 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Noise Adversarial Examples for Black-Box Attacks on Deep Neural Networks
Paper and Code

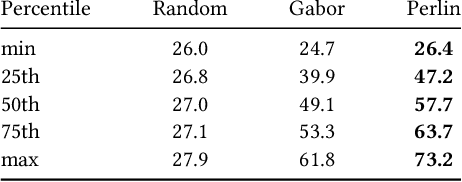

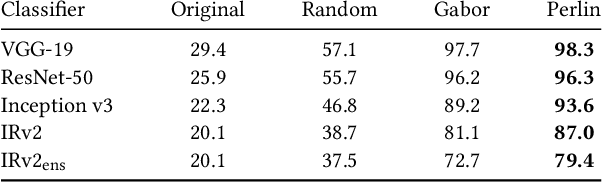
Deep neural networks have been shown to be vulnerable to adversarial examples, perturbed inputs that are designed specifically to produce intentional errors in the learning algorithms. However, existing attacks are either computationally expensive or require extensive knowledge of the target model and its dataset to succeed. Hence, these methods are not practical in a deployed adversarial setting. In this paper we introduce an exploratory approach for generating adversarial examples using procedural noise. We show that it is possible to construct practical black-box attacks with low computational cost against robust neural network architectures such as Inception v3 and Inception ResNet v2 on the ImageNet dataset. We show that these attacks successfully cause misclassification with a low number of queries, significantly outperforming state-of-the-art black box attacks. Our attack demonstrates the fragility of these neural networks to Perlin noise, a type of procedural noise used for generating realistic textures. Perlin noise attacks achieve at least 90% top 1 error across all classifiers. More worryingly, we show that most Perlin noise perturbations are "universal" in that they generalize, as adversarial examples, across large portions of the dataset, with up to 73% of images misclassified using a single perturbation. These findings suggest a systemic fragility of DNNs that needs to be explored further. We also show the limitations of adversarial training, a technique used to enhance the robustness against adversarial examples. Thus, the attacker just needs to change the perspective to generate the adversarial examples to craft successful attacks and, for the defender, it is difficult to foresee a priori all possible types of adversarial perturbations.