 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonality Differences Drive Conversational Dynamics: A High-Dimensional NLP Approach
Oct 14, 2024This paper investigates how the topical flow of dyadic conversations emerges over time and how differences in interlocutors' personality traits contribute to this topical flow. Leveraging text embeddings, we map the trajectories of $N = 1655$ conversations between strangers into a high-dimensional space. Using nonlinear projections and clustering, we then identify when each interlocutor enters and exits various topics. Differences in conversational flow are quantified via $\textit{topic entropy}$, a summary measure of the "spread" of topics covered during a conversation, and $\textit{linguistic alignment}$, a time-varying measure of the cosine similarity between interlocutors' embeddings. Our findings suggest that interlocutors with a larger difference in the personality dimension of openness influence each other to spend more time discussing a wider range of topics and that interlocutors with a larger difference in extraversion experience a larger decrease in linguistic alignment throughout their conversation. We also examine how participants' affect (emotion) changes from before to after a conversation, finding that a larger difference in extraversion predicts a larger difference in affect change and that a greater topic entropy predicts a larger affect increase. This work demonstrates how communication research can be advanced through the use of high-dimensional NLP methods and identifies personality difference as an important driver of social influence.
Guess What's on my Screen? Clustering Smartphone Screenshots with Active Learning
Jan 10, 2019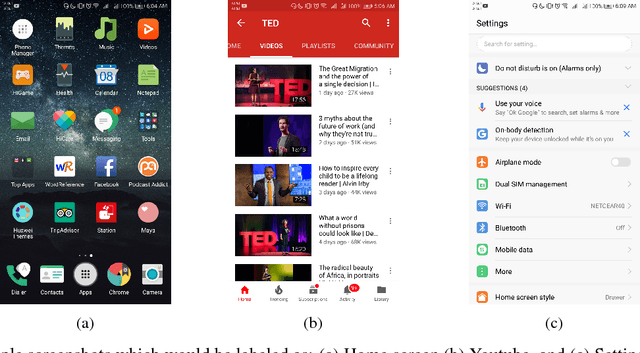
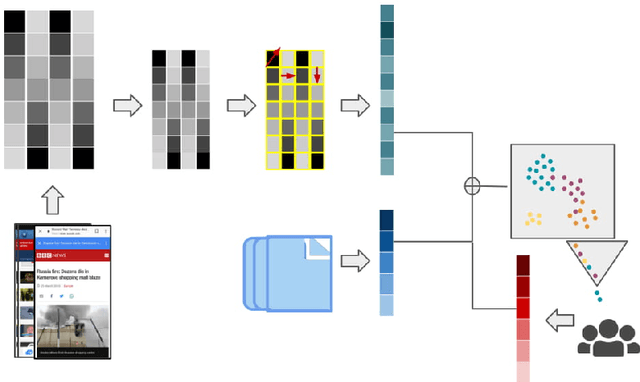
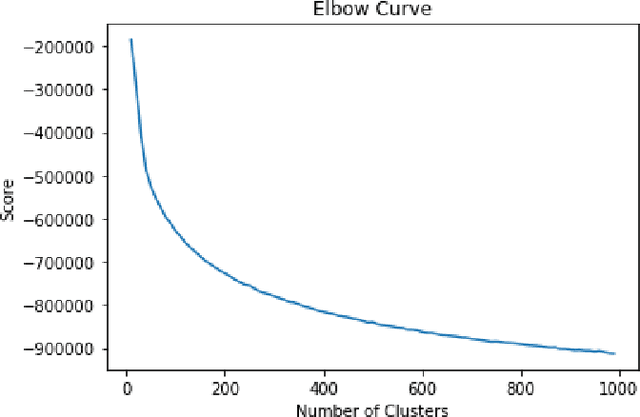
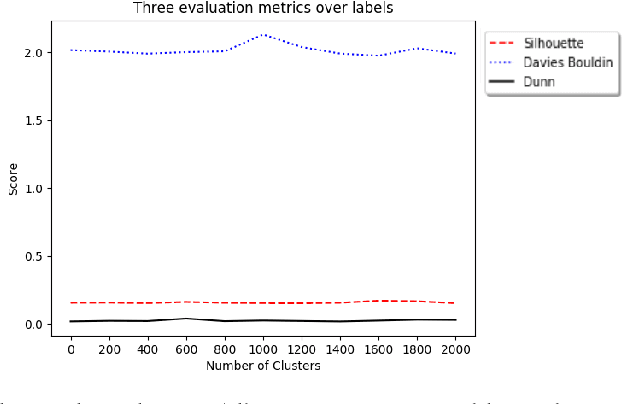
A significant proportion of individuals' daily activities is experienced through digital devices. Smartphones in particular have become one of the preferred interfaces for content consumption and social interaction. Identifying the content embedded in frequently-captured smartphone screenshots is thus a crucial prerequisite to studies of media behavior and health intervention planning that analyze activity interplay and content switching over time. Screenshot images can depict heterogeneous contents and applications, making the a priori definition of adequate taxonomies a cumbersome task, even for humans. Privacy protection of the sensitive data captured on screens means the costs associated with manual annotation are large, as the effort cannot be crowd-sourced. Thus, there is need to examine utility of unsupervised and semi-supervised methods for digital screenshot classification. This work introduces the implications of applying clustering on large screenshot sets when only a limited amount of labels is available. In this paper we develop a framework for combining K-Means clustering with Active Learning for efficient leveraging of labeled and unlabeled samples, with the goal of discovering latent classes and describing a large collection of screenshot data. We tested whether SVM-embedded or XGBoost-embedded solutions for class probability propagation provide for more well-formed cluster configurations. Visual and textual vector representations of the screenshot images are derived and combined to assess the relative contribution of multi-modal features to the overall performance.
Text Extraction and Retrieval from Smartphone Screenshots: Building a Repository for Life in Media
Jan 04, 2018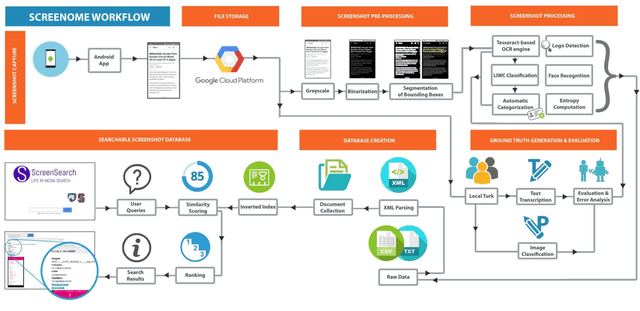
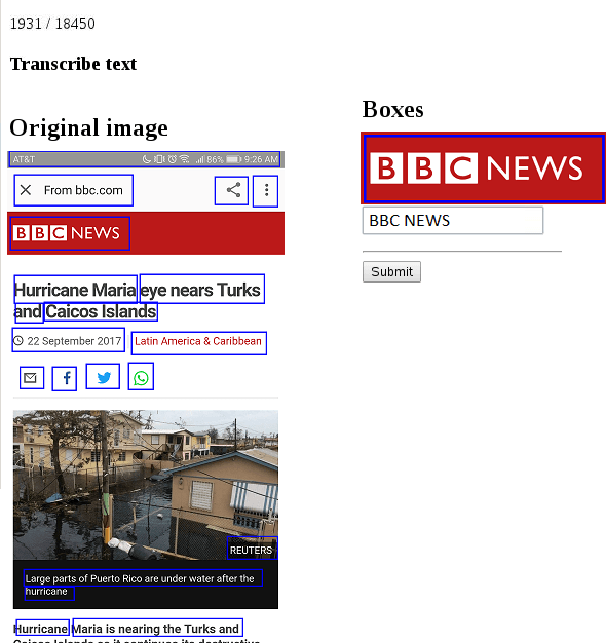
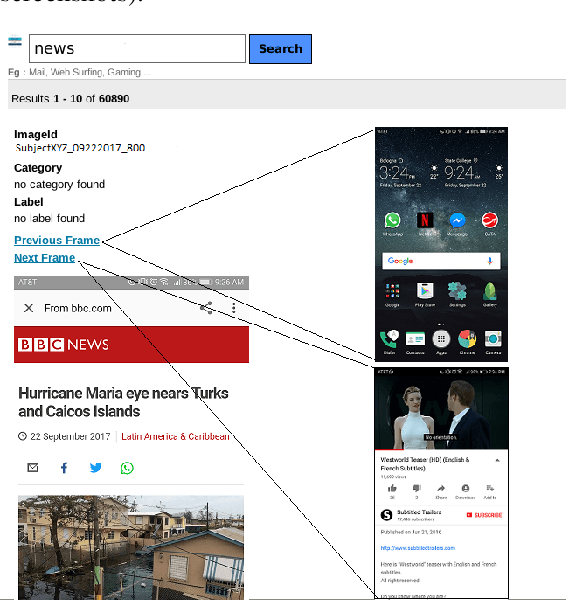
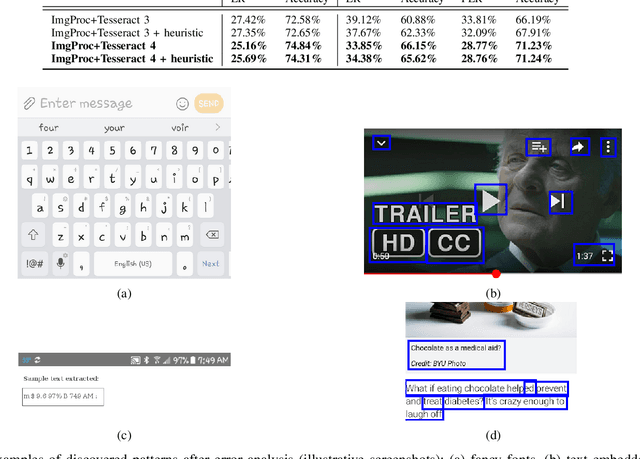
Daily engagement in life experiences is increasingly interwoven with mobile device use. Screen capture at the scale of seconds is being used in behavioral studies and to implement "just-in-time" health interventions. The increasing psychological breadth of digital information will continue to make the actual screens that people view a preferred if not required source of data about life experiences. Effective and efficient Information Extraction and Retrieval from digital screenshots is a crucial prerequisite to successful use of screen data. In this paper, we present the experimental workflow we exploited to: (i) pre-process a unique collection of screen captures, (ii) extract unstructured text embedded in the images, (iii) organize image text and metadata based on a structured schema, (iv) index the resulting document collection, and (v) allow for Image Retrieval through a dedicated vertical search engine application. The adopted procedure integrates different open source libraries for traditional image processing, Optical Character Recognition (OCR), and Image Retrieval. Our aim is to assess whether and how state-of-the-art methodologies can be applied to this novel data set. We show how combining OpenCV-based pre-processing modules with a Long short-term memory (LSTM) based release of Tesseract OCR, without ad hoc training, led to a 74% character-level accuracy of the extracted text. Further, we used the processed repository as baseline for a dedicated Image Retrieval system, for the immediate use and application for behavioral and prevention scientists. We discuss issues of Text Information Extraction and Retrieval that are particular to the screenshot image case and suggest important future work.
On the Ground Validation of Online Diagnosis with Twitter and Medical Records
Apr 11, 2014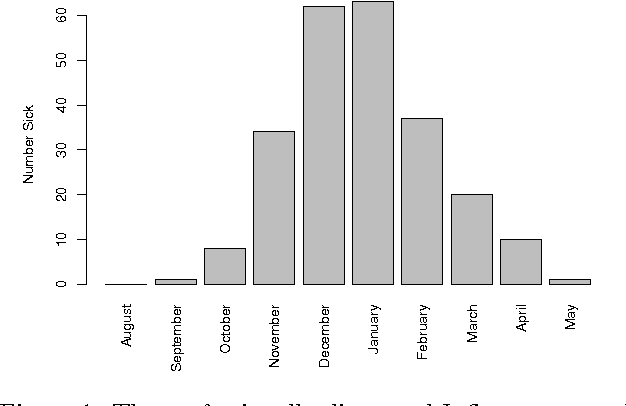
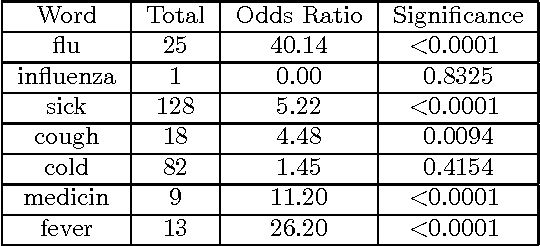


Social media has been considered as a data source for tracking disease. However, most analyses are based on models that prioritize strong correlation with population-level disease rates over determining whether or not specific individual users are actually sick. Taking a different approach, we develop a novel system for social-media based disease detection at the individual level using a sample of professionally diagnosed individuals. Specifically, we develop a system for making an accurate influenza diagnosis based on an individual's publicly available Twitter data. We find that about half (17/35 = 48.57%) of the users in our sample that were sick explicitly discuss their disease on Twitter. By developing a meta classifier that combines text analysis, anomaly detection, and social network analysis, we are able to diagnose an individual with greater than 99% accuracy even if she does not discuss her health.