 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsody-Driven Privacy-Preserving Dementia Detection
Paper and Code
Jul 03, 2024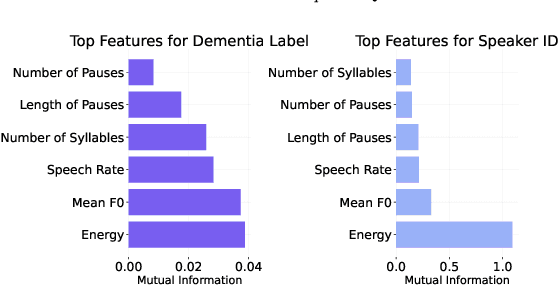
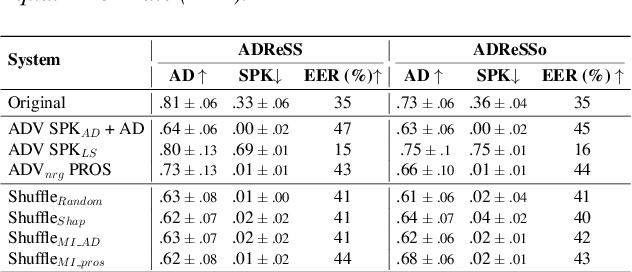
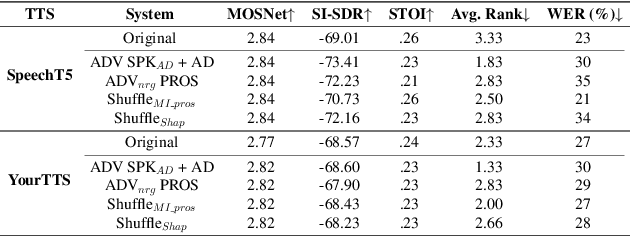
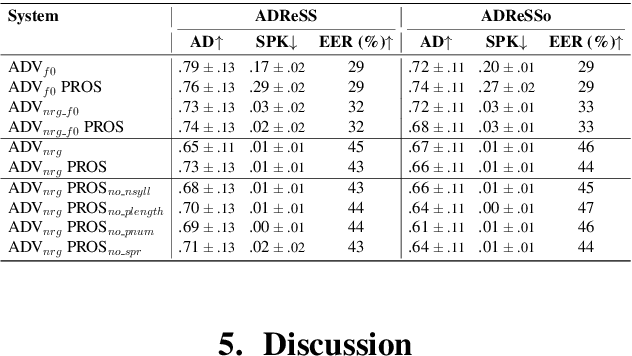
Speaker embeddings extracted from voice recordings have been proven valuable for dementia detection. However, by their nature, these embeddings contain identifiable information which raises privacy concerns. In this work, we aim to anonymize embeddings while preserving the diagnostic utility for dementia detection. Previous studies rely on adversarial learning and models trained on the target attribute and struggle in limited-resource settings. We propose a novel approach that leverages domain knowledge to disentangle prosody features relevant to dementia from speaker embeddings without relying on a dementia classifier. Our experiments show the effectiveness of our approach in preserving speaker privacy (speaker recognition F1-score .01%) while maintaining high dementia detection score F1-score of 74% on the ADReSS dataset. Our results are also on par with a more constrained classifier-dependent system on ADReSSo (.01% and .66%), and have no impact on synthesized speech naturalness.