 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParalinguistic Privacy Protection at the Edge
Paper and Code
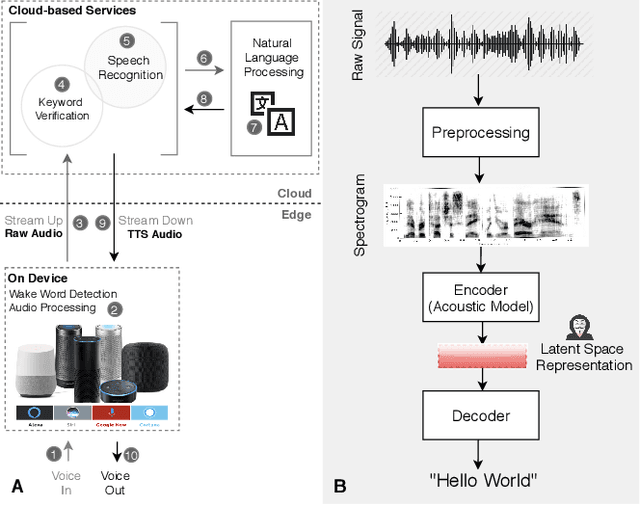
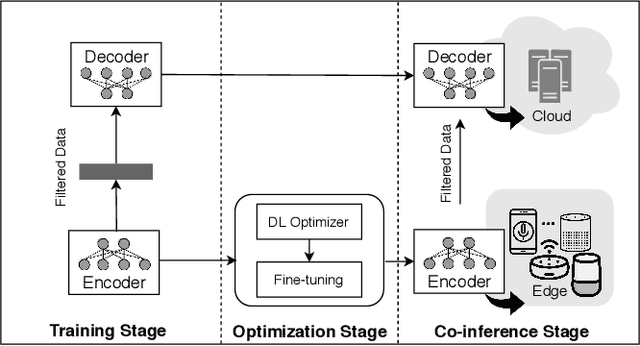
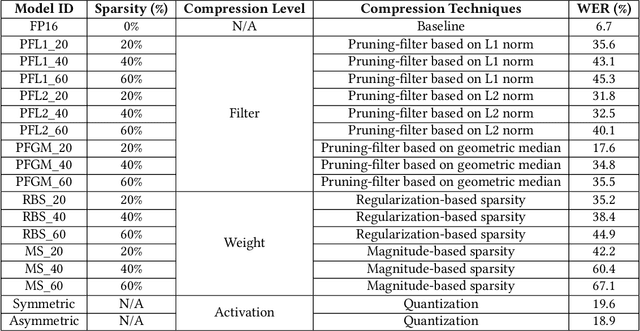
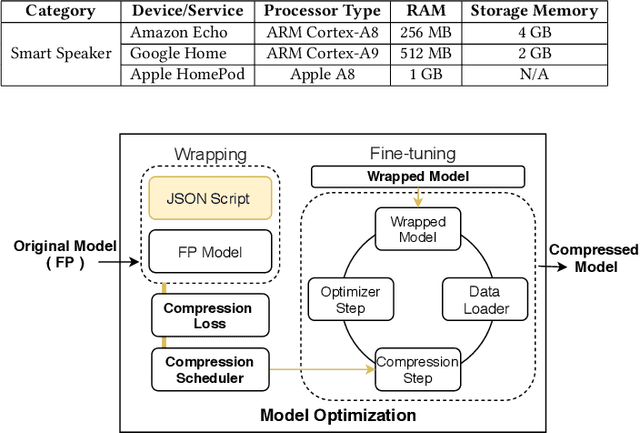
Voice user interfaces and digital assistants are rapidly entering our homes and becoming integrated with all our devices. These always-on services capture and transmit our audio data to powerful cloud services for further processing and subsequent actions. Our voices and raw audio signals collected through these devices contain a host of sensitive paralinguistic information that is transmitted to service providers regardless of deliberate or false triggers. As sensitive attributes like our identity, gender, indicators of mental health status, alongside moods, emotions and their temporal patterns, are easily inferred using deep acoustic models, we encounter a new generation of privacy risks by using these services. One approach to mitigate the risk of paralinguistic-based privacy breaches is to exploit a combination of cloud-based processing with privacy-preserving on-device paralinguistic information filtering prior to transmitting voice data. In this paper we introduce EDGY, a new lightweight disentangled representation learning model that transforms and filters high-dimensional voice data to remove sensitive attributes at the edge prior to offloading to the cloud. We evaluate EDGY's on-device performance, and explore optimization techniques, including model pruning and quantization, to enable private, accurate and efficient representation learning on resource-constrained devices. Our experimental results show that EDGY runs in tens of milliseconds with minimal performance penalties or accuracy losses in speech recognition using only a CPU and a single core ARM device without specialized hardware.