 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Learning via k-DTW: A Novel Dissimilarity Measure for Curves
May 29, 2025This paper introduces $k$-Dynamic Time Warping ($k$-DTW), a novel dissimilarity measure for polygonal curves. $k$-DTW has stronger metric properties than Dynamic Time Warping (DTW) and is more robust to outliers than the Fr\'{e}chet distance, which are the two gold standards of dissimilarity measures for polygonal curves. We show interesting properties of $k$-DTW and give an exact algorithm as well as a $(1+\varepsilon)$-approximation algorithm for $k$-DTW by a parametric search for the $k$-th largest matched distance. We prove the first dimension-free learning bounds for curves and further learning theoretic results. $k$-DTW not only admits smaller sample size than DTW for the problem of learning the median of curves, where some factors depending on the curves' complexity $m$ are replaced by $k$, but we also show a surprising separation on the associated Rademacher and Gaussian complexities: $k$-DTW admits strictly smaller bounds than DTW, by a factor $\tilde\Omega(\sqrt{m})$ when $k\ll m$. We complement our theoretical findings with an experimental illustration of the benefits of using $k$-DTW for clustering and nearest neighbor classification.
Scalable Learning of Item Response Theory Models
Mar 01, 2024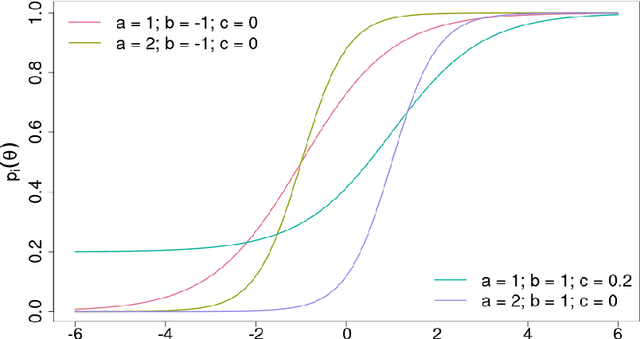

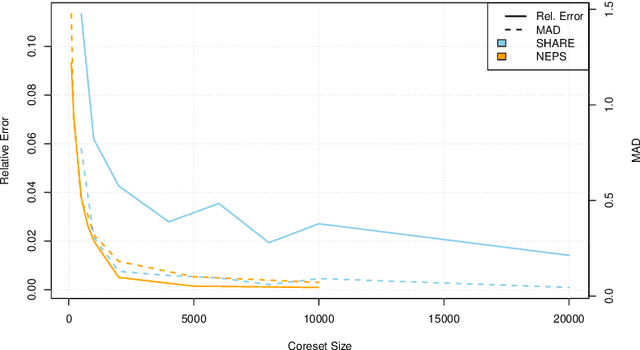
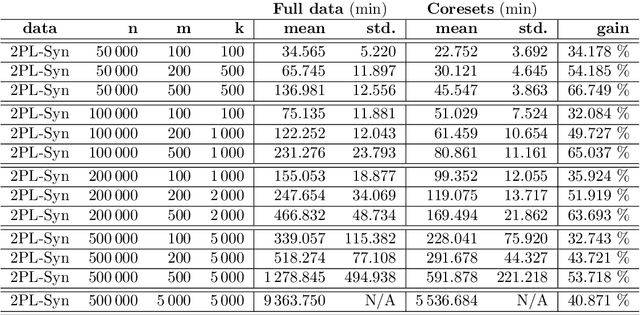
Item Response Theory (IRT) models aim to assess latent abilities of $n$ examinees along with latent difficulty characteristics of $m$ test items from categorical data that indicates the quality of their corresponding answers. Classical psychometric assessments are based on a relatively small number of examinees and items, say a class of $200$ students solving an exam comprising $10$ problems. More recent global large scale assessments such as PISA, or internet studies, may lead to significantly increased numbers of participants. Additionally, in the context of Machine Learning where algorithms take the role of examinees and data analysis problems take the role of items, both $n$ and $m$ may become very large, challenging the efficiency and scalability of computations. To learn the latent variables in IRT models from large data, we leverage the similarity of these models to logistic regression, which can be approximated accurately using small weighted subsets called coresets. We develop coresets for their use in alternating IRT training algorithms, facilitating scalable learning from large data.
Probabilistic smallest enclosing ball in high dimensions via subgradient sampling
Feb 28, 2019We study a variant of the median problem for a collection of point sets in high dimensions. This generalizes the geometric median as well as the (probabilistic) smallest enclosing ball (pSEB) problems. Our main objective and motivation is to improve the previously best algorithm for the pSEB problem by reducing its exponential dependence on the dimension to linear. This is achieved via a novel combination of sampling techniques for clustering problems in metric spaces with the framework of stochastic subgradient descent. As a result, the algorithm becomes applicable to shape fitting problems in Hilbert spaces of unbounded dimension via kernel functions. We present an exemplary application by extending the support vector data description (SVDD) shape fitting method to the probabilistic case. This is done by simulating the pSEB algorithm implicitly in the feature space induced by the kernel function.