 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Active learning with biased non-response to label requests
Dec 13, 2023Active learning can improve the efficiency of training prediction models by identifying the most informative new labels to acquire. However, non-response to label requests can impact active learning's effectiveness in real-world contexts. We conceptualise this degradation by considering the type of non-response present in the data, demonstrating that biased non-response is particularly detrimental to model performance. We argue that this sort of non-response is particularly likely in contexts where the labelling process, by nature, relies on user interactions. To mitigate the impact of biased non-response, we propose a cost-based correction to the sampling strategy--the Upper Confidence Bound of the Expected Utility (UCB-EU)--that can, plausibly, be applied to any active learning algorithm. Through experiments, we demonstrate that our method successfully reduces the harm from labelling non-response in many settings. However, we also characterise settings where the non-response bias in the annotations remains detrimental under UCB-EU for particular sampling methods and data generating processes. Finally, we evaluate our method on a real-world dataset from e-commerce platform Taobao. We show that UCB-EU yields substantial performance improvements to conversion models that are trained on clicked impressions. Most generally, this research serves to both better conceptualise the interplay between types of non-response and model improvements via active learning, and to provide a practical, easy to implement correction that helps mitigate model degradation.
On Biased Random Walks, Corrupted Intervals, and Learning Under Adversarial Design
Mar 30, 2020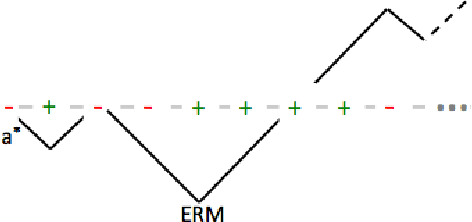
We tackle some fundamental problems in probability theory on corrupted random processes on the integer line. We analyze when a biased random walk is expected to reach its bottommost point and when intervals of integer points can be detected under a natural model of noise. We apply these results to problems in learning thresholds and intervals under a new model for learning under adversarial design.
Guess What's on my Screen? Clustering Smartphone Screenshots with Active Learning
Jan 10, 2019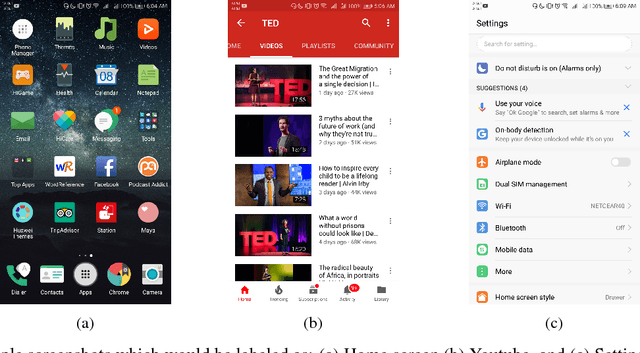
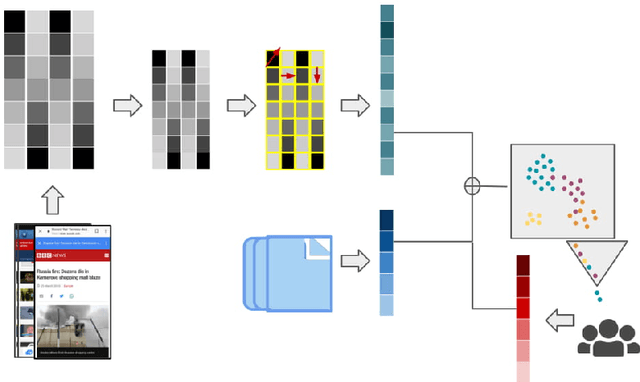
A significant proportion of individuals' daily activities is experienced through digital devices. Smartphones in particular have become one of the preferred interfaces for content consumption and social interaction. Identifying the content embedded in frequently-captured smartphone screenshots is thus a crucial prerequisite to studies of media behavior and health intervention planning that analyze activity interplay and content switching over time. Screenshot images can depict heterogeneous contents and applications, making the a priori definition of adequate taxonomies a cumbersome task, even for humans. Privacy protection of the sensitive data captured on screens means the costs associated with manual annotation are large, as the effort cannot be crowd-sourced. Thus, there is need to examine utility of unsupervised and semi-supervised methods for digital screenshot classification. This work introduces the implications of applying clustering on large screenshot sets when only a limited amount of labels is available. In this paper we develop a framework for combining K-Means clustering with Active Learning for efficient leveraging of labeled and unlabeled samples, with the goal of discovering latent classes and describing a large collection of screenshot data. We tested whether SVM-embedded or XGBoost-embedded solutions for class probability propagation provide for more well-formed cluster configurations. Visual and textual vector representations of the screenshot images are derived and combined to assess the relative contribution of multi-modal features to the overall performance.