 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Human Bias and Knowledge to guide ML models during Training
Nov 19, 2022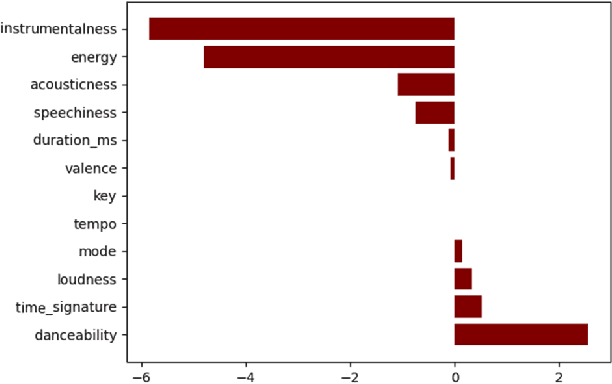
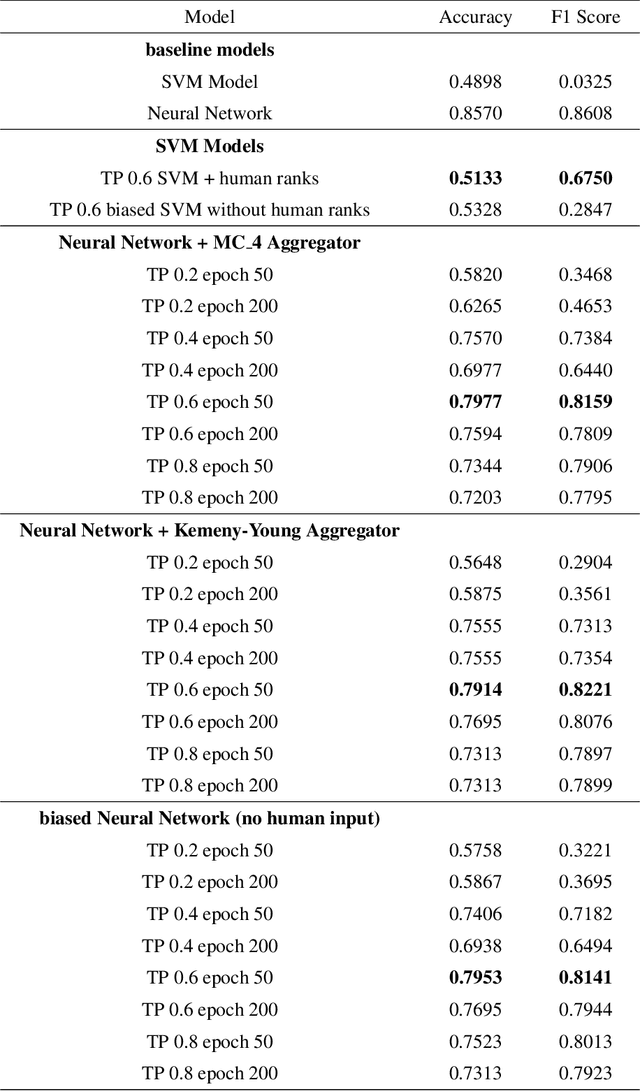
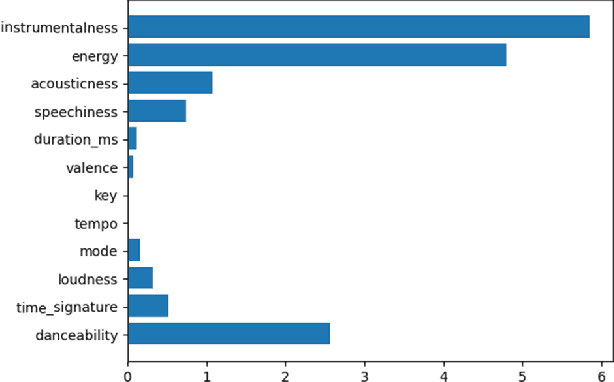
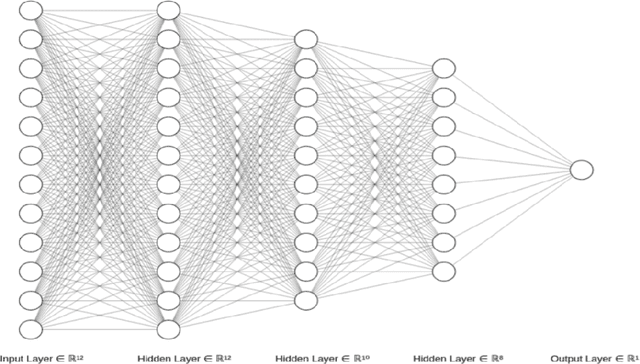
This paper discusses a crowdsourcing based method that we designed to quantify the importance of different attributes of a dataset in determining the outcome of a classification problem. This heuristic, provided by humans acts as the initial weight seed for machine learning models and guides the model towards a better optimal during the gradient descent process. Often times when dealing with data, it is not uncommon to deal with skewed datasets, that over represent items of certain classes, while underrepresenting the rest. Skewed datasets may lead to unforeseen issues with models such as learning a biased function or overfitting. Traditional data augmentation techniques in supervised learning include oversampling and training with synthetic data. We introduce an experimental approach to dealing with such unbalanced datasets by including humans in the training process. We ask humans to rank the importance of features of the dataset, and through rank aggregation, determine the initial weight bias for the model. We show that collective human bias can allow ML models to learn insights about the true population instead of the biased sample. In this paper, we use two rank aggregator methods Kemeny Young and the Markov Chain aggregator to quantify human opinion on importance of features. This work mainly tests the effectiveness of human knowledge on binary classification (Popular vs Not-popular) problems on two ML models: Deep Neural Networks and Support Vector Machines. This approach considers humans as weak learners and relies on aggregation to offset individual biases and domain unfamiliarity.