 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of slow features for Data Efficient Regression
Paper and Code
Dec 11, 2020
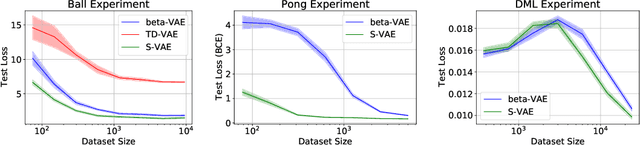
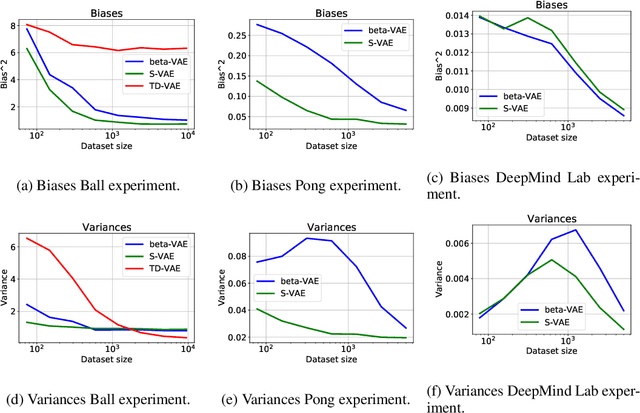
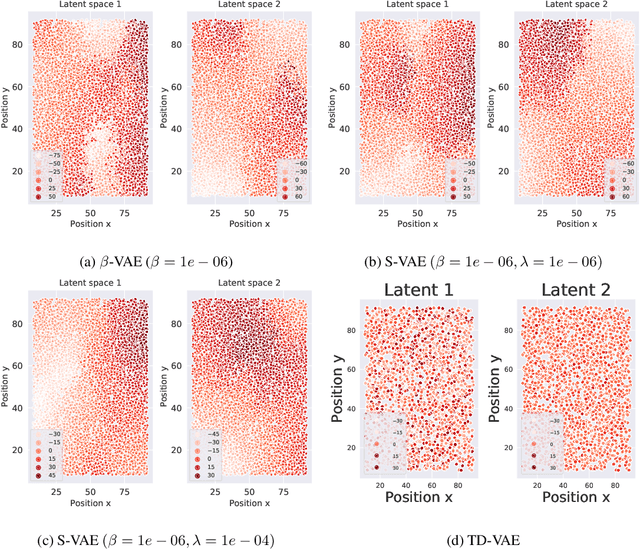
Research in computational neuroscience suggests that the human brain's unparalleled data efficiency is a result of highly efficient mechanisms to extract and organize slowly changing high level features from continuous sensory inputs. In this paper, we apply this slowness principle to a state of the art representation learning method with the goal of performing data efficient learning of down-stream regression tasks. To this end, we propose the slow variational autoencoder (S-VAE), an extension to the $\beta$-VAE which applies a temporal similarity constraint to the latent representations. We empirically compare our method to the $\beta$-VAE and the Temporal Difference VAE (TD-VAE), a state-of-the-art method for next frame prediction in latent space with temporal abstraction. We evaluate the three methods against their data-efficiency on down-stream tasks using a synthetic 2D ball tracking dataset, a dataset from a reinforcent learning environment and a dataset generated using the DeepMind Lab environment. In all tasks, the proposed method outperformed the baselines both with dense and especially sparse labeled data. The S-VAE achieved similar or better performance compared to the baselines with $20\%$ to $93\%$ less data.