 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Object Motion and Occlusion for Unsupervised Multi-frame Monocular Depth
Mar 29, 2022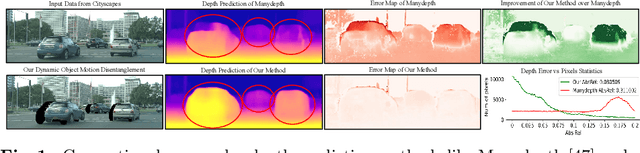
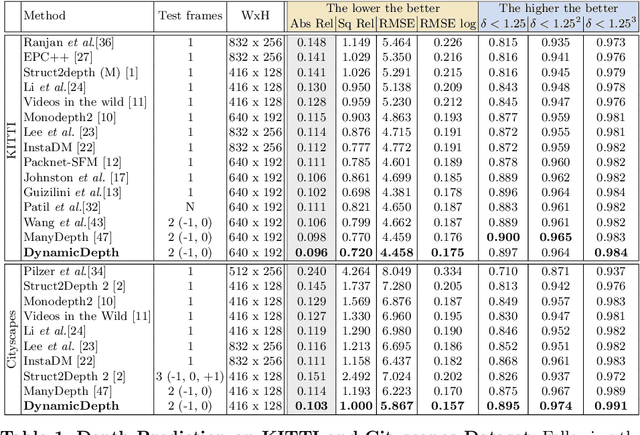
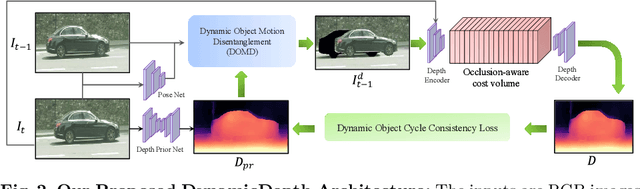
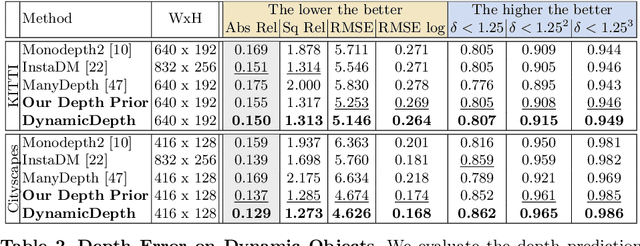
Conventional self-supervised monocular depth prediction methods are based on a static environment assumption, which leads to accuracy degradation in dynamic scenes due to the mismatch and occlusion problems introduced by object motions. Existing dynamic-object-focused methods only partially solved the mismatch problem at the training loss level. In this paper, we accordingly propose a novel multi-frame monocular depth prediction method to solve these problems at both the prediction and supervision loss levels. Our method, called DynamicDepth, is a new framework trained via a self-supervised cycle consistent learning scheme. A Dynamic Object Motion Disentanglement (DOMD) module is proposed to disentangle object motions to solve the mismatch problem. Moreover, novel occlusion-aware Cost Volume and Re-projection Loss are designed to alleviate the occlusion effects of object motions. Extensive analyses and experiments on the Cityscapes and KITTI datasets show that our method significantly outperforms the state-of-the-art monocular depth prediction methods, especially in the areas of dynamic objects. Our code will be made publicly available.
Multimodal Semi-Supervised Learning for 3D Objects
Oct 25, 2021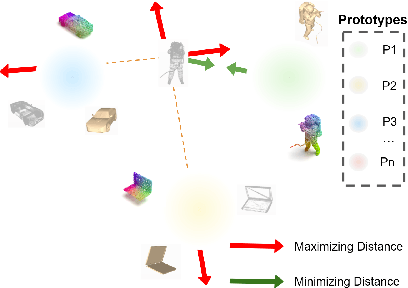
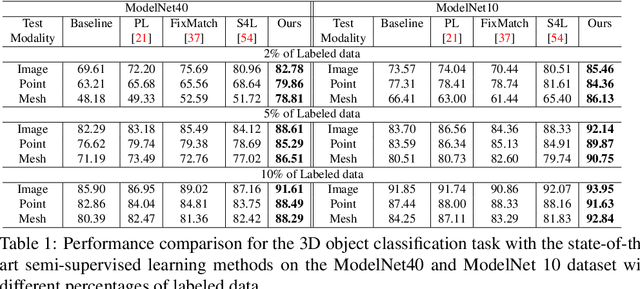
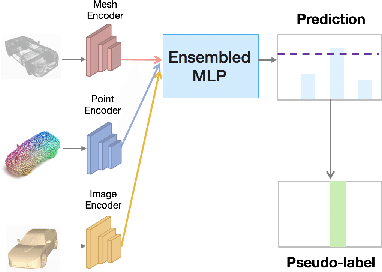
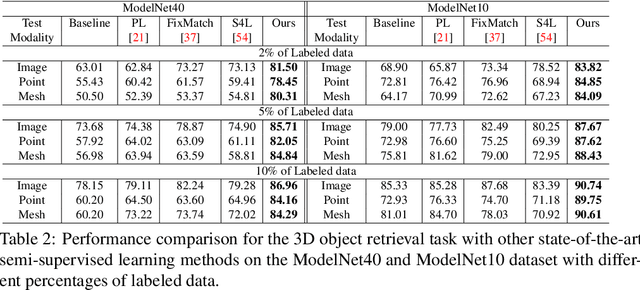
In recent years, semi-supervised learning has been widely explored and shows excellent data efficiency for 2D data. There is an emerging need to improve data efficiency for 3D tasks due to the scarcity of labeled 3D data. This paper explores how the coherence of different modelities of 3D data (e.g. point cloud, image, and mesh) can be used to improve data efficiency for both 3D classification and retrieval tasks. We propose a novel multimodal semi-supervised learning framework by introducing instance-level consistency constraint and a novel multimodal contrastive prototype (M2CP) loss. The instance-level consistency enforces the network to generate consistent representations for multimodal data of the same object regardless of its modality. The M2CP maintains a multimodal prototype for each class and learns features with small intra-class variations by minimizing the feature distance of each object to its prototype while maximizing the distance to the others. Our proposed framework significantly outperforms all the state-of-the-art counterparts for both classification and retrieval tasks by a large margin on the modelNet10 and ModelNet40 datasets.
Incremental Scene Synthesis
Dec 11, 2018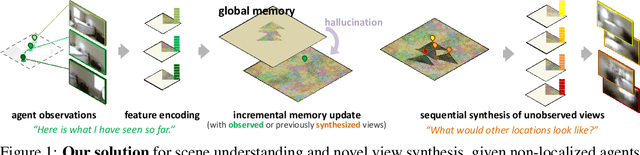
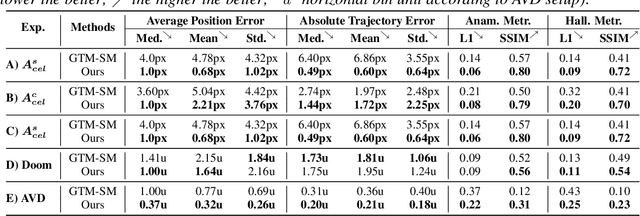
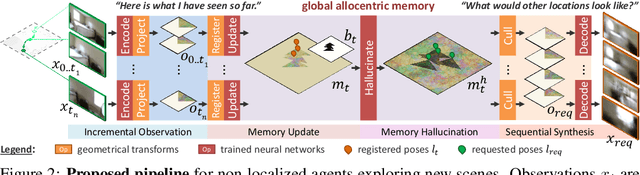
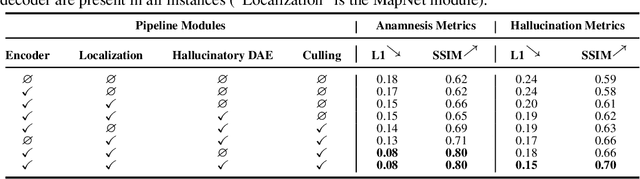
We present a method to incrementally generate complete 2D or 3D scenes with the following properties: (a) it is globally consistent at each step according to a learned scene prior, (b) real observations of an actual scene can be incorporated while observing global consistency, (c) unobserved parts of the scene can be hallucinated locally in consistence with previous observations, hallucinations and global priors, and (d) the hallucinations are statistical in nature, i.e., different consistent scenes can be generated from the same observations. To achieve this, we model the motion of an active agent through a virtual scene, where the agent at each step can either perceive a true (i.e. observed) part of the scene or generate a local hallucination. The latter can be interpreted as the expectation of the agent at this step through the scene and can already be useful, e.g., in autonomous navigation. In the limit of observing real data at each point, our method converges to solving the SLAM problem. In the limit of never observing real data, it samples entirely imagined scenes from the prior distribution. Besides autonomous agents, applications include problems where large data is required for training and testing robust real-world applications, but few data is available, necessitating data generation. We demonstrate efficacy on various 2D as well as preliminary 3D data.