 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Political Bias in Large Language Models using Parliamentary Voting Records
Jan 13, 2026As large language models (LLMs) become deeply embedded in digital platforms and decision-making systems, concerns about their political biases have grown. While substantial work has examined social biases such as gender and race, systematic studies of political bias remain limited, despite their direct societal impact. This paper introduces a general methodology for constructing political bias benchmarks by aligning model-generated voting predictions with verified parliamentary voting records. We instantiate this methodology in three national case studies: PoliBiasNL (2,701 Dutch parliamentary motions and votes from 15 political parties), PoliBiasNO (10,584 motions and votes from 9 Norwegian parties), and PoliBiasES (2,480 motions and votes from 10 Spanish parties). Across these benchmarks, we assess ideological tendencies and political entity bias in LLM behavior. As part of our evaluation framework, we also propose a method to visualize the ideology of LLMs and political parties in a shared two-dimensional CHES (Chapel Hill Expert Survey) space by linking their voting-based positions to the CHES dimensions, enabling direct and interpretable comparisons between models and real-world political actors. Our experiments reveal fine-grained ideological distinctions: state-of-the-art LLMs consistently display left-leaning or centrist tendencies, alongside clear negative biases toward right-conservative parties. These findings highlight the value of transparent, cross-national evaluation grounded in real parliamentary behavior for understanding and auditing political bias in modern LLMs.
The 2020 United States Decennial Census Is More Private Than You (Might) Think
Oct 11, 2024The U.S. Decennial Census serves as the foundation for many high-profile policy decision-making processes, including federal funding allocation and redistricting. In 2020, the Census Bureau adopted differential privacy to protect the confidentiality of individual responses through a disclosure avoidance system that injects noise into census data tabulations. The Bureau subsequently posed an open question: Could sharper privacy guarantees be obtained for the 2020 U.S. Census compared to their published guarantees, or equivalently, had the nominal privacy budgets been fully utilized? In this paper, we affirmatively address this open problem by demonstrating that between 8.50% and 13.76% of the privacy budget for the 2020 U.S. Census remains unused for each of the eight geographical levels, from the national level down to the block level. This finding is made possible through our precise tracking of privacy losses using $f$-differential privacy, applied to the composition of private queries across various geographical levels. Our analysis indicates that the Census Bureau introduced unnecessarily high levels of injected noise to achieve the claimed privacy guarantee for the 2020 U.S. Census. Consequently, our results enable the Bureau to reduce noise variances by 15.08% to 24.82% while maintaining the same privacy budget for each geographical level, thereby enhancing the accuracy of privatized census statistics. We empirically demonstrate that reducing noise injection into census statistics mitigates distortion caused by privacy constraints in downstream applications of private census data, illustrated through a study examining the relationship between earnings and education.
Neural Collapse Meets Differential Privacy: Curious Behaviors of NoisyGD with Near-perfect Representation Learning
May 16, 2024A recent study by De et al. (2022) has reported that large-scale representation learning through pre-training on a public dataset significantly enhances differentially private (DP) learning in downstream tasks, despite the high dimensionality of the feature space. To theoretically explain this phenomenon, we consider the setting of a layer-peeled model in representation learning, which results in interesting phenomena related to learned features in deep learning and transfer learning, known as Neural Collapse (NC). Within the framework of NC, we establish an error bound indicating that the misclassification error is independent of dimension when the distance between actual features and the ideal ones is smaller than a threshold. Additionally, the quality of the features in the last layer is empirically evaluated under different pre-trained models within the framework of NC, showing that a more powerful transformer leads to a better feature representation. Furthermore, we reveal that DP fine-tuning is less robust compared to fine-tuning without DP, particularly in the presence of perturbations. These observations are supported by both theoretical analyses and experimental evaluation. Moreover, to enhance the robustness of DP fine-tuning, we suggest several strategies, such as feature normalization or employing dimension reduction methods like Principal Component Analysis (PCA). Empirically, we demonstrate a significant improvement in testing accuracy by conducting PCA on the last-layer features.
Unified Enhancement of Privacy Bounds for Mixture Mechanisms via $f$-Differential Privacy
Nov 01, 2023Differentially private (DP) machine learning algorithms incur many sources of randomness, such as random initialization, random batch subsampling, and shuffling. However, such randomness is difficult to take into account when proving differential privacy bounds because it induces mixture distributions for the algorithm's output that are difficult to analyze. This paper focuses on improving privacy bounds for shuffling models and one-iteration differentially private gradient descent (DP-GD) with random initializations using $f$-DP. We derive a closed-form expression of the trade-off function for shuffling models that outperforms the most up-to-date results based on $(\epsilon,\delta)$-DP. Moreover, we investigate the effects of random initialization on the privacy of one-iteration DP-GD. Our numerical computations of the trade-off function indicate that random initialization can enhance the privacy of DP-GD. Our analysis of $f$-DP guarantees for these mixture mechanisms relies on an inequality for trade-off functions introduced in this paper. This inequality implies the joint convexity of $F$-divergences. Finally, we study an $f$-DP analog of the advanced joint convexity of the hockey-stick divergence related to $(\epsilon,\delta)$-DP and apply it to analyze the privacy of mixture mechanisms.
Statistical Theory of Differentially Private Marginal-based Data Synthesis Algorithms
Jan 25, 2023Marginal-based methods achieve promising performance in the synthetic data competition hosted by the National Institute of Standards and Technology (NIST). To deal with high-dimensional data, the distribution of synthetic data is represented by a probabilistic graphical model (e.g., a Bayesian network), while the raw data distribution is approximated by a collection of low-dimensional marginals. Differential privacy (DP) is guaranteed by introducing random noise to each low-dimensional marginal distribution. Despite its promising performance in practice, the statistical properties of marginal-based methods are rarely studied in the literature. In this paper, we study DP data synthesis algorithms based on Bayesian networks (BN) from a statistical perspective. We establish a rigorous accuracy guarantee for BN-based algorithms, where the errors are measured by the total variation (TV) distance or the $L^2$ distance. Related to downstream machine learning tasks, an upper bound for the utility error of the DP synthetic data is also derived. To complete the picture, we establish a lower bound for TV accuracy that holds for every $\epsilon$-DP synthetic data generator.
IPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022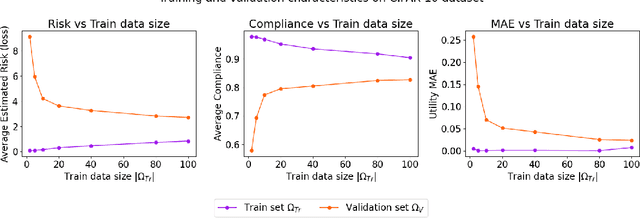
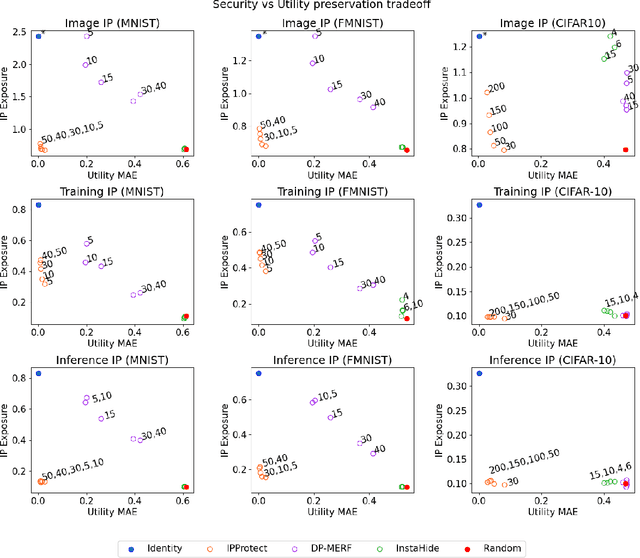
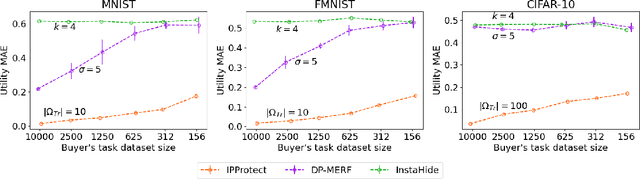
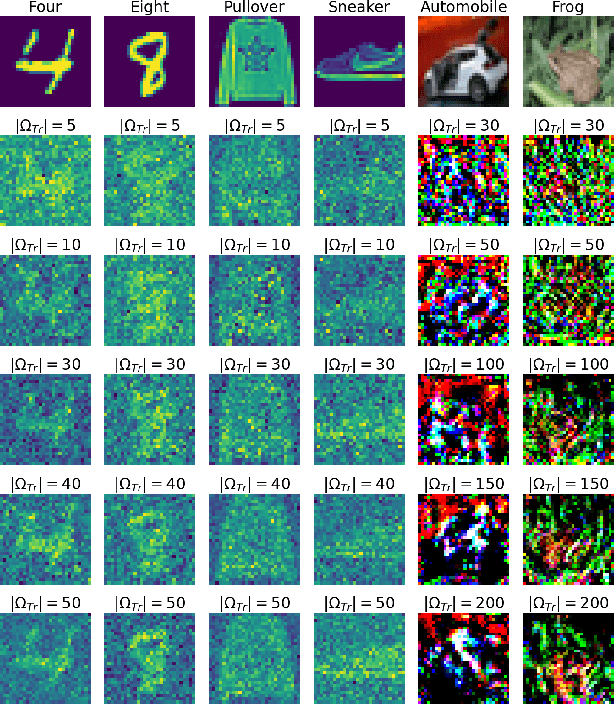
Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.
Human Emotional Facial Expression Recognition
Mar 28, 2018
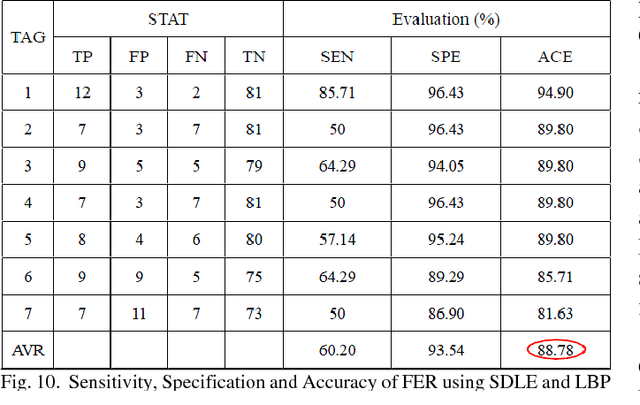
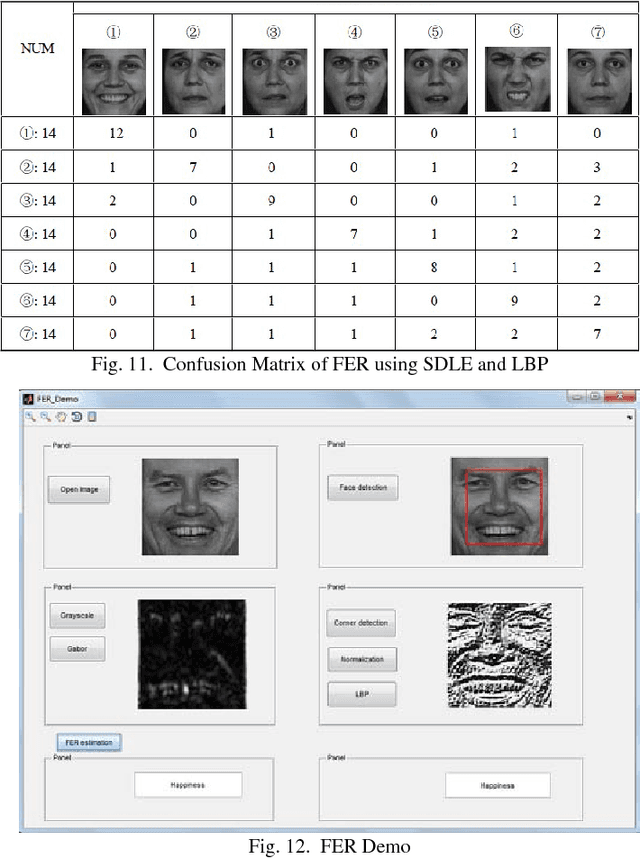

An automatic Facial Expression Recognition (FER) model with Adaboost face detector, feature selection based on manifold learning and synergetic prototype based classifier has been proposed. Improved feature selection method and proposed classifier can achieve favorable effectiveness to performance FER in reasonable processing time.