 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo-NEC: Enhancing Stereo Visual-Inertial SLAM Initialization with Normal Epipolar Constraints
Mar 12, 2024



We propose an accurate and robust initialization approach for stereo visual-inertial SLAM systems. Unlike the current state-of-the-art method, which heavily relies on the accuracy of a pure visual SLAM system to estimate inertial variables without updating camera poses, potentially compromising accuracy and robustness, our approach offers a different solution. We realize the crucial impact of precise gyroscope bias estimation on rotation accuracy. This, in turn, affects trajectory accuracy due to the accumulation of translation errors. To address this, we first independently estimate the gyroscope bias and use it to formulate a maximum a posteriori problem for further refinement. After this refinement, we proceed to update the rotation estimation by performing IMU integration with gyroscope bias removed from gyroscope measurements. We then leverage robust and accurate rotation estimates to enhance translation estimation via 3-DoF bundle adjustment. Moreover, we introduce a novel approach for determining the success of the initialization by evaluating the residual of the normal epipolar constraint. Extensive evaluations on the EuRoC dataset illustrate that our method excels in accuracy and robustness. It outperforms ORB-SLAM3, the current leading stereo visual-inertial initialization method, in terms of absolute trajectory error and relative rotation error, while maintaining competitive computational speed. Notably, even with 5 keyframes for initialization, our method consistently surpasses the state-of-the-art approach using 10 keyframes in rotation accuracy.
NARUTO: Neural Active Reconstruction from Uncertain Target Observations
Feb 29, 2024We present NARUTO, a neural active reconstruction system that combines a hybrid neural representation with uncertainty learning, enabling high-fidelity surface reconstruction. Our approach leverages a multi-resolution hash-grid as the mapping backbone, chosen for its exceptional convergence speed and capacity to capture high-frequency local features.The centerpiece of our work is the incorporation of an uncertainty learning module that dynamically quantifies reconstruction uncertainty while actively reconstructing the environment. By harnessing learned uncertainty, we propose a novel uncertainty aggregation strategy for goal searching and efficient path planning. Our system autonomously explores by targeting uncertain observations and reconstructs environments with remarkable completeness and fidelity. We also demonstrate the utility of this uncertainty-aware approach by enhancing SOTA neural SLAM systems through an active ray sampling strategy. Extensive evaluations of NARUTO in various environments, using an indoor scene simulator, confirm its superior performance and state-of-the-art status in active reconstruction, as evidenced by its impressive results on benchmark datasets like Replica and MP3D.
PlanarNeRF: Online Learning of Planar Primitives with Neural Radiance Fields
Dec 30, 2023Identifying spatially complete planar primitives from visual data is a crucial task in computer vision. Prior methods are largely restricted to either 2D segment recovery or simplifying 3D structures, even with extensive plane annotations. We present PlanarNeRF, a novel framework capable of detecting dense 3D planes through online learning. Drawing upon the neural field representation, PlanarNeRF brings three major contributions. First, it enhances 3D plane detection with concurrent appearance and geometry knowledge. Second, a lightweight plane fitting module is proposed to estimate plane parameters. Third, a novel global memory bank structure with an update mechanism is introduced, ensuring consistent cross-frame correspondence. The flexible architecture of PlanarNeRF allows it to function in both 2D-supervised and self-supervised solutions, in each of which it can effectively learn from sparse training signals, significantly improving training efficiency. Through extensive experiments, we demonstrate the effectiveness of PlanarNeRF in various scenarios and remarkable improvement over existing works.
CVRecon: Rethinking 3D Geometric Feature Learning For Neural Reconstruction
Apr 28, 2023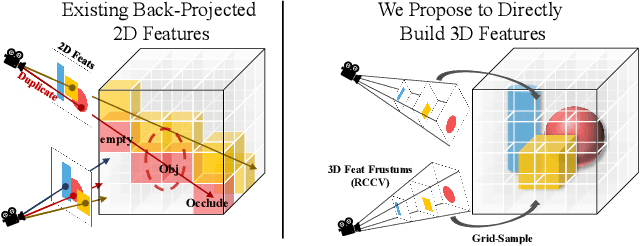



Recent advances in neural reconstruction using posed image sequences have made remarkable progress. However, due to the lack of depth information, existing volumetric-based techniques simply duplicate 2D image features of the object surface along the entire camera ray. We contend this duplication introduces noise in empty and occluded spaces, posing challenges for producing high-quality 3D geometry. Drawing inspiration from traditional multi-view stereo methods, we propose an end-to-end 3D neural reconstruction framework CVRecon, designed to exploit the rich geometric embedding in the cost volumes to facilitate 3D geometric feature learning. Furthermore, we present Ray-contextual Compensated Cost Volume (RCCV), a novel 3D geometric feature representation that encodes view-dependent information with improved integrity and robustness. Through comprehensive experiments, we demonstrate that our approach significantly improves the reconstruction quality in various metrics and recovers clear fine details of the 3D geometries. Our extensive ablation studies provide insights into the development of effective 3D geometric feature learning schemes. Project page: https://cvrecon.ziyue.cool/
Disentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth
Mar 29, 2022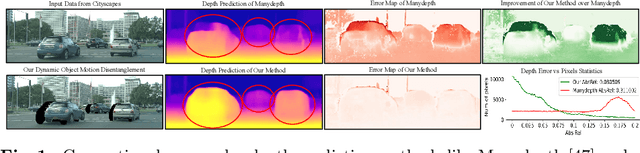
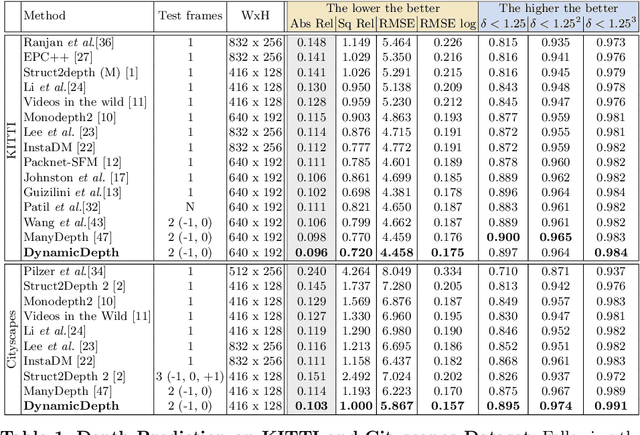
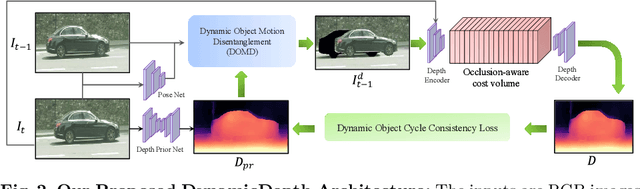
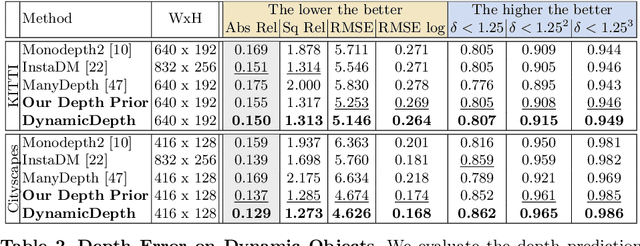
Conventional self-supervised monocular depth prediction methods are based on a static environment assumption, which leads to accuracy degradation in dynamic scenes due to the mismatch and occlusion problems introduced by object motions. Existing dynamic-object-focused methods only partially solved the mismatch problem at the training loss level. In this paper, we accordingly propose a novel multi-frame monocular depth prediction method to solve these problems at both the prediction and supervision loss levels. Our method, called DynamicDepth, is a new framework trained via a self-supervised cycle consistent learning scheme. A Dynamic Object Motion Disentanglement (DOMD) module is proposed to disentangle object motions to solve the mismatch problem. Moreover, novel occlusion-aware Cost Volume and Re-projection Loss are designed to alleviate the occlusion effects of object motions. Extensive analyses and experiments on the Cityscapes and KITTI datasets show that our method significantly outperforms the state-of-the-art monocular depth prediction methods, especially in the areas of dynamic objects. Our code will be made publicly available.
Advancing Self-supervised Monocular Depth Learning with Sparse LiDAR
Sep 21, 2021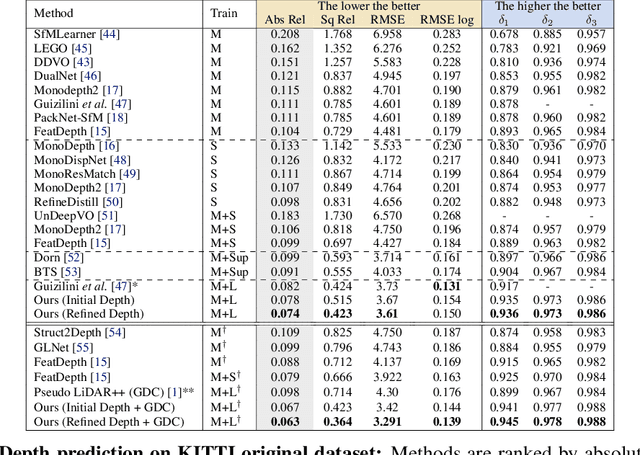
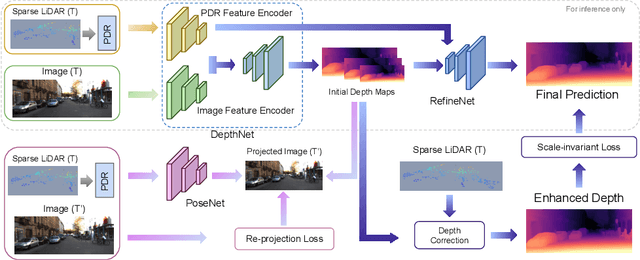
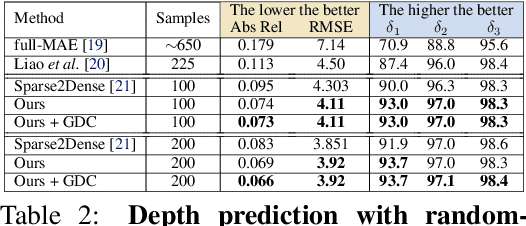
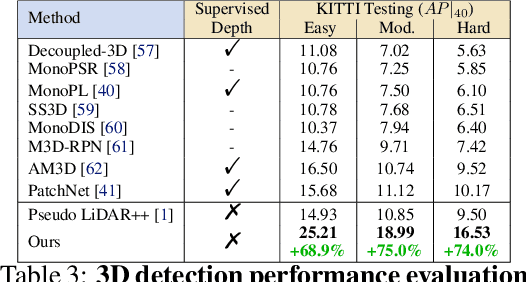
Self-supervised monocular depth prediction provides a cost-effective solution to obtain the 3D location of each pixel. However, the existing approaches usually lead to unsatisfactory accuracy, which is critical for autonomous robots. In this paper, we propose a novel two-stage network to advance the self-supervised monocular dense depth learning by leveraging low-cost sparse (e.g. 4-beam) LiDAR. Unlike the existing methods that use sparse LiDAR mainly in a manner of time-consuming iterative post-processing, our model fuses monocular image features and sparse LiDAR features to predict initial depth maps. Then, an efficient feed-forward refine network is further designed to correct the errors in these initial depth maps in pseudo-3D space with real-time performance. Extensive experiments show that our proposed model significantly outperforms all the state-of-the-art self-supervised methods, as well as the sparse-LiDAR-based methods on both self-supervised monocular depth prediction and completion tasks. With the accurate dense depth prediction, our model outperforms the state-of-the-art sparse-LiDAR-based method (Pseudo-LiDAR++) by more than 68% for the downstream task monocular 3D object detection on the KITTI Leaderboard.
Model-based Decision Making with Imagination for Autonomous Parking
Aug 25, 2021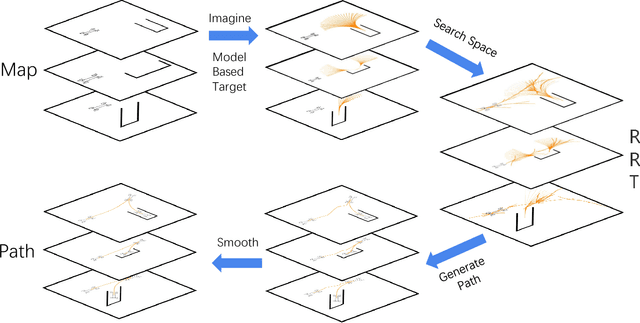
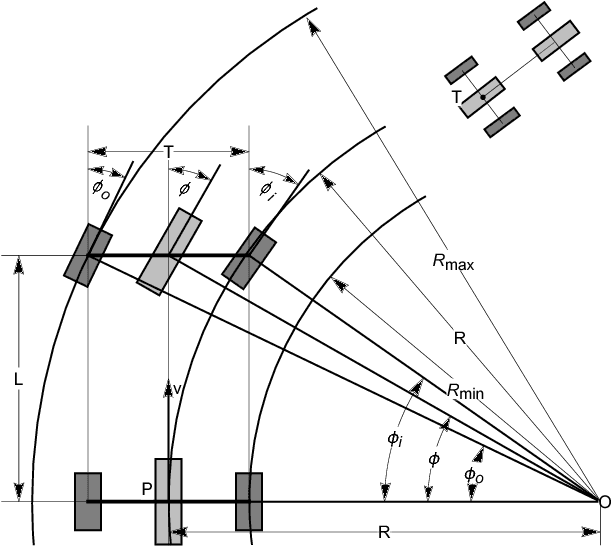
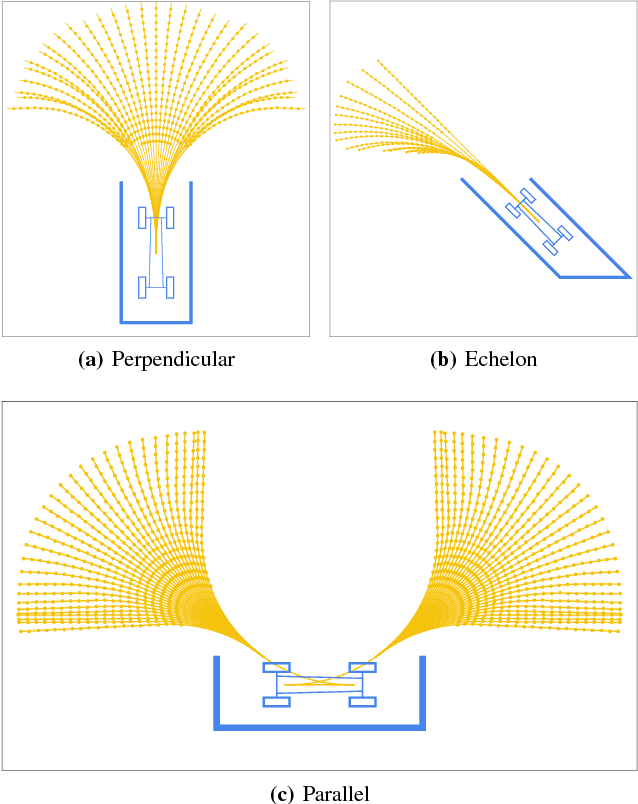
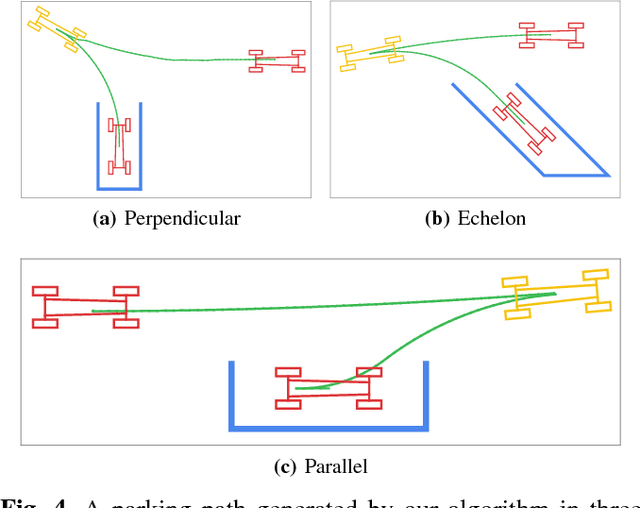
Autonomous parking technology is a key concept within autonomous driving research. This paper will propose an imaginative autonomous parking algorithm to solve issues concerned with parking. The proposed algorithm consists of three parts: an imaginative model for anticipating results before parking, an improved rapid-exploring random tree (RRT) for planning a feasible trajectory from a given start point to a parking lot, and a path smoothing module for optimizing the efficiency of parking tasks. Our algorithm is based on a real kinematic vehicle model; which makes it more suitable for algorithm application on real autonomous cars. Furthermore, due to the introduction of the imagination mechanism, the processing speed of our algorithm is ten times faster than that of traditional methods, permitting the realization of real-time planning simultaneously. In order to evaluate the algorithm's effectiveness, we have compared our algorithm with traditional RRT, within three different parking scenarios. Ultimately, results show that our algorithm is more stable than traditional RRT and performs better in terms of efficiency and quality.
* Published by IEEE IV 2018