 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive learning with biased non-response to label requests
Dec 13, 2023Active learning can improve the efficiency of training prediction models by identifying the most informative new labels to acquire. However, non-response to label requests can impact active learning's effectiveness in real-world contexts. We conceptualise this degradation by considering the type of non-response present in the data, demonstrating that biased non-response is particularly detrimental to model performance. We argue that this sort of non-response is particularly likely in contexts where the labelling process, by nature, relies on user interactions. To mitigate the impact of biased non-response, we propose a cost-based correction to the sampling strategy--the Upper Confidence Bound of the Expected Utility (UCB-EU)--that can, plausibly, be applied to any active learning algorithm. Through experiments, we demonstrate that our method successfully reduces the harm from labelling non-response in many settings. However, we also characterise settings where the non-response bias in the annotations remains detrimental under UCB-EU for particular sampling methods and data generating processes. Finally, we evaluate our method on a real-world dataset from e-commerce platform Taobao. We show that UCB-EU yields substantial performance improvements to conversion models that are trained on clicked impressions. Most generally, this research serves to both better conceptualise the interplay between types of non-response and model improvements via active learning, and to provide a practical, easy to implement correction that helps mitigate model degradation.
TCE: A Test-Based Approach to Measuring Calibration Error
Jun 25, 2023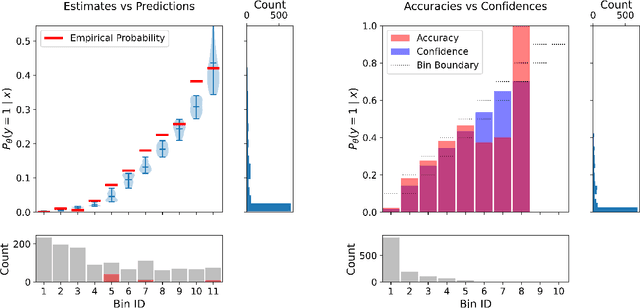

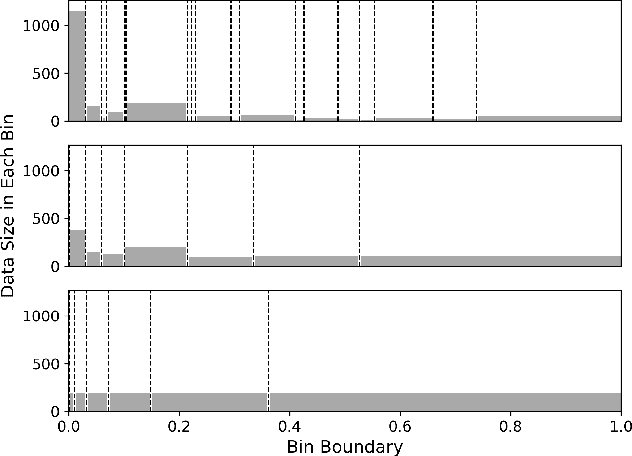
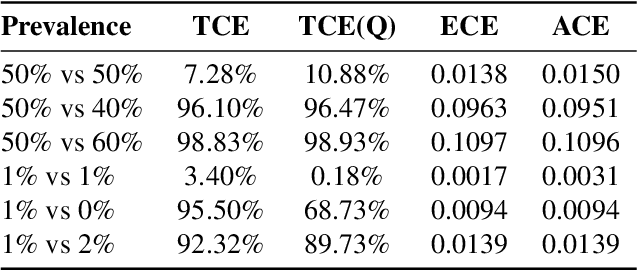
This paper proposes a new metric to measure the calibration error of probabilistic binary classifiers, called test-based calibration error (TCE). TCE incorporates a novel loss function based on a statistical test to examine the extent to which model predictions differ from probabilities estimated from data. It offers (i) a clear interpretation, (ii) a consistent scale that is unaffected by class imbalance, and (iii) an enhanced visual representation with repect to the standard reliability diagram. In addition, we introduce an optimality criterion for the binning procedure of calibration error metrics based on a minimal estimation error of the empirical probabilities. We provide a novel computational algorithm for optimal bins under bin-size constraints. We demonstrate properties of TCE through a range of experiments, including multiple real-world imbalanced datasets and ImageNet 1000.
Explaining Predictive Uncertainty with Information Theoretic Shapley Values
Jun 09, 2023Researchers in explainable artificial intelligence have developed numerous methods for helping users understand the predictions of complex supervised learning models. By contrast, explaining the $\textit{uncertainty}$ of model outputs has received relatively little attention. We adapt the popular Shapley value framework to explain various types of predictive uncertainty, quantifying each feature's contribution to the conditional entropy of individual model outputs. We consider games with modified characteristic functions and find deep connections between the resulting Shapley values and fundamental quantities from information theory and conditional independence testing. We outline inference procedures for finite sample error rate control with provable guarantees, and implement an efficient algorithm that performs well in a range of experiments on real and simulated data. Our method has applications to covariate shift detection, active learning, feature selection, and active feature-value acquisition.