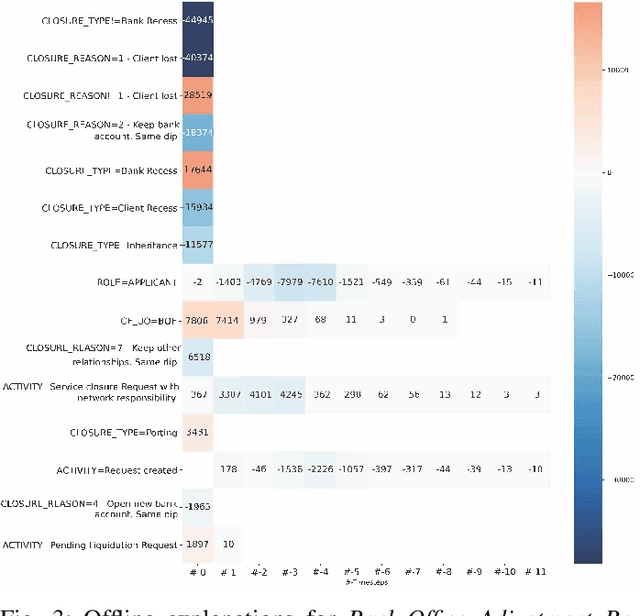
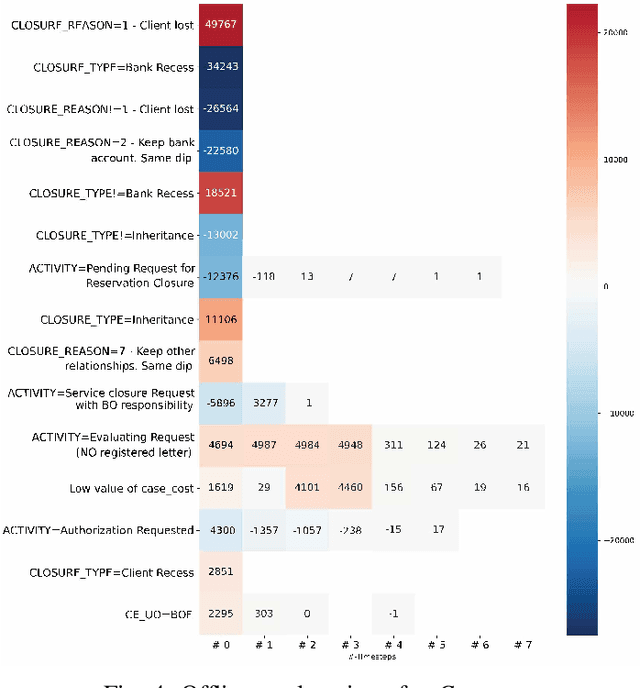
Predictive Business Process Monitoring is becoming an essential aid for organizations, providing online operational support of their processes. This paper tackles the fundamental problem of equipping predictive business process monitoring with explanation capabilities, so that not only the what but also the why is reported when predicting generic KPIs like remaining time, or activity execution. We use the game theory of Shapley Values to obtain robust explanations of the predictions. The approach has been implemented and tested on real-life benchmarks, showing for the first time how explanations can be given in the field of predictive business process monitoring.
Collaborative Filtering Ensemble for Personalized Name Recommendation
Jul 16, 2014

Out of thousands of names to choose from, picking the right one for your child is a daunting task. In this work, our objective is to help parents making an informed decision while choosing a name for their baby. We follow a recommender system approach and combine, in an ensemble, the individual rankings produced by simple collaborative filtering algorithms in order to produce a personalized list of names that meets the individual parents' taste. Our experiments were conducted using real-world data collected from the query logs of 'nameling' (nameling.net), an online portal for searching and exploring names, which corresponds to the dataset released in the context of the ECML PKDD Discover Challenge 2013. Our approach is intuitive, easy to implement, and features fast training and prediction steps.
* Top-N recommendation; personalized ranking; given name recommendation