 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Self-supervised Monocular Depth Learning with Sparse LiDAR
Paper and Code
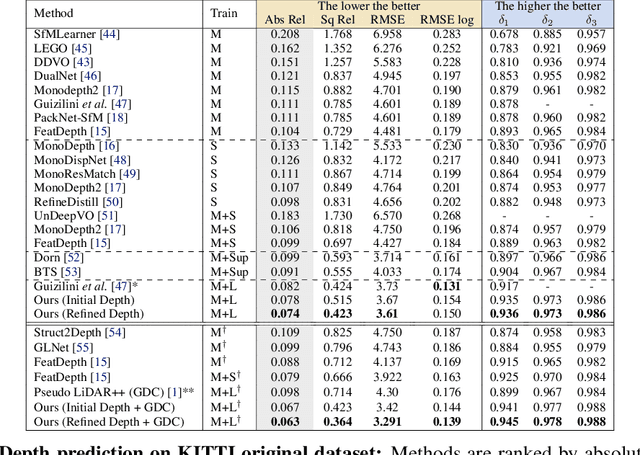
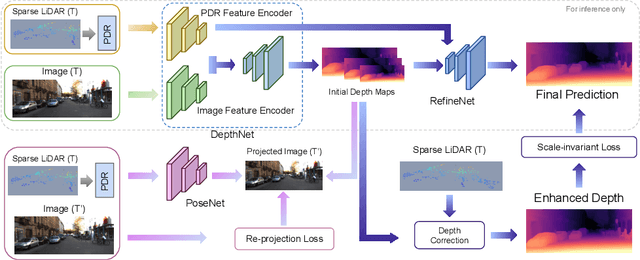
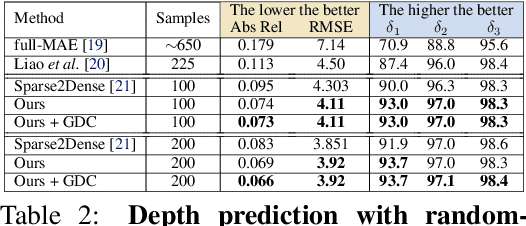
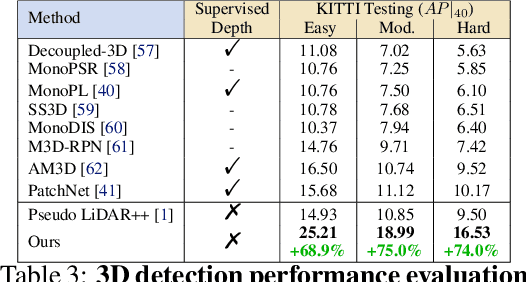
Self-supervised monocular depth prediction provides a cost-effective solution to obtain the 3D location of each pixel. However, the existing approaches usually lead to unsatisfactory accuracy, which is critical for autonomous robots. In this paper, we propose a novel two-stage network to advance the self-supervised monocular dense depth learning by leveraging low-cost sparse (e.g. 4-beam) LiDAR. Unlike the existing methods that use sparse LiDAR mainly in a manner of time-consuming iterative post-processing, our model fuses monocular image features and sparse LiDAR features to predict initial depth maps. Then, an efficient feed-forward refine network is further designed to correct the errors in these initial depth maps in pseudo-3D space with real-time performance. Extensive experiments show that our proposed model significantly outperforms all the state-of-the-art self-supervised methods, as well as the sparse-LiDAR-based methods on both self-supervised monocular depth prediction and completion tasks. With the accurate dense depth prediction, our model outperforms the state-of-the-art sparse-LiDAR-based method (Pseudo-LiDAR++) by more than 68% for the downstream task monocular 3D object detection on the KITTI Leaderboard.