 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization in LLM Problem Solving: The Case of the Shortest Path
Apr 16, 2026Whether language models can systematically generalize remains actively debated. Yet empirical performance is jointly shaped by multiple factors such as training data, training paradigms, and inference-time strategies, making failures difficult to interpret. We introduce a controlled synthetic environment based on shortest-path planning, a canonical composable sequential optimization problem. The setup enables clean separation of these factors and supports two orthogonal axes of generalization: spatial transfer to unseen maps and length scaling to longer-horizon problems. We find that models exhibit strong spatial transfer but consistently fail under length scaling due to recursive instability. We further analyze how distinct stages of the learning pipeline influence systematic problem-solving: for example, data coverage sets capability limits; reinforcement learning improves training stability but does not expand those limits; and inference-time scaling enhances performance but cannot rescue length-scaling failures.
Cram Less to Fit More: Training Data Pruning Improves Memorization of Facts
Apr 09, 2026Large language models (LLMs) can struggle to memorize factual knowledge in their parameters, often leading to hallucinations and poor performance on knowledge-intensive tasks. In this paper, we formalize fact memorization from an information-theoretic perspective and study how training data distributions affect fact accuracy. We show that fact accuracy is suboptimal (below the capacity limit) whenever the amount of information contained in the training data facts exceeds model capacity. This is further exacerbated when the fact frequency distribution is skewed (e.g. a power law). We propose data selection schemes based on the training loss alone that aim to limit the number of facts in the training data and flatten their frequency distribution. On semi-synthetic datasets containing high-entropy facts, our selection method effectively boosts fact accuracy to the capacity limit. When pretraining language models from scratch on an annotated Wikipedia corpus, our selection method enables a GPT2-Small model (110m parameters) to memorize 1.3X more entity facts compared to standard training, matching the performance of a 10X larger model (1.3B parameters) pretrained on the full dataset.
Optimal Splitting of Language Models from Mixtures to Specialized Domains
Mar 19, 2026Language models achieve impressive performance on a variety of knowledge, language, and reasoning tasks due to the scale and diversity of pretraining data available. The standard training recipe is a two-stage paradigm: pretraining first on the full corpus of data followed by specialization on a subset of high quality, specialized data from the full corpus. In the multi-domain setting, this involves continued pretraining of multiple models on each specialized domain, referred to as split model training. We propose a method for pretraining multiple models independently over a general pretraining corpus, and determining the optimal compute allocation between pretraining and continued pretraining using scaling laws. Our approach accurately predicts the loss of a model of size N with D pretraining and D' specialization tokens, and extrapolates to larger model sizes and number of tokens. Applied to language model training, our approach improves performance consistently across common sense knowledge and reasoning benchmarks across different model sizes and compute budgets.
Instance-Optimality for Private KL Distribution Estimation
May 29, 2025We study the fundamental problem of estimating an unknown discrete distribution $p$ over $d$ symbols, given $n$ i.i.d. samples from the distribution. We are interested in minimizing the KL divergence between the true distribution and the algorithm's estimate. We first construct minimax optimal private estimators. Minimax optimality however fails to shed light on an algorithm's performance on individual (non-worst-case) instances $p$ and simple minimax-optimal DP estimators can have poor empirical performance on real distributions. We then study this problem from an instance-optimality viewpoint, where the algorithm's error on $p$ is compared to the minimum achievable estimation error over a small local neighborhood of $p$. Under natural notions of local neighborhood, we propose algorithms that achieve instance-optimality up to constant factors, with and without a differential privacy constraint. Our upper bounds rely on (private) variants of the Good-Turing estimator. Our lower bounds use additive local neighborhoods that more precisely captures the hardness of distribution estimation in KL divergence, compared to ones considered in prior works.
Unified Enhancement of Privacy Bounds for Mixture Mechanisms via $f$-Differential Privacy
Nov 01, 2023Differentially private (DP) machine learning algorithms incur many sources of randomness, such as random initialization, random batch subsampling, and shuffling. However, such randomness is difficult to take into account when proving differential privacy bounds because it induces mixture distributions for the algorithm's output that are difficult to analyze. This paper focuses on improving privacy bounds for shuffling models and one-iteration differentially private gradient descent (DP-GD) with random initializations using $f$-DP. We derive a closed-form expression of the trade-off function for shuffling models that outperforms the most up-to-date results based on $(\epsilon,\delta)$-DP. Moreover, we investigate the effects of random initialization on the privacy of one-iteration DP-GD. Our numerical computations of the trade-off function indicate that random initialization can enhance the privacy of DP-GD. Our analysis of $f$-DP guarantees for these mixture mechanisms relies on an inequality for trade-off functions introduced in this paper. This inequality implies the joint convexity of $F$-divergences. Finally, we study an $f$-DP analog of the advanced joint convexity of the hockey-stick divergence related to $(\epsilon,\delta)$-DP and apply it to analyze the privacy of mixture mechanisms.
Initialization Matters: Privacy-Utility Analysis of Overparameterized Neural Networks
Oct 31, 2023We analytically investigate how over-parameterization of models in randomized machine learning algorithms impacts the information leakage about their training data. Specifically, we prove a privacy bound for the KL divergence between model distributions on worst-case neighboring datasets, and explore its dependence on the initialization, width, and depth of fully connected neural networks. We find that this KL privacy bound is largely determined by the expected squared gradient norm relative to model parameters during training. Notably, for the special setting of linearized network, our analysis indicates that the squared gradient norm (and therefore the escalation of privacy loss) is tied directly to the per-layer variance of the initialization distribution. By using this analysis, we demonstrate that privacy bound improves with increasing depth under certain initializations (LeCun and Xavier), while degrades with increasing depth under other initializations (He and NTK). Our work reveals a complex interplay between privacy and depth that depends on the chosen initialization distribution. We further prove excess empirical risk bounds under a fixed KL privacy budget, and show that the interplay between privacy utility trade-off and depth is similarly affected by the initialization.
Leave-one-out Distinguishability in Machine Learning
Sep 29, 2023



We introduce a new analytical framework to quantify the changes in a machine learning algorithm's output distribution following the inclusion of a few data points in its training set, a notion we define as leave-one-out distinguishability (LOOD). This problem is key to measuring data **memorization** and **information leakage** in machine learning, and the **influence** of training data points on model predictions. We illustrate how our method broadens and refines existing empirical measures of memorization and privacy risks associated with training data. We use Gaussian processes to model the randomness of machine learning algorithms, and validate LOOD with extensive empirical analysis of information leakage using membership inference attacks. Our theoretical framework enables us to investigate the causes of information leakage and where the leakage is high. For example, we analyze the influence of activation functions, on data memorization. Additionally, our method allows us to optimize queries that disclose the most significant information about the training data in the leave-one-out setting. We illustrate how optimal queries can be used for accurate **reconstruction** of training data.
Share Your Representation Only: Guaranteed Improvement of the Privacy-Utility Tradeoff in Federated Learning
Sep 11, 2023



Repeated parameter sharing in federated learning causes significant information leakage about private data, thus defeating its main purpose: data privacy. Mitigating the risk of this information leakage, using state of the art differentially private algorithms, also does not come for free. Randomized mechanisms can prevent convergence of models on learning even the useful representation functions, especially if there is more disagreement between local models on the classification functions (due to data heterogeneity). In this paper, we consider a representation federated learning objective that encourages various parties to collaboratively refine the consensus part of the model, with differential privacy guarantees, while separately allowing sufficient freedom for local personalization (without releasing it). We prove that in the linear representation setting, while the objective is non-convex, our proposed new algorithm \DPFEDREP\ converges to a ball centered around the \emph{global optimal} solution at a linear rate, and the radius of the ball is proportional to the reciprocal of the privacy budget. With this novel utility analysis, we improve the SOTA utility-privacy trade-off for this problem by a factor of $\sqrt{d}$, where $d$ is the input dimension. We empirically evaluate our method with the image classification task on CIFAR10, CIFAR100, and EMNIST, and observe a significant performance improvement over the prior work under the same small privacy budget. The code can be found in this link: https://github.com/shenzebang/CENTAUR-Privacy-Federated-Representation-Learning.
Differentially Private Learning Needs Hidden State (Or Much Faster Convergence)
Mar 10, 2022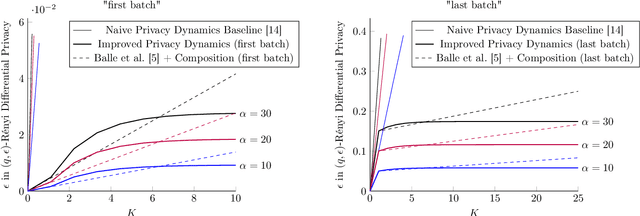



Differential privacy analysis of randomized learning algorithms typically relies on composition theorems, where the implicit assumption is that the internal state of the iterative algorithm is revealed to the adversary. However, by assuming hidden states for DP algorithms (when only the last-iterate is observable), recent works prove a converging privacy bound for noisy gradient descent (on strongly convex smooth loss function) that is significantly smaller than composition bounds after $O(1/\text{step-size})$ epochs. In this paper, we extend this hidden-state analysis to the noisy mini-batch stochastic gradient descent algorithms on strongly-convex smooth loss functions. We prove converging R\'enyi DP bounds under various mini-batch sampling schemes, such as "shuffle and partition" (which are used in practical implementations of DP-SGD) and "sampling without replacement". We prove that, in these settings, our privacy bound is much smaller than the composition bound for training with a large number of iterations (which is the case for learning from high-dimensional data). Our converging privacy analysis, thus, shows that differentially private learning, with a tight bound, needs hidden state privacy analysis or a fast convergence. To complement our theoretical results, we run experiment on training classification models on MNIST, FMNIST and CIFAR-10 datasets, and observe a better accuracy given fixed privacy budgets, under the hidden-state analysis.
Enhanced Membership Inference Attacks against Machine Learning Models
Nov 18, 2021
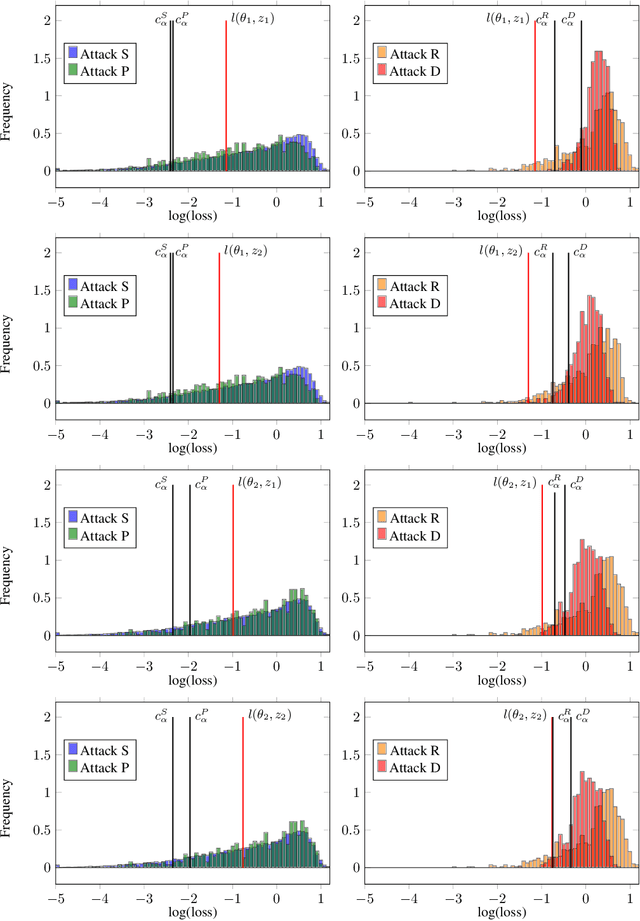
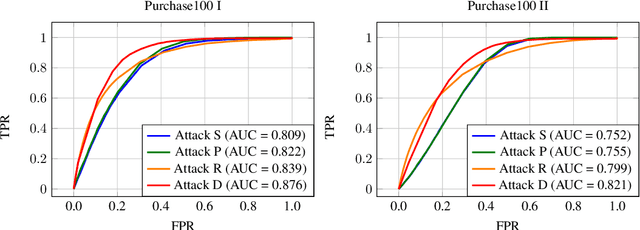

How much does a given trained model leak about each individual data record in its training set? Membership inference attacks are used as an auditing tool to quantify the private information that a model leaks about the individual data points in its training set. Membership inference attacks are influenced by different uncertainties that an attacker has to resolve about training data, the training algorithm, and the underlying data distribution. Thus attack success rates, of many attacks in the literature, do not precisely capture the information leakage of models about their data, as they also reflect other uncertainties that the attack algorithm has. In this paper, we explain the implicit assumptions and also the simplifications made in prior work using the framework of hypothesis testing. We also derive new attack algorithms from the framework that can achieve a high AUC score while also highlighting the different factors that affect their performance. Our algorithms capture a very precise approximation of privacy loss in models, and can be used as a tool to perform an accurate and informed estimation of privacy risk in machine learning models. We provide a thorough empirical evaluation of our attack strategies on various machine learning tasks and benchmark datasets.