 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Scene Synthesis
Dec 11, 2018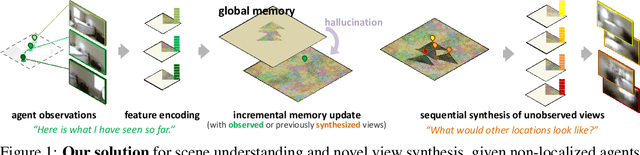
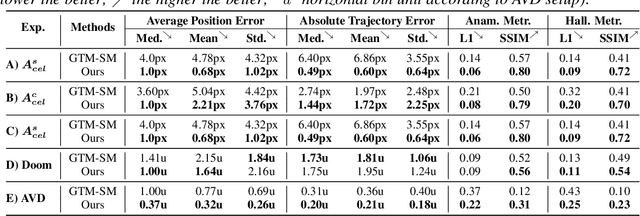
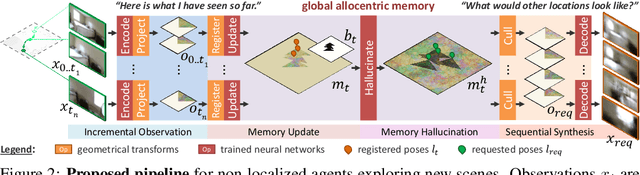
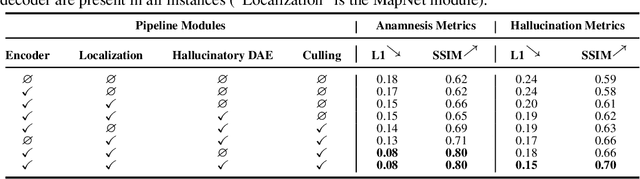
We present a method to incrementally generate complete 2D or 3D scenes with the following properties: (a) it is globally consistent at each step according to a learned scene prior, (b) real observations of an actual scene can be incorporated while observing global consistency, (c) unobserved parts of the scene can be hallucinated locally in consistence with previous observations, hallucinations and global priors, and (d) the hallucinations are statistical in nature, i.e., different consistent scenes can be generated from the same observations. To achieve this, we model the motion of an active agent through a virtual scene, where the agent at each step can either perceive a true (i.e. observed) part of the scene or generate a local hallucination. The latter can be interpreted as the expectation of the agent at this step through the scene and can already be useful, e.g., in autonomous navigation. In the limit of observing real data at each point, our method converges to solving the SLAM problem. In the limit of never observing real data, it samples entirely imagined scenes from the prior distribution. Besides autonomous agents, applications include problems where large data is required for training and testing robust real-world applications, but few data is available, necessitating data generation. We demonstrate efficacy on various 2D as well as preliminary 3D data.
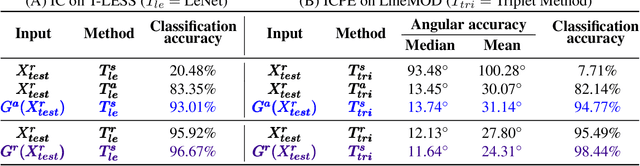
Seeing Beyond Appearance - Mapping Real Images into Geometrical Domains for Unsupervised CAD-based Recognition
Oct 09, 2018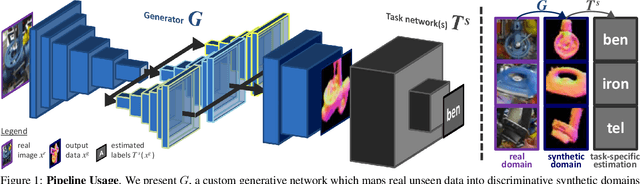

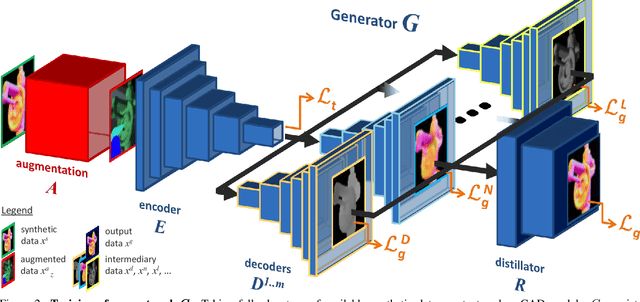

While convolutional neural networks are dominating the field of computer vision, one usually does not have access to the large amount of domain-relevant data needed for their training. It thus became common to use available synthetic samples along domain adaptation schemes to prepare algorithms for the target domain. Tackling this problem from a different angle, we introduce a pipeline to map unseen target samples into the synthetic domain used to train task-specific methods. Denoising the data and retaining only the features these recognition algorithms are familiar with, our solution greatly improves their performance. As this mapping is easier to learn than the opposite one (ie to learn to generate realistic features to augment the source samples), we demonstrate how our whole solution can be trained purely on augmented synthetic data, and still perform better than methods trained with domain-relevant information (eg real images or realistic textures for the 3D models). Applying our approach to object recognition from texture-less CAD data, we present a custom generative network which fully utilizes the purely geometrical information to learn robust features and achieve a more refined mapping for unseen color images.
Keep it Unreal: Bridging the Realism Gap for 2.5D Recognition with Geometry Priors Only
May 24, 2018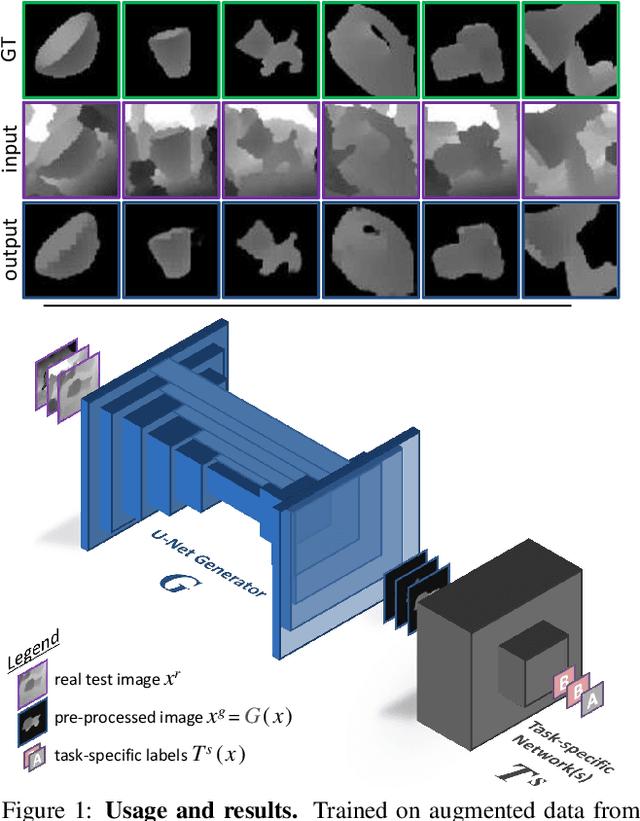
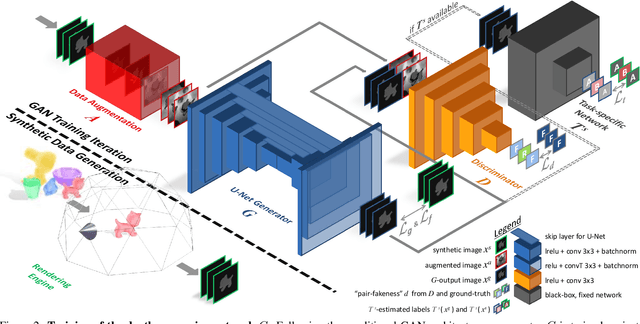
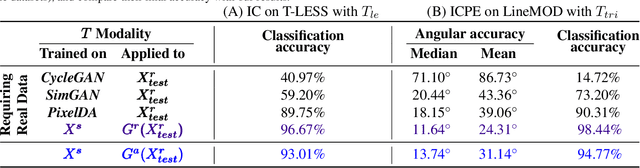
With the increasing availability of large databases of 3D CAD models, depth-based recognition methods can be trained on an uncountable number of synthetically rendered images. However, discrepancies with the real data acquired from various depth sensors still noticeably impede progress. Previous works adopted unsupervised approaches to generate more realistic depth data, but they all require real scans for training, even if unlabeled. This still represents a strong requirement, especially when considering real-life/industrial settings where real training images are hard or impossible to acquire, but texture-less 3D models are available. We thus propose a novel approach leveraging only CAD models to bridge the realism gap. Purely trained on synthetic data, playing against an extensive augmentation pipeline in an unsupervised manner, our generative adversarial network learns to effectively segment depth images and recover the clean synthetic-looking depth information even from partial occlusions. As our solution is not only fully decoupled from the real domains but also from the task-specific analytics, the pre-processed scans can be handed to any kind and number of recognition methods also trained on synthetic data. Through various experiments, we demonstrate how this simplifies their training and consistently enhances their performance, with results on par with the same methods trained on real data, and better than usual approaches doing the reverse mapping.
DepthSynth: Real-Time Realistic Synthetic Data Generation from CAD Models for 2.5D Recognition
Nov 28, 2017
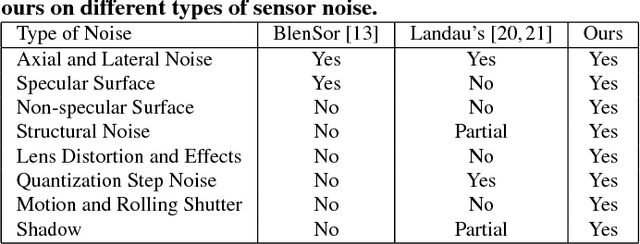
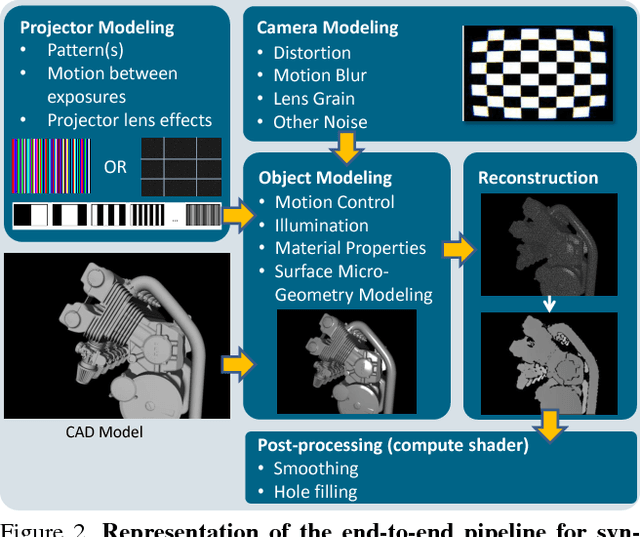

Recent progress in computer vision has been dominated by deep neural networks trained over large amounts of labeled data. Collecting such datasets is however a tedious, often impossible task; hence a surge in approaches relying solely on synthetic data for their training. For depth images however, discrepancies with real scans still noticeably affect the end performance. We thus propose an end-to-end framework which simulates the whole mechanism of these devices, generating realistic depth data from 3D models by comprehensively modeling vital factors e.g. sensor noise, material reflectance, surface geometry. Not only does our solution cover a wider range of sensors and achieve more realistic results than previous methods, assessed through extended evaluation, but we go further by measuring the impact on the training of neural networks for various recognition tasks; demonstrating how our pipeline seamlessly integrates such architectures and consistently enhances their performance.
Ordonnancement d'entités pour la rencontre du web des documents et du web des données
Feb 19, 2016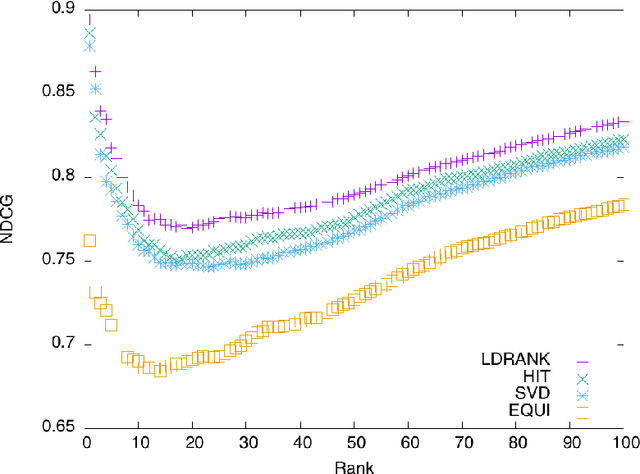


The advances of the Linked Open Data (LOD) initiative are giving rise to a more structured web of data. Indeed, a few datasets act as hubs (e.g., DBpedia) connecting many other datasets. They also made possible new web services for entity detection inside plain text (e.g., DBpedia Spotlight), thus allowing for new applications that will benefit from a combination of the web of documents and the web of data. To ease the emergence of these new use-cases, we propose a query-biased algorithm for the ranking of entities detected inside a web page. Our algorithm combine link analysis with dimensionality reduction. We use crowdsourcing for building a publicly available and reusable dataset on which we compare our algorithm to the state of the art. Finally, we use this algorithm for the construction of semantic snippets for which we evaluate the usability and the usefulness with a crowdsourcing-based approach.
Quality assessment of the MPEG-4 scalable video CODEC
Jun 03, 2009



In this paper, the performance of the emerging MPEG-4 SVC CODEC is evaluated. In the first part, a brief introduction on the subject of quality assessment and the development of the MPEG-4 SVC CODEC is given. After that, the used test methodologies are described in detail, followed by an explanation of the actual test scenarios. The main part of this work concentrates on the performance analysis of the MPEG-4 SVC CODEC - both objective and subjective.