 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Normalization of Confusion Matrices: Methods and Geometric Interpretations
Sep 05, 2025The confusion matrix is a standard tool for evaluating classifiers by providing insights into class-level errors. In heterogeneous settings, its values are shaped by two main factors: class similarity -- how easily the model confuses two classes -- and distribution bias, arising from skewed distributions in the training and test sets. However, confusion matrix values reflect a mix of both factors, making it difficult to disentangle their individual contributions. To address this, we introduce bistochastic normalization using Iterative Proportional Fitting, a generalization of row and column normalization. Unlike standard normalizations, this method recovers the underlying structure of class similarity. By disentangling error sources, it enables more accurate diagnosis of model behavior and supports more targeted improvements. We also show a correspondence between confusion matrix normalizations and the model's internal class representations. Both standard and bistochastic normalizations can be interpreted geometrically in this space, offering a deeper understanding of what normalization reveals about a classifier.
A Weighted Loss Approach to Robust Federated Learning under Data Heterogeneity
Jun 12, 2025Federated learning (FL) is a machine learning paradigm that enables multiple data holders to collaboratively train a machine learning model without sharing their training data with external parties. In this paradigm, workers locally update a model and share with a central server their updated gradients (or model parameters). While FL seems appealing from a privacy perspective, it opens a number of threats from a security perspective as (Byzantine) participants can contribute poisonous gradients (or model parameters) harming model convergence. Byzantine-resilient FL addresses this issue by ensuring that the training proceeds as if Byzantine participants were absent. Towards this purpose, common strategies ignore outlier gradients during model aggregation, assuming that Byzantine gradients deviate more from honest gradients than honest gradients do from each other. However, in heterogeneous settings, honest gradients may differ significantly, making it difficult to distinguish honest outliers from Byzantine ones. In this paper, we introduce the Worker Label Alignement Loss (WoLA), a weighted loss that aligns honest worker gradients despite data heterogeneity, which facilitates the identification of Byzantines' gradients. This approach significantly outperforms state-of-the-art methods in heterogeneous settings. In this paper, we provide both theoretical insights and empirical evidence of its effectiveness.
GRAN is superior to GraphRNN: node orderings, kernel- and graph embeddings-based metrics for graph generators
Jul 13, 2023A wide variety of generative models for graphs have been proposed. They are used in drug discovery, road networks, neural architecture search, and program synthesis. Generating graphs has theoretical challenges, such as isomorphic representations -- evaluating how well a generative model performs is difficult. Which model to choose depending on the application domain? We extensively study kernel-based metrics on distributions of graph invariants and manifold-based and kernel-based metrics in graph embedding space. Manifold-based metrics outperform kernel-based metrics in embedding space. We use these metrics to compare GraphRNN and GRAN, two well-known generative models for graphs, and unveil the influence of node orderings. It shows the superiority of GRAN over GraphRNN - further, our proposed adaptation of GraphRNN with a depth-first search ordering is effective for small-sized graphs. A guideline on good practices regarding dataset selection and node feature initialization is provided. Our work is accompanied by open-source code and reproducible experiments.
PromptORE -- A Novel Approach Towards Fully Unsupervised Relation Extraction
Mar 24, 2023Unsupervised Relation Extraction (RE) aims to identify relations between entities in text, without having access to labeled data during training. This setting is particularly relevant for domain specific RE where no annotated dataset is available and for open-domain RE where the types of relations are a priori unknown. Although recent approaches achieve promising results, they heavily depend on hyperparameters whose tuning would most often require labeled data. To mitigate the reliance on hyperparameters, we propose PromptORE, a ''Prompt-based Open Relation Extraction'' model. We adapt the novel prompt-tuning paradigm to work in an unsupervised setting, and use it to embed sentences expressing a relation. We then cluster these embeddings to discover candidate relations, and we experiment different strategies to automatically estimate an adequate number of clusters. To the best of our knowledge, PromptORE is the first unsupervised RE model that does not need hyperparameter tuning. Results on three general and specific domain datasets show that PromptORE consistently outperforms state-of-the-art models with a relative gain of more than 40% in B 3 , V-measure and ARI. Qualitative analysis also indicates PromptORE's ability to identify semantically coherent clusters that are very close to true relations.
Towards automated feature engineering for credit card fraud detection using multi-perspective HMMs
Sep 03, 2019

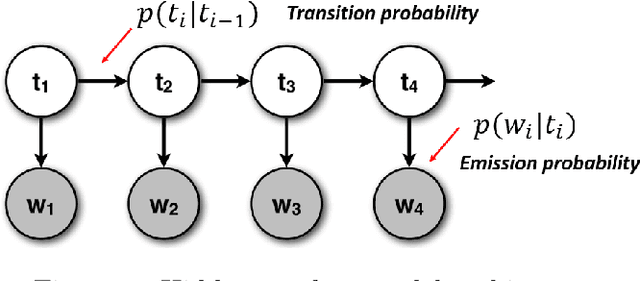

Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However, most studies consider credit card transactions as isolated events and not as a sequence of transactions. In this framework, we model a sequence of credit card transactions from three different perspectives, namely (i) The sequence contains or doesn't contain a fraud (ii) The sequence is obtained by fixing the card-holder or the payment terminal (iii) It is a sequence of spent amount or of elapsed time between the current and previous transactions. Combinations of the three binary perspectives give eight sets of sequences from the (training) set of transactions. Each one of these sequences is modelled with a Hidden Markov Model (HMM). Each HMM associates a likelihood to a transaction given its sequence of previous transactions. These likelihoods are used as additional features in a Random Forest classifier for fraud detection. Our multiple perspectives HMM-based approach offers automated feature engineering to model temporal correlations so as to improve the effectiveness of the classification task and allows for an increase in the detection of fraudulent transactions when combined with the state of the art expert based feature engineering strategy for credit card fraud detection. In extension to previous works, we show that this approach goes beyond ecommerce transactions and provides a robust feature engineering over different datasets, hyperparameters and classifiers. Moreover, we compare strategies to deal with structural missing values.
Dataset shift quantification for credit card fraud detection
Jun 17, 2019

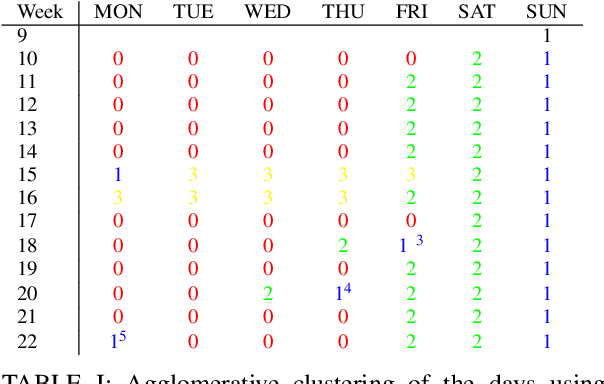
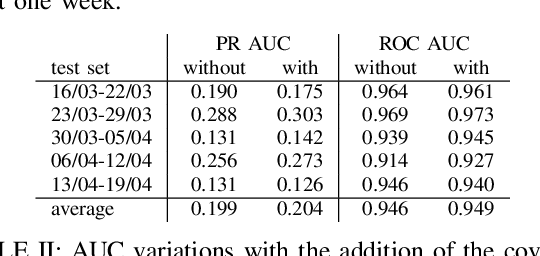
Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However purchase behaviour and fraudster strategies may change over time. This phenomenon is named dataset shift or concept drift in the domain of fraud detection. In this paper, we present a method to quantify day-by-day the dataset shift in our face-to-face credit card transactions dataset (card holder located in the shop) . In practice, we classify the days against each other and measure the efficiency of the classification. The more efficient the classification, the more different the buying behaviour between two days, and vice versa. Therefore, we obtain a distance matrix characterizing the dataset shift. After an agglomerative clustering of the distance matrix, we observe that the dataset shift pattern matches the calendar events for this time period (holidays, week-ends, etc). We then incorporate this dataset shift knowledge in the credit card fraud detection task as a new feature. This leads to a small improvement of the detection.
Multiple perspectives HMM-based feature engineering for credit card fraud detection
May 15, 2019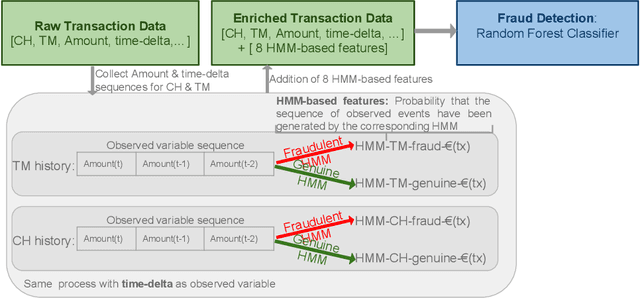
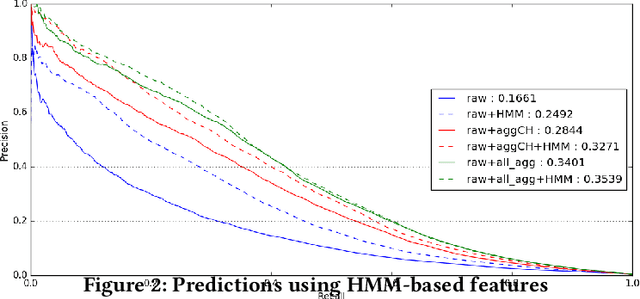
Machine learning and data mining techniques have been used extensively in order to detect credit card frauds. However, most studies consider credit card transactions as isolated events and not as a sequence of transactions. In this article, we model a sequence of credit card transactions from three different perspectives, namely (i) does the sequence contain a Fraud? (ii) Is the sequence obtained by fixing the card-holder or the payment terminal? (iii) Is it a sequence of spent amount or of elapsed time between the current and previous transactions? Combinations of the three binary perspectives give eight sets of sequences from the (training) set of transactions. Each one of these sets is modelled with a Hidden Markov Model (HMM). Each HMM associates a likelihood to a transaction given its sequence of previous transactions. These likelihoods are used as additional features in a Random Forest classifier for fraud detection. This multiple perspectives HMM-based approach enables an automatic feature engineering in order to model the sequential properties of the dataset with respect to the classification task. This strategy allows for a 15% increase in the precision-recall AUC compared to the state of the art feature engineering strategy for credit card fraud detection.
Ordonnancement d'entités pour la rencontre du web des documents et du web des données
Feb 19, 2016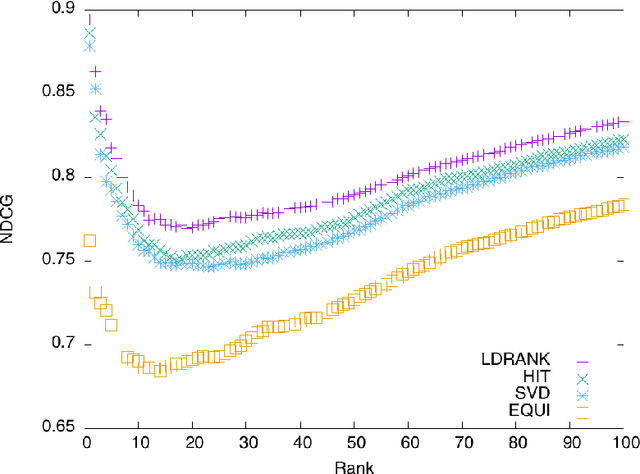


The advances of the Linked Open Data (LOD) initiative are giving rise to a more structured web of data. Indeed, a few datasets act as hubs (e.g., DBpedia) connecting many other datasets. They also made possible new web services for entity detection inside plain text (e.g., DBpedia Spotlight), thus allowing for new applications that will benefit from a combination of the web of documents and the web of data. To ease the emergence of these new use-cases, we propose a query-biased algorithm for the ranking of entities detected inside a web page. Our algorithm combine link analysis with dimensionality reduction. We use crowdsourcing for building a publicly available and reusable dataset on which we compare our algorithm to the state of the art. Finally, we use this algorithm for the construction of semantic snippets for which we evaluate the usability and the usefulness with a crowdsourcing-based approach.