 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPD-fVAE: Synthetic Data Generation Using Federated Variational Autoencoders With Differentially-Private Decoder
Nov 21, 2022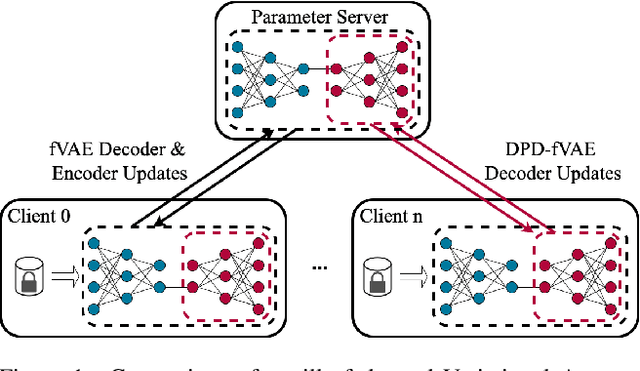

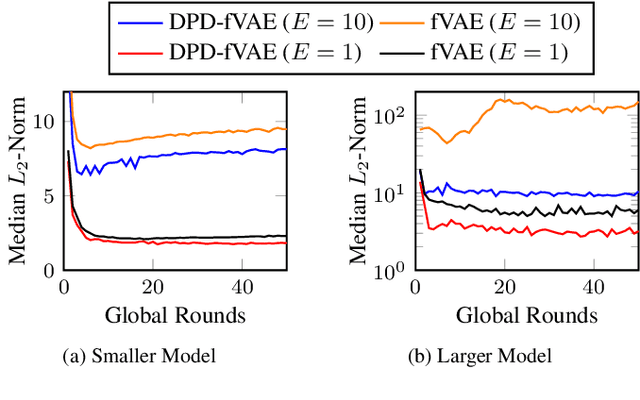
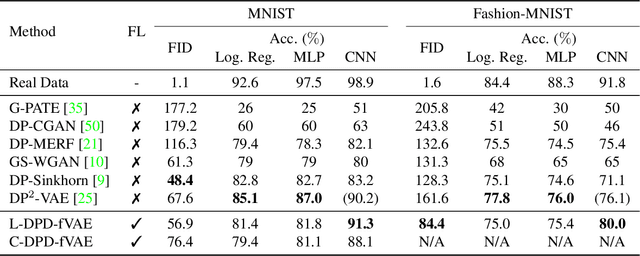
Federated learning (FL) is getting increased attention for processing sensitive, distributed datasets common to domains such as healthcare. Instead of directly training classification models on these datasets, recent works have considered training data generators capable of synthesising a new dataset which is not protected by any privacy restrictions. Thus, the synthetic data can be made available to anyone, which enables further evaluation of machine learning architectures and research questions off-site. As an additional layer of privacy-preservation, differential privacy can be introduced into the training process. We propose DPD-fVAE, a federated Variational Autoencoder with Differentially-Private Decoder, to synthesise a new, labelled dataset for subsequent machine learning tasks. By synchronising only the decoder component with FL, we can reduce the privacy cost per epoch and thus enable better data generators. In our evaluation on MNIST, Fashion-MNIST and CelebA, we show the benefits of DPD-fVAE and report competitive performance to related work in terms of Fr\'echet Inception Distance and accuracy of classifiers trained on the synthesised dataset.
Defending against Reconstruction Attacks through Differentially Private Federated Learning for Classification of Heterogeneous Chest X-Ray Data
May 06, 2022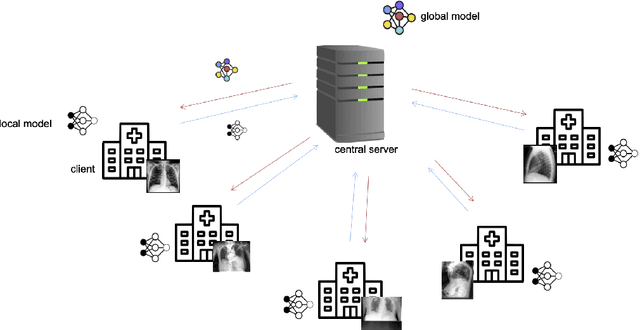
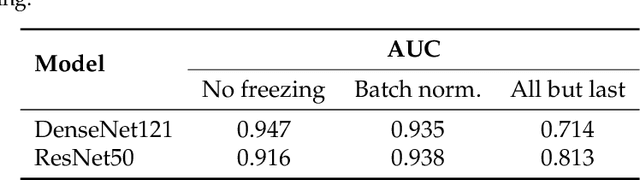
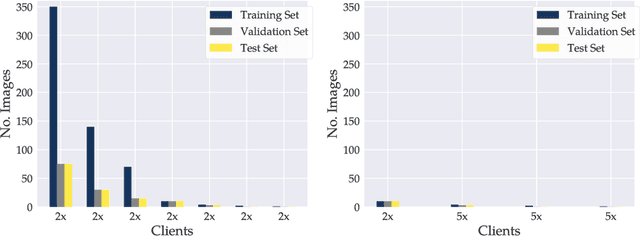
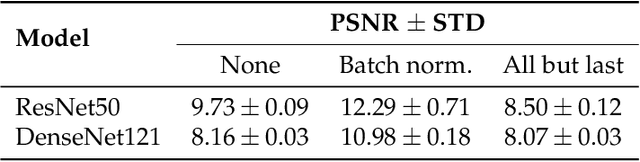
Privacy regulations and the physical distribution of heterogeneous data are often primary concerns for the development of deep learning models in a medical context. This paper evaluates the feasibility of differentially private federated learning for chest X-ray classification as a defense against privacy attacks on DenseNet121 and ResNet50 network architectures. We simulated a federated environment by distributing images from the public CheXpert and Mendeley chest X-ray datasets unevenly among 36 clients. Both non-private baseline models achieved an area under the ROC curve (AUC) of 0.94 on the binary classification task of detecting the presence of a medical finding. We demonstrate that both model architectures are vulnerable to privacy violation by applying image reconstruction attacks to local model updates from individual clients. The attack was particularly successful during later training stages. To mitigate the risk of privacy breach, we integrated R\'enyi differential privacy with a Gaussian noise mechanism into local model training. We evaluate model performance and attack vulnerability for privacy budgets $\epsilon \in$ {1, 3, 6, 10}. The DenseNet121 achieved the best utility-privacy trade-off with an AUC of 0.94 for $\epsilon$ = 6. Model performance deteriorated slightly for individual clients compared to the non-private baseline. The ResNet50 only reached an AUC of 0.76 in the same privacy setting. Its performance was inferior to that of the DenseNet121 for all considered privacy constraints, suggesting that the DenseNet121 architecture is more robust to differentially private training.
Implicit Model Specialization through DAG-based Decentralized Federated Learning
Nov 03, 2021
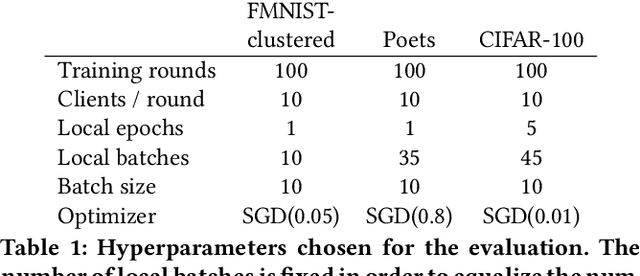
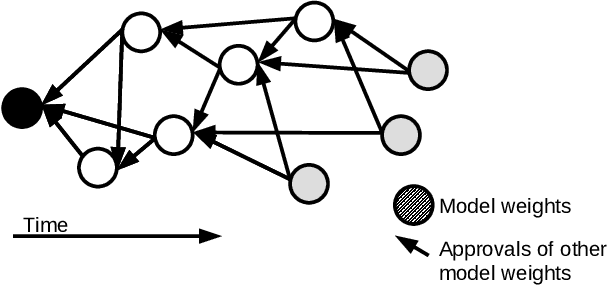

Federated learning allows a group of distributed clients to train a common machine learning model on private data. The exchange of model updates is managed either by a central entity or in a decentralized way, e.g. by a blockchain. However, the strong generalization across all clients makes these approaches unsuited for non-independent and identically distributed (non-IID) data. We propose a unified approach to decentralization and personalization in federated learning that is based on a directed acyclic graph (DAG) of model updates. Instead of training a single global model, clients specialize on their local data while using the model updates from other clients dependent on the similarity of their respective data. This specialization implicitly emerges from the DAG-based communication and selection of model updates. Thus, we enable the evolution of specialized models, which focus on a subset of the data and therefore cover non-IID data better than federated learning in a centralized or blockchain-based setup. To the best of our knowledge, the proposed solution is the first to unite personalization and poisoning robustness in fully decentralized federated learning. Our evaluation shows that the specialization of models emerges directly from the DAG-based communication of model updates on three different datasets. Furthermore, we show stable model accuracy and less variance across clients when compared to federated averaging.
Poisoning Attacks with Generative Adversarial Nets
Jun 18, 2019
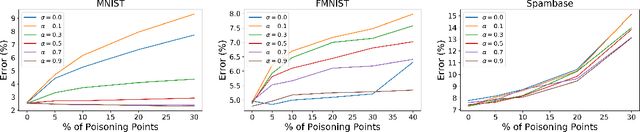


Machine learning algorithms are vulnerable to poisoning attacks: An adversary can inject malicious points in the training dataset to influence the learning process and degrade its performance. Optimal poisoning attacks have already been proposed to evaluate worst-case scenarios, modelling attacks as a bi-level optimisation problem. Solving these problems is computationally demanding and has limited applicability for some models such as deep networks. In this paper we introduce a novel generative model to craft systematic poisoning attacks against machine learning classifiers generating adversarial training examples, i.e. samples that look like genuine data points but that degrade the classifier's accuracy when used for training. We propose a Generative Adversarial Net with three components: generator, discriminator, and the target classifier. This approach allows us to model naturally the detectability constrains that can be expected in realistic attacks and to identify the regions of the underlying data distribution that can be more vulnerable to data poisoning. Our experimental evaluation shows the effectiveness of our attack to compromise machine learning classifiers, including deep networks.