 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Dementia Detection in Spoken Language
Jun 26, 2022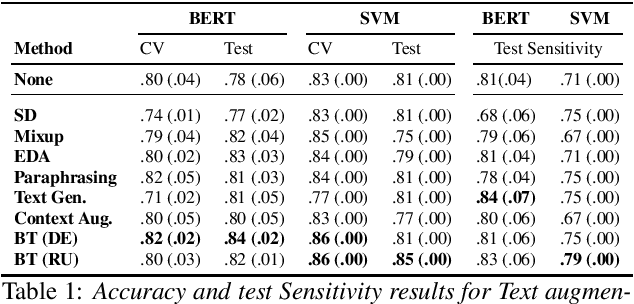
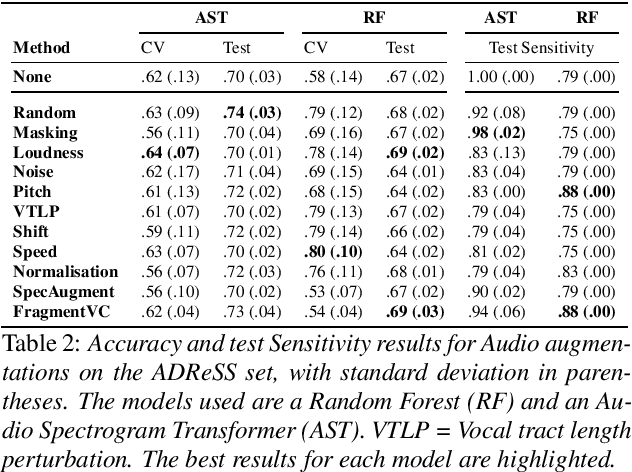

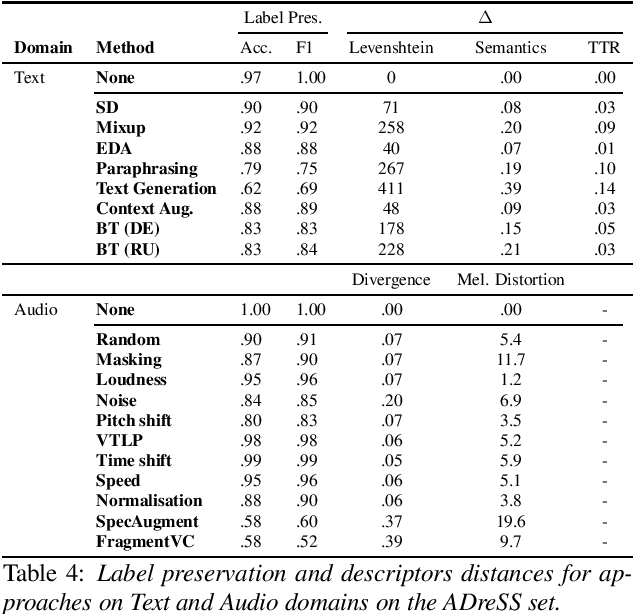
Dementia is a growing problem as our society ages, and detection methods are often invasive and expensive. Recent deep-learning techniques can offer a faster diagnosis and have shown promising results. However, they require large amounts of labelled data which is not easily available for the task of dementia detection. One effective solution to sparse data problems is data augmentation, though the exact methods need to be selected carefully. To date, there has been no empirical study of data augmentation on Alzheimer's disease (AD) datasets for NLP and speech processing. In this work, we investigate data augmentation techniques for the task of AD detection and perform an empirical evaluation of the different approaches on two kinds of models for both the text and audio domains. We use a transformer-based model for both domains, and SVM and Random Forest models for the text and audio domains, respectively. We generate additional samples using traditional as well as deep learning based methods and show that data augmentation improves performance for both the text- and audio-based models and that such results are comparable to state-of-the-art results on the popular ADReSS set, with carefully crafted architectures and features.