 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonest-but-Curious Nets: Sensitive Attributes of Private Inputs can be Secretly Coded into the Entropy of Classifiers' Outputs
Paper and Code
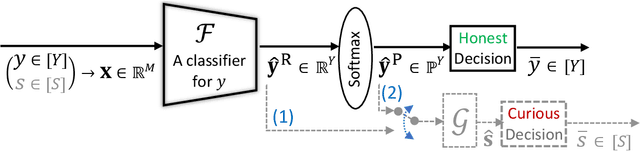
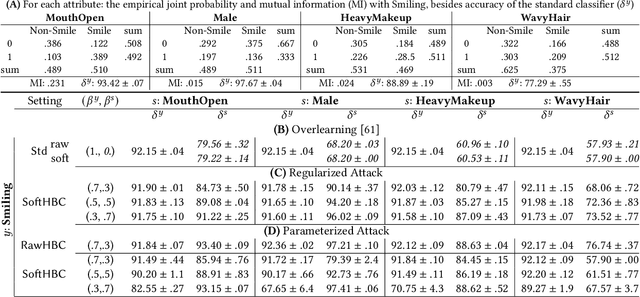
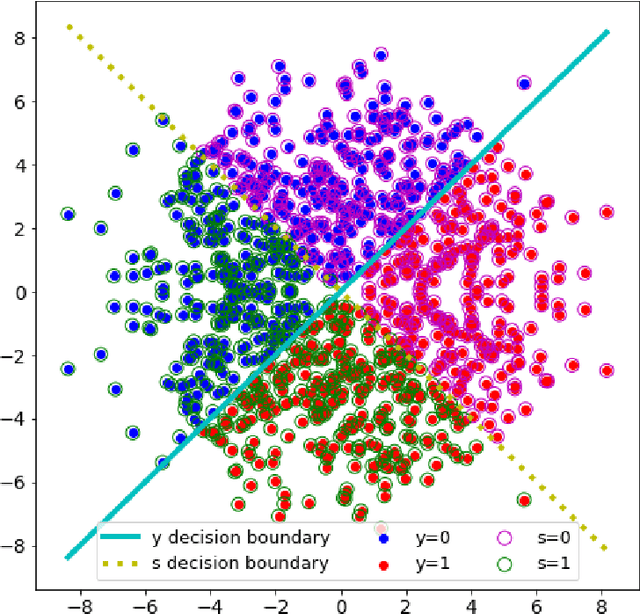
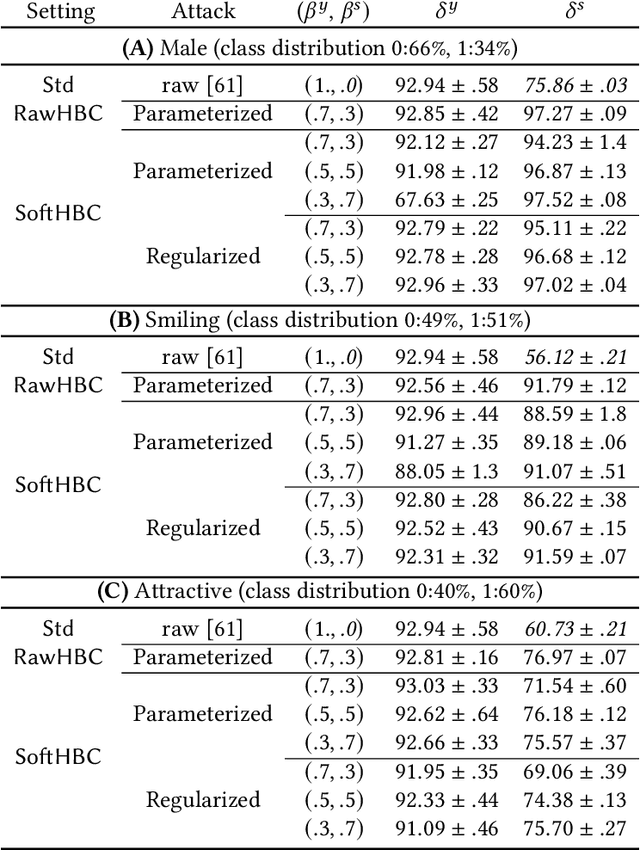
It is known that deep neural networks, trained for the classification of a non-sensitive target attribute, can reveal sensitive attributes of their input data; through features of different granularity extracted by the classifier. We, taking a step forward, show that deep classifiers can be trained to secretly encode a sensitive attribute of users' input data, at inference time, into the classifier's outputs for the target attribute. An attack that works even if users have a white-box view of the classifier, and can keep all internal representations hidden except for the classifier's estimation of the target attribute. We introduce an information-theoretical formulation of such adversaries and present efficient empirical implementations for training honest-but-curious (HBC) classifiers based on this formulation: deep models that can be accurate in predicting the target attribute, but also can utilize their outputs to secretly encode a sensitive attribute. Our evaluations on several tasks in real-world datasets show that a semi-trusted server can build a classifier that is not only perfectly honest but also accurately curious. Our work highlights a vulnerability that can be exploited by malicious machine learning service providers to attack their user's privacy in several seemingly safe scenarios; such as encrypted inferences, computations at the edge, or private knowledge distillation. We conclude by showing the difficulties in distinguishing between standard and HBC classifiers and discussing potential proactive defenses against this vulnerability of deep classifiers.