 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPProtect: protecting the intellectual property of visual datasets during data valuation
Dec 22, 2022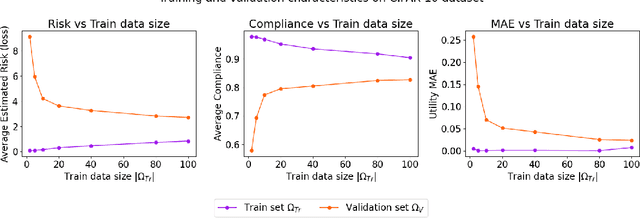
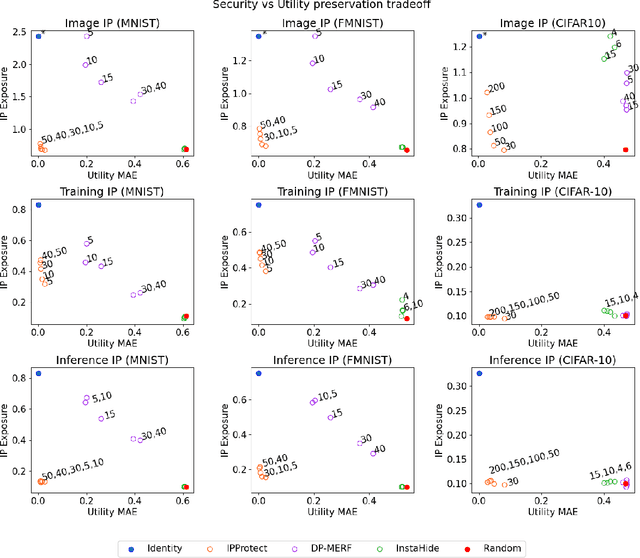
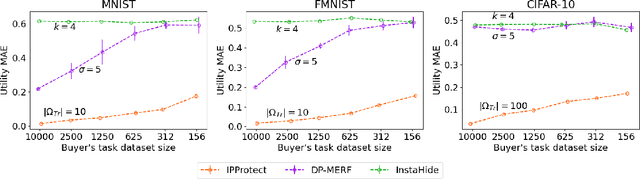
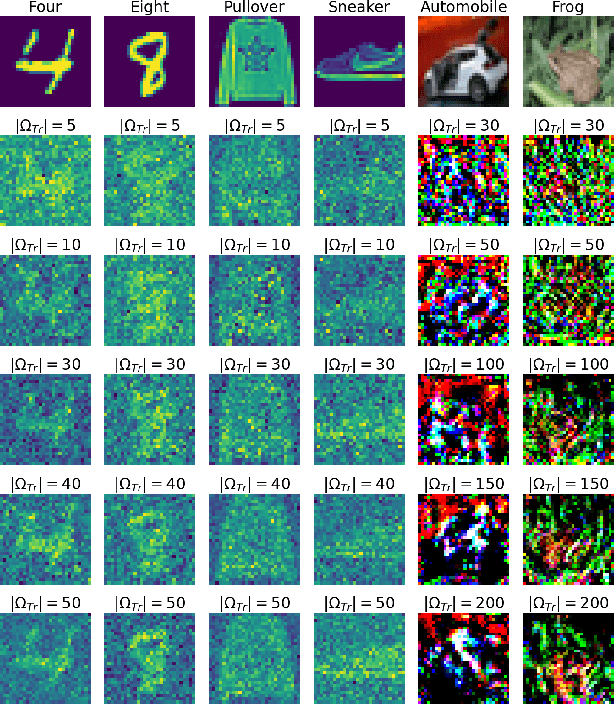
Data trading is essential to accelerate the development of data-driven machine learning pipelines. The central problem in data trading is to estimate the utility of a seller's dataset with respect to a given buyer's machine learning task, also known as data valuation. Typically, data valuation requires one or more participants to share their raw dataset with others, leading to potential risks of intellectual property (IP) violations. In this paper, we tackle the novel task of preemptively protecting the IP of datasets that need to be shared during data valuation. First, we identify and formalize two kinds of novel IP risks in visual datasets: data-item (image) IP and statistical (dataset) IP. Then, we propose a novel algorithm to convert the raw dataset into a sanitized version, that provides resistance to IP violations, while at the same time allowing accurate data valuation. The key idea is to limit the transfer of information from the raw dataset to the sanitized dataset, thereby protecting against potential intellectual property violations. Next, we analyze our method for the likely existence of a solution and immunity against reconstruction attacks. Finally, we conduct extensive experiments on three computer vision datasets demonstrating the advantages of our method in comparison to other baselines.